
【标题】Skill-based Meta-Reinforcement Learning
【作者团队】Taewook Nam, Shao-Hua Sun, Karl Pertsch, Sung Ju Hwang, Joseph J Lim
【发表日期】2022.4.25
【论文链接】https://arxiv.org/pdf/2204.11828.pdf
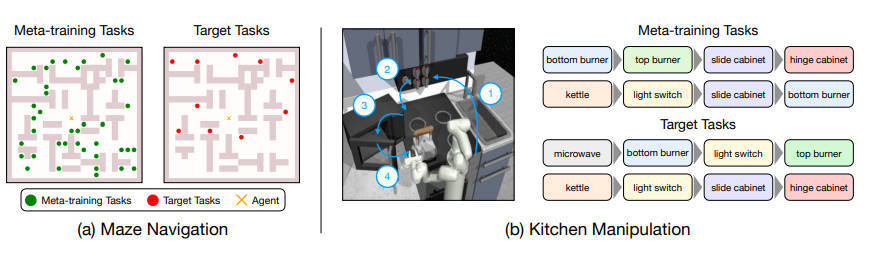
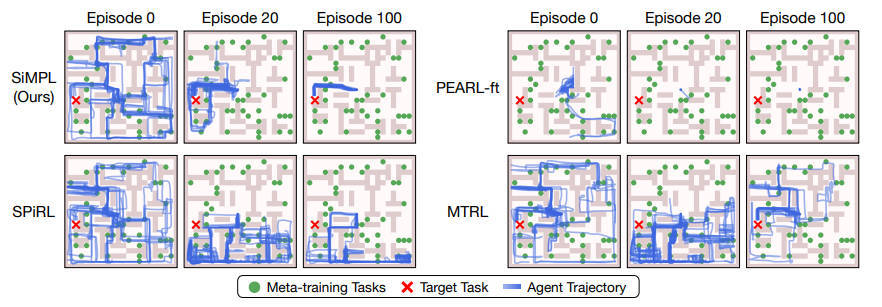
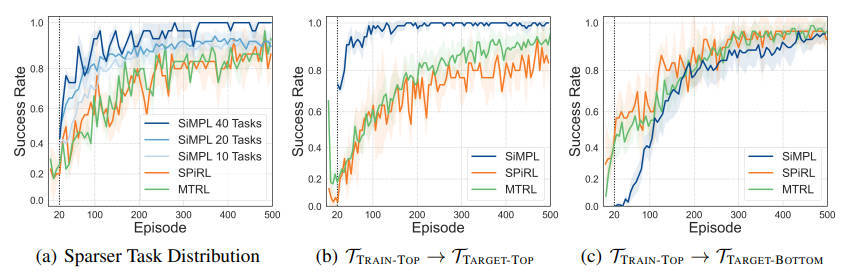
【推荐理由】虽然深度强化学习方法在机器人学习中显示出令人印象深刻的结果,但它们的样本效率低下使得用真实机器人系统学习复杂、长视界的行为变得不可行。本文设计了一种方法,可以在长期、稀疏奖励任务上进行元学习,使能够以更少的环境交互来解决看不见的目标任务。本文的核心思想是在元学习期间利用从离线数据集中提取的先前经验。具体来说,(1)从离线数据集中提取可重用的技能和技能先验;(2)元训练一个高层次的策略,学习将学到的技能有效地组成长期行为;(3)快速适应元训练的策略,以解决一个未见过的目标任务。在导航和操纵方面的连续控制任务的实验结果表明,所提出的方法通过结合元学习和使用离线数据集的优势,可以有效地解决长距离的新目标任务,并不需要大量的环境互动来解决这些任务。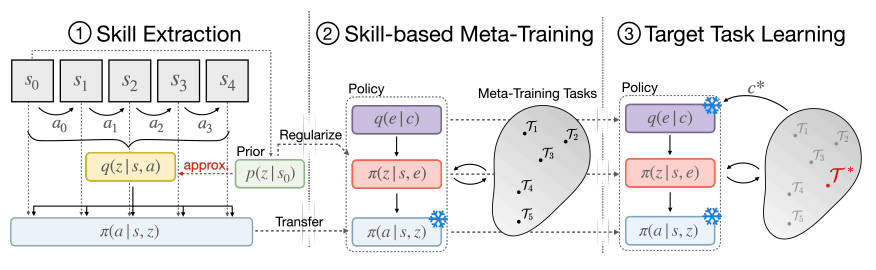
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢