
【标题】When Should We Prefer Offline Reinforcement Learning Over Behavioral Cloning?
【作者团队】Aviral Kumar, Joey Hong, Anikait Singh, Sergey Levine
【发表日期】2022.4.12
【论文链接】https://arxiv.org/pdf/2204.05618.pdf
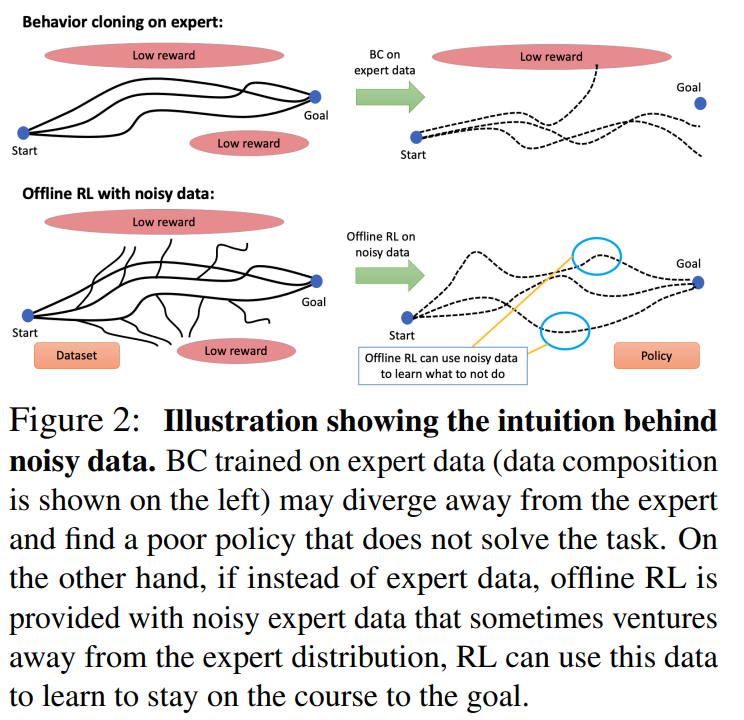
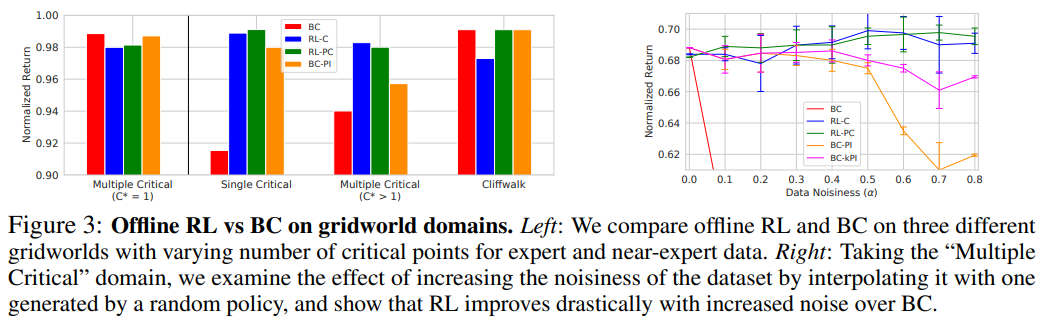
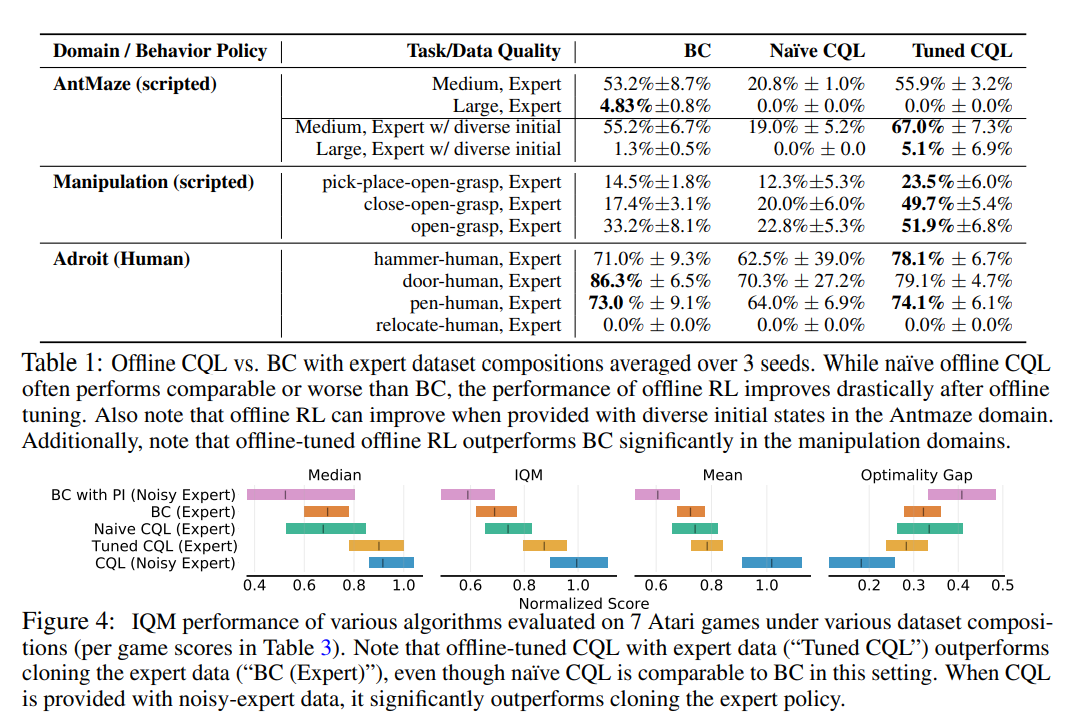
【推荐理由】离线强化学习(RL)算法可以利用先前收集的经验获得有效的策略,而无需任何在线交互。 众所周知,离线 RL 甚至能够从高度次优的数据中提取良好的策略,在这种情况下,模仿学习会发现次优的解决方案并没有改进生成数据集的演示器。 但是,从业者的另一个常见用例是从类似于演示的数据中学习。 在这种情况下,可以选择应用离线 RL,但也可以使用行为克隆 (BC) 算法,该算法通过监督学习模拟数据集的一个子集。 因此,很自然地要问:即使 BC 是自然选择,离线 RL 方法何时才能在等量专家数据的情况下优于 BC? 本文描述了允许离线 RL 方法比 BC 方法表现更好的环境属性,即使只提供专家数据也是如此。 此外,本文表明,在足够嘈杂的次优数据上训练的策略甚至可以比使用专家数据的 BC 算法获得更好的性能,尤其是在长视野问题上。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢