
【标题】SURF: Semi-supervised Reward Learning with Data Augmentation for Feedback-efficient Preference-based Reinforcement Learning
【作者团队】Jongjin Park, Younggyo Seo, Jinwoo Shin
【发表日期】2022.5.18
【论文链接】https://arxiv.org/pdf/2203.10050.pdf
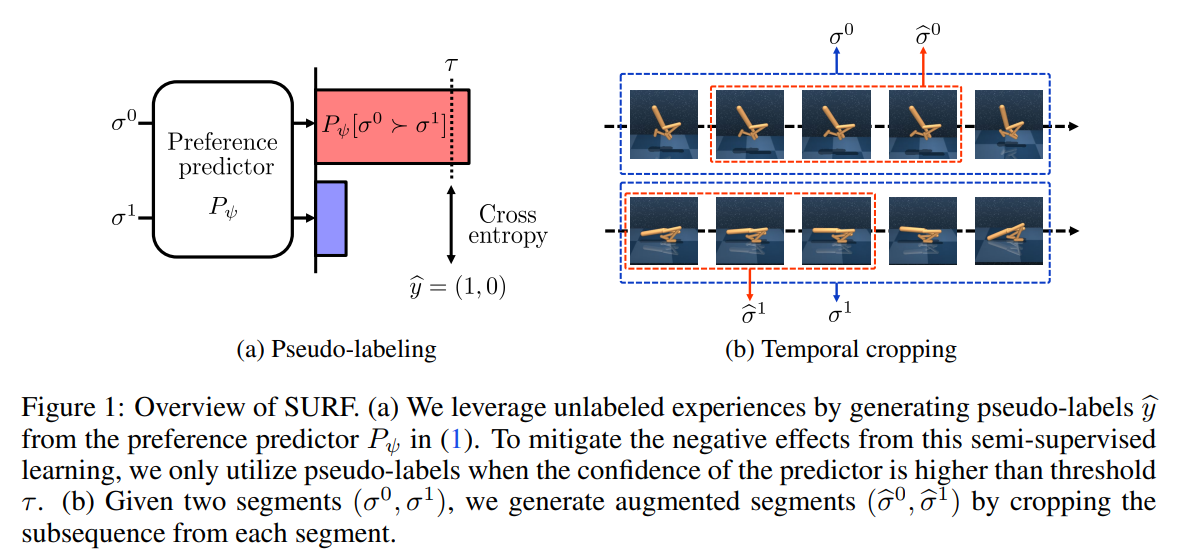
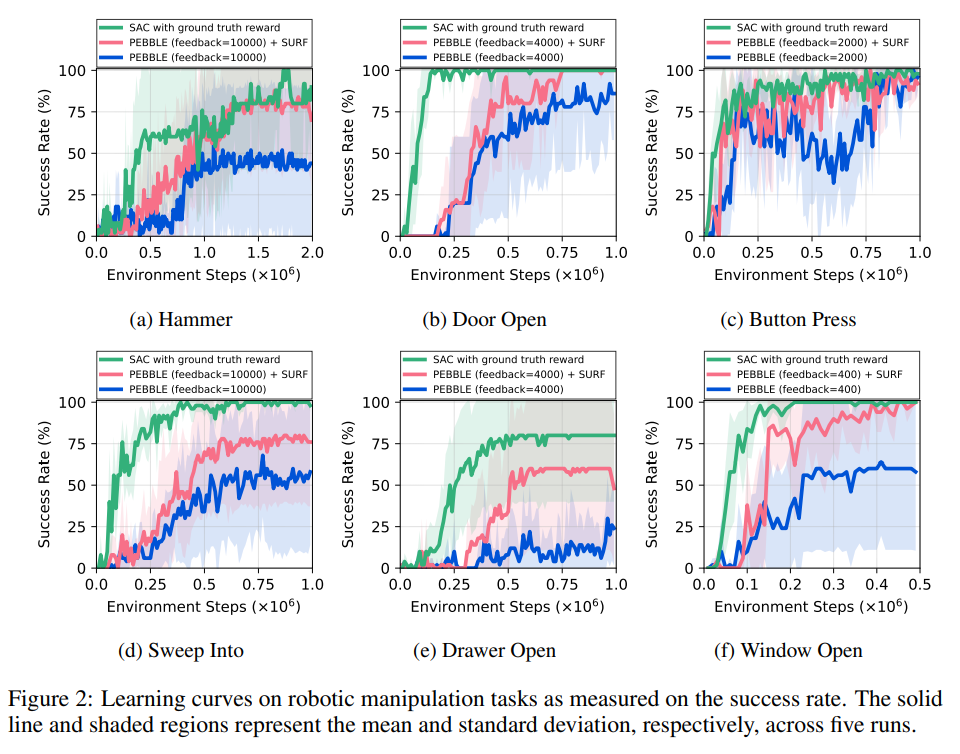
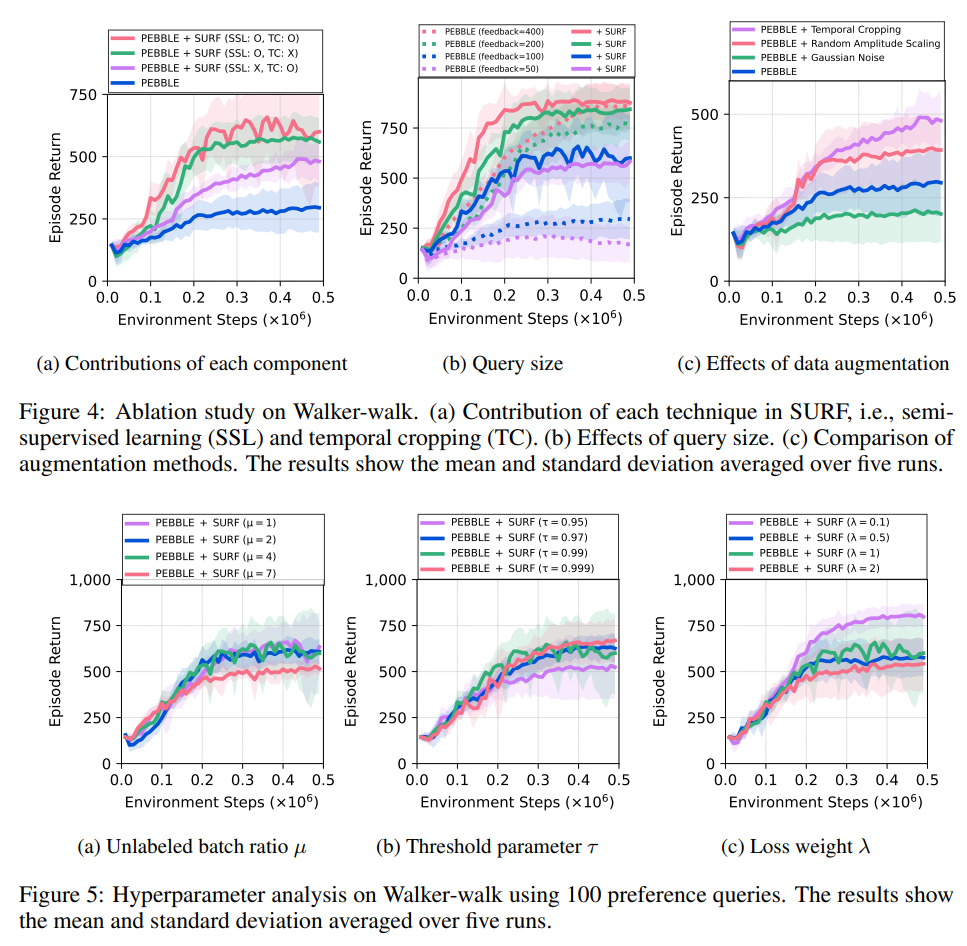
【推荐理由】基于偏好的强化学习(RL)已经显示出,通过在两种智能体行为之间学习主管偏好的奖励,教学智能体可以在没有昂贵的预定义奖励功能的情况下执行目标任务。然而,基于偏好的学习通常需要大量的人类反馈,这使得很难将这种方法应用于各种应用。另一方面,这种数据效率问题通常通过在监督学习的背景下使用未标记样本或数据增强技术来解决。受这些方法最近成功的激励,本文提出了SURF,一种半监督的奖励学习框架,它利用大量未标记的样本进行数据增强。为了利用未标记样本进行奖励学习,本文基于偏好预测器的置信度推断未标记样本的伪标签。为了进一步提高奖励学习的标签效率,作者引入了一种新的数据增强,它从原始行为中临时裁剪连续的子序列。实验表明,本文提出的方法显著提高了最先进的基于偏好的方法对各种运动和机器人操纵任务的反馈效率。

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢