
【标题】COPA: Certifying Robust Policies for Offline Reinforcement Learning against Poisoning Attacks
【作者团队】Fan Wu, Linyi Li, Chejian Xu
【发表日期】2022.5.16
【论文链接】https://arxiv.org/pdf/2203.08398.pdf
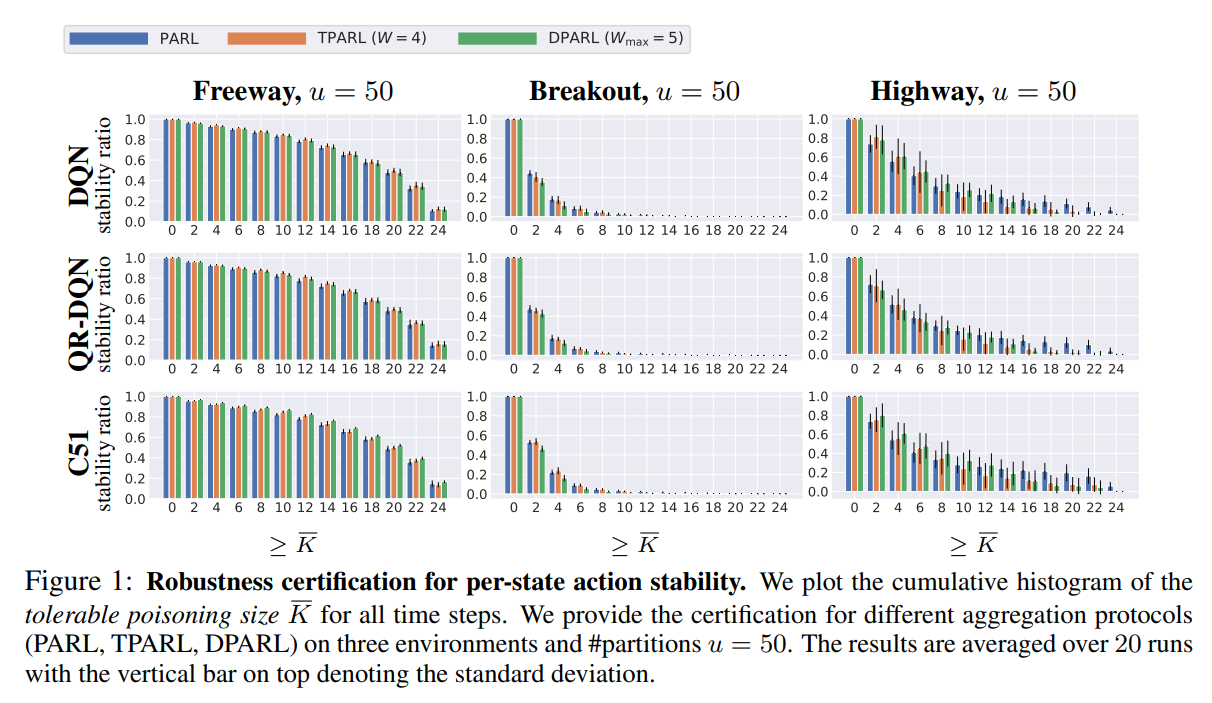
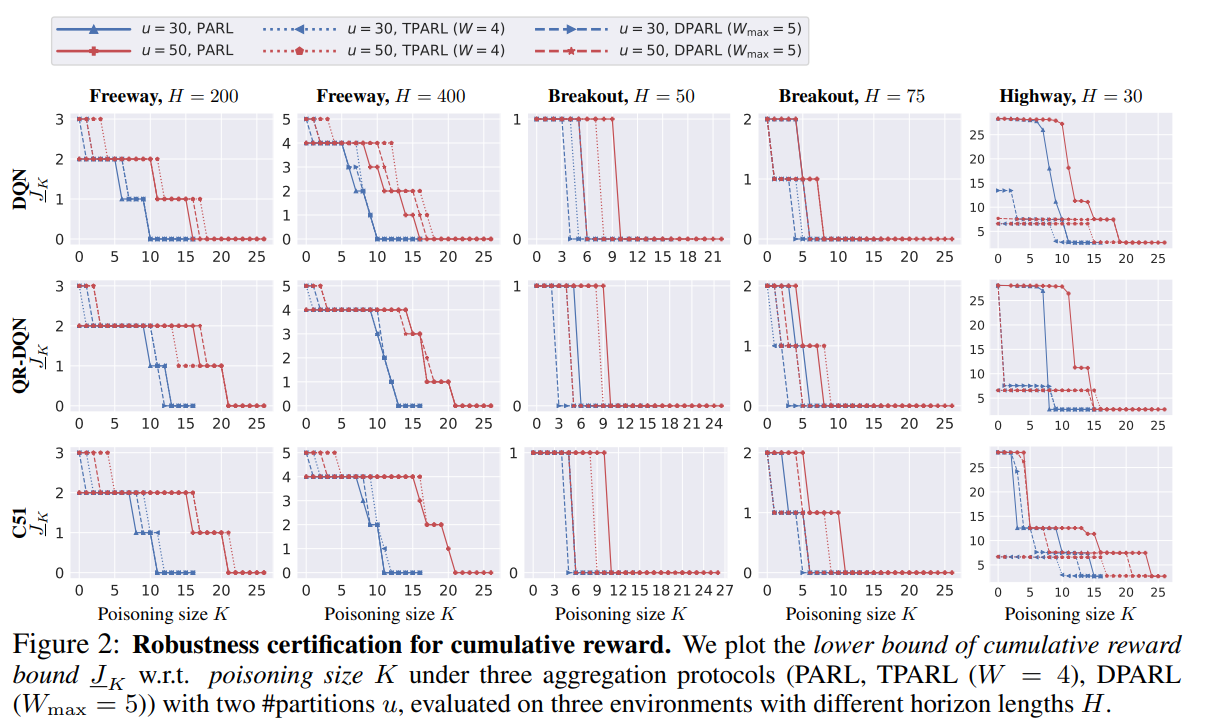
【推荐理由】由于强化学习(RL)在各种任务中取得了接近人类水平的性能,其鲁棒性受到了极大的关注。尽管大量的研究已经探索了RL中的测试时间(逃避)攻击和相应的防御,但其对训练时间(中毒)攻击的鲁棒性仍然基本上没有答案。本文专注于证明离线RL在存在中毒攻击时的鲁棒性,其中训练轨迹的子集可以被任意操纵。作者提出了一个认证框架COPA,以认证不同认证标准下可容忍的中毒轨迹数量。鉴于RL的复杂结构,本文提出了两个认证标准:每个状态行为稳定性和累积奖励界限。作者进一步证明了所提出的一些证明方法在理论上是严格的,而一些是NP完全问题。实验结果显示:(1)所提出的鲁棒聚合协议(例如时间聚合)可以显着提高认证; (2) 对每个状态的动作稳定性和累积奖励界限的认证是高效且严格的; (3) 不同训练算法和环境的认证是不同的,暗示了它们内在的鲁棒性。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢