


论文链接:https://arxiv.org/abs/2211.03295
导读
自从Vision Transformers(ViT)取得成功以来,对Transformers架构的探索也引发了现代ConvNets的复兴。在这项工作中,通过交互复杂性的角度来探索DNN的表示能力。经验表明,交互复杂性是视觉识别的一个容易被忽视但又必不可少的指标。因此,本文作者提出了一个新的高效ConvNet系列,名为MogaNet,以在基于ConvNet的纯模型中进行信息上下文挖掘,并在复杂度和性能方面进行了更好的权衡。
在MogaNet中,通过在空间和通道交互空间中利用两个专门设计的聚合模块,促进了跨多个复杂性的交互并将其情境化。
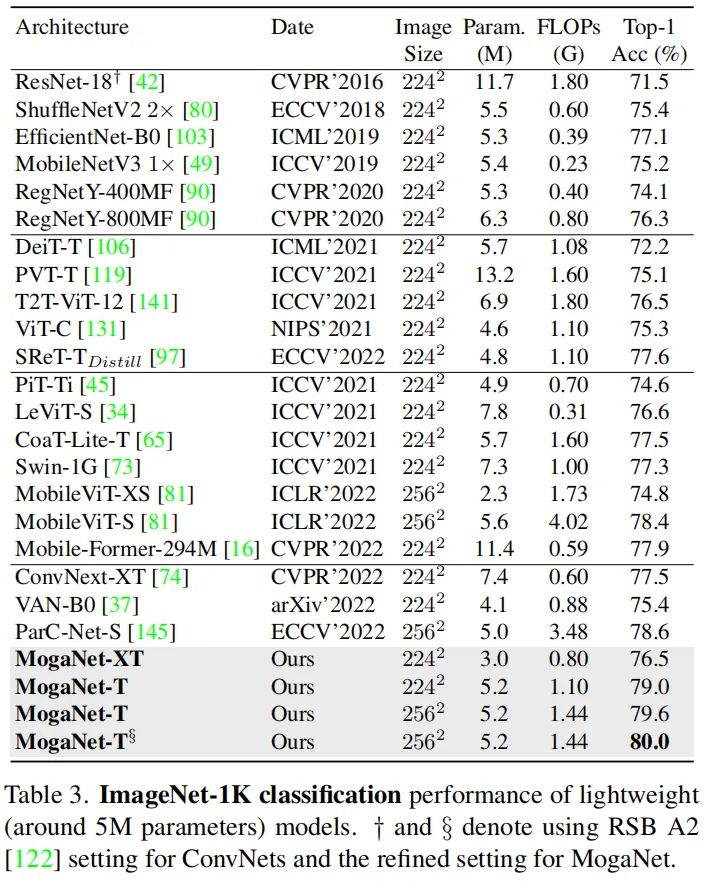
对ImageNet分类、COCO目标检测和ADE20K语义分割任务进行了广泛的研究。实验结果表明,MogaNet在主流场景和所有模型规模中建立了比其他流行方法更先进的新SOTA。通常,轻量级的MogaNet-T通过在ImageNet-1K上进行精确的训练设置,以1.44G的FLOPs实现80.0%的top-1精度,超过ParC-Net-S 1.4%的精度,但节省了59%(2.04G)的FLOPs。
贡献
自深度神经网络(DNN)兴起以来,卷积神经网络(ConvNets)一直是计算机视觉的首选方法。受灵长类视觉系统的启发,卷积层可以对具有区域密集连接和平移等方差约束的观测图像的邻域相关性进行编码。通过交错分层,ConvNets获得了被动增加的感受野,并善于识别潜在的语义模式。尽管性能很高,但ConvNets提取的表示已被证明对区域纹理有很强的偏差,导致视觉目标的全局上下文信息的显著丢失。为了解决这一限制,以前的工作提出了改进的宏架构和上下文聚合模块。
相比之下,通过放松局部感应偏差,新出现的Vision Transformers(ViT)及其变种在广泛的视觉基准上迅速超越了ConvNets。几乎一致的共识是,ViT的能力主要来源于自注意力机制,无论拓扑距离如何,它都有助于长距离互动。然而,从实际角度来看,自注意力机制中的二次复杂性限制了ViT的计算效率及其在细粒度下游任务中的应用潜力。
此外,卷积感应偏置的缺失破坏了图像的固有2D结构,从而不可避免地导致图像特定邻域关系的损害。因此,随后的几项努力都有助于重新引入金字塔状分层布局和ViT的平移不变性。
与之前的研究不同,最近的研究从经验上揭示了ViT的表达优势在很大程度上取决于它们的宏级架构,而不是通常推测的token mixer。更重要的是,通过先进的训练设置和结构现代化,ConvNets可以在不增加计算预算的情况下轻松提供与经过良好调整的ViT相当甚至更优异的性能。然而,现有方法仍然存在一个表示瓶颈:自注意力机制或大内核的实现阻碍了区分性上下文信息和全局交互的建模,导致DNN和人类视觉系统之间的认知差距。与特征整合理论一样,人脑不仅提取局部特征,而且同时聚合这些特征以进行全局感知,这比DNN更紧凑和高效。
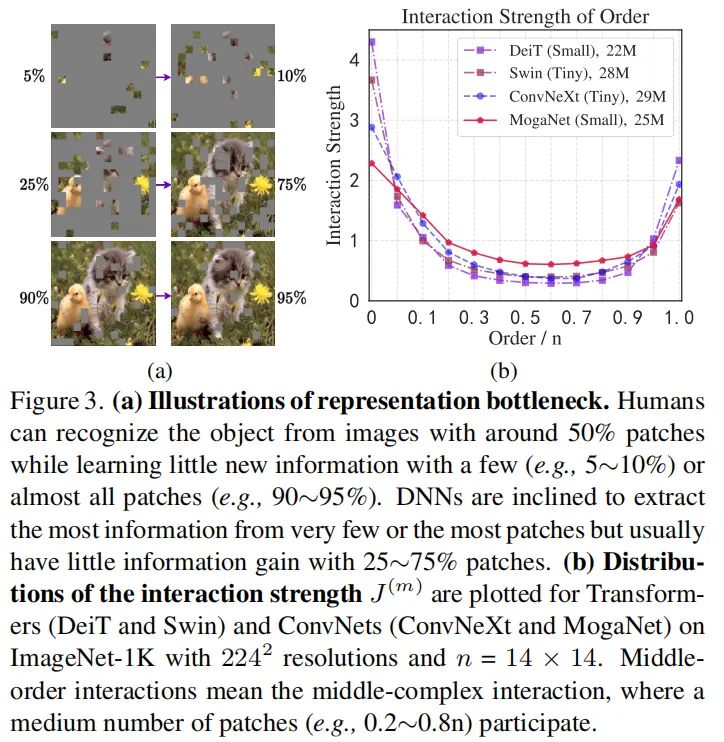
为了应对这一挑战,作者从特征交互复杂性的角度研究了DNN的表示能力。在图3b中,大多数现代DNN倾向于编码极低或高复杂性的相互作用,而不是信息最丰富的中间相互作用。为此,作者涉及了一个具有相应基本操作的宏ConvNet框架,并进一步开发了一个名为多阶门控聚合网络(MogaNet)的新型ConvNets家族,用于加速具有多重交互复杂性的上下文信息。
在MogaNet中,根据人类视觉引入了一个多阶特征聚合模块。作者的设计将局部感知和上下文聚合封装到一个统一的空间聚合块中,在该块中,复合多阶关联通过并行的选通机制被有效地聚合和上下文。从通道方面来看,由于现有方法易于实现高通道信息冗余,因此定制了一个简单而有效的通道聚合块,该块对输入特征执行自适应通道重分配,并以较低的计算成本显著优于主流对应方(例如SE模块)。
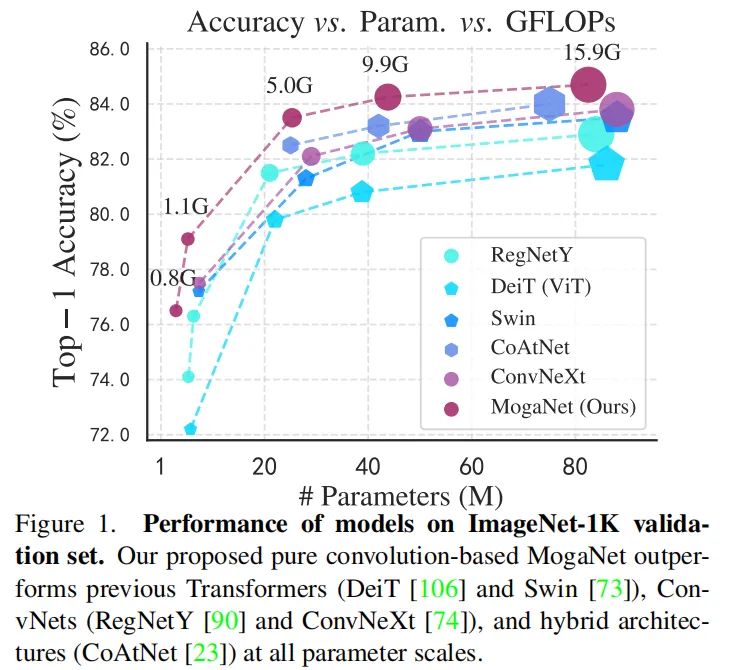
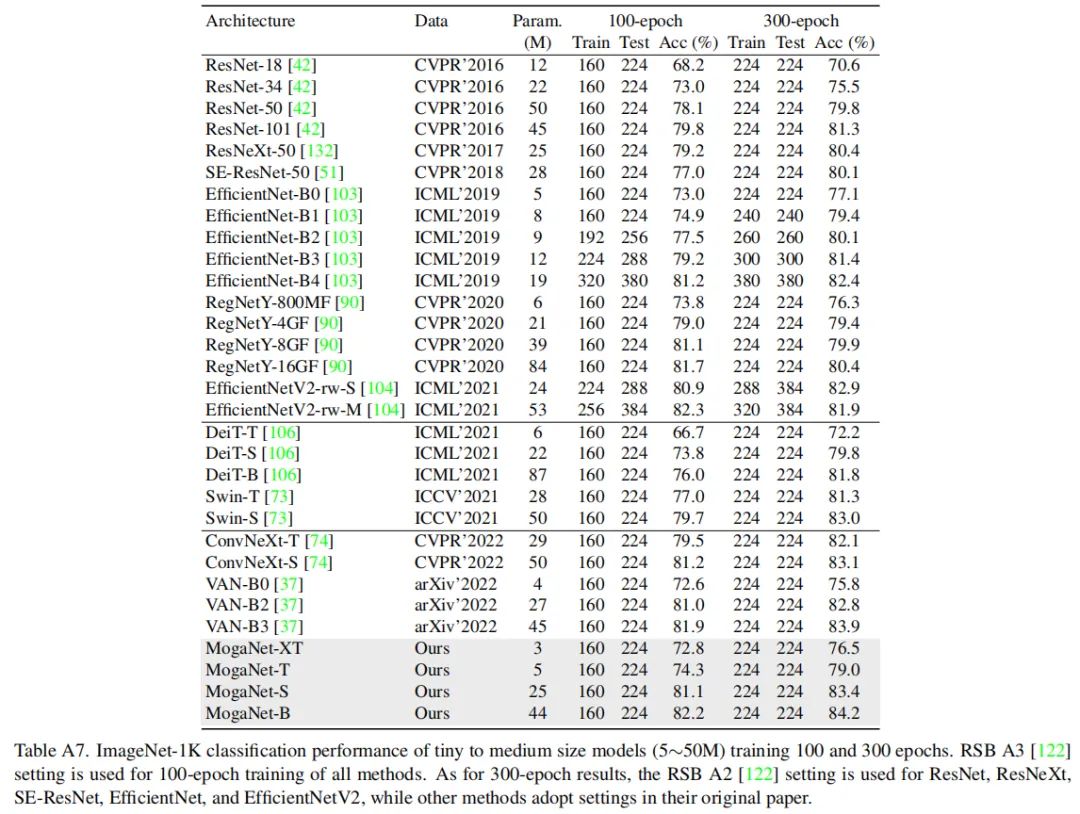
大量实验表明,在ImageNet-1K和多种下游基准上,MogaNet在不同模型尺度下的性能和效率令人印象深刻。经验证明,交互复杂性可以作为高质量视觉识别的重要指标,如感受野。因此,通过1.44G FLOP和5.2M参数,MogaNet-T在ImageNet-1K上使用默认和优化的训练策略,实现了79.6%和80.0%的top-1准确率,在相同设置下,以2.04G的FLOP超过了先前最先进的ParC-Net-S 1.0%。此外,MogaNet-S以4.97G FLOP和25.3M参数达到83.4%的top-1精度,与流行的小型模型相比,产生了可观的计算开销,如图1所示。
方法
1) 概览MogaNet
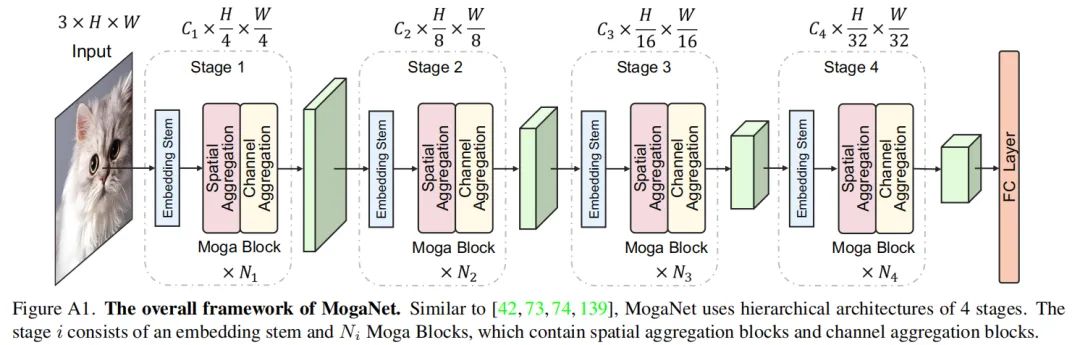
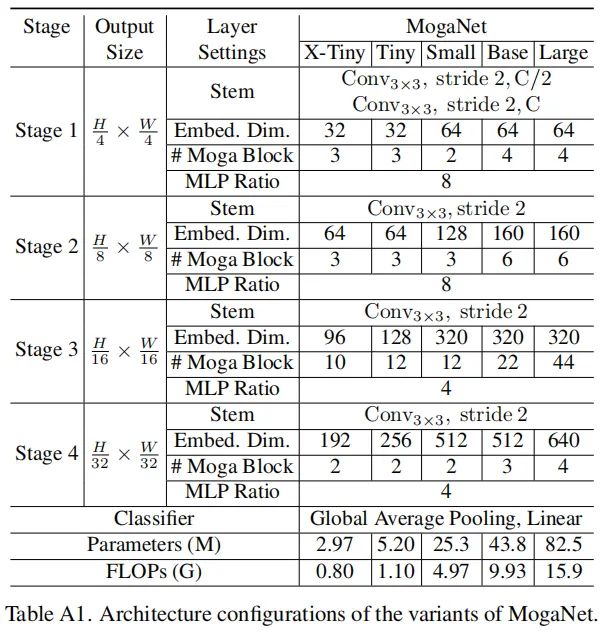
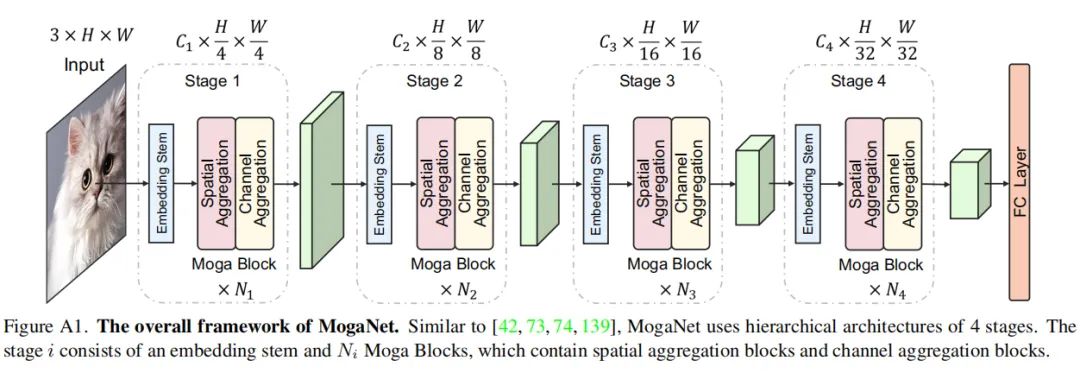
图A1提供了4阶段MogaNet架构的说明。对于阶段i, 输入图像或特征首先被馈送到嵌入Stem 中以调节特征分辨率并嵌入到 维度中。假设输入图像为H*W分辨率, 4 个阶段的特征分别为H/4*W/4、H/8*W/8、H/16*W/16和H/32*W/32分辨率。
然后, 嵌入的特征流到NiMoga块中, Moga块由空间和通道聚合块组成, 用于进一步的上下文提取和聚合。GAP和线性层将在分类任务的最终输出之后添加。对于密集预测任务, 4个阶段的输出可以通过颈部模块使用。
2) 多阶门控聚合
特征整合理论表明,人类视觉通过提取基本的上下文特征并将个体特征与注意力相关联来感知目标。然而,正如在第3节中经验性讨论的那样,仅存在区域性感知或语境聚合不足以同时学习不同的语境特征和多秩序互动。
图3b显示了传统DNN倾向于关注低阶或高阶相互作用。他们错过了最丰富的中阶交互。因此,主要的挑战是如何有效地捕捉上下文中的多阶交互。
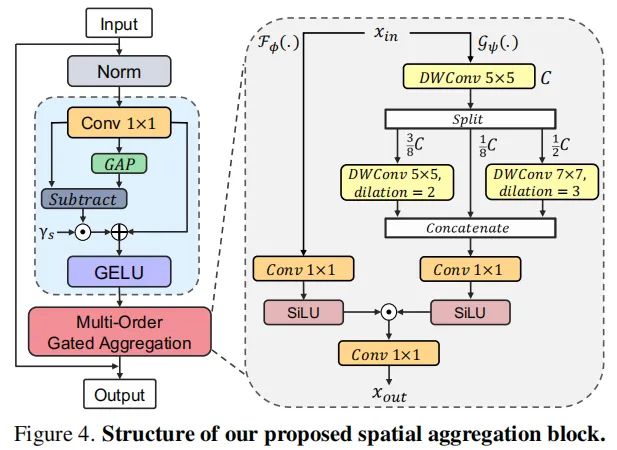
为此, 作者提出了一个空间聚合 (SA) 块SMixer() , 以在统一设计中聚合多阶上下文, 如图4所示, 该块由 2 个级联组件组成:
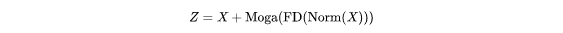
其中, FD()是一个特征分解模块 (FD), Moga()是一个多阶门控聚合模块, 由门控 F和上下文分支G组成。
1、多阶上下文特征
作为一个纯卷积结构, 作者提取具有静态和自适应区域感知的多阶特征。除了模阶交互作用外, 还有两个不重要的交互作用, 每个patch本身的 0 阶交互作用和覆盖所有patch的一阶交互 来动态地排除不重要的交互作用, 其表述为:
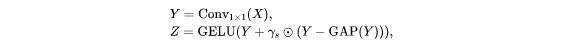
其中, \( \gamma \)是一个初始化为零的缩放因子。
通过重新对不重要的交互成分Y-GAP(Y)进行重新加权, FD()也增加了特征多样性。然后, 集成了深度卷积(DWConv) , 在 Moga()的上下文分支中对多阶特征进行编码。

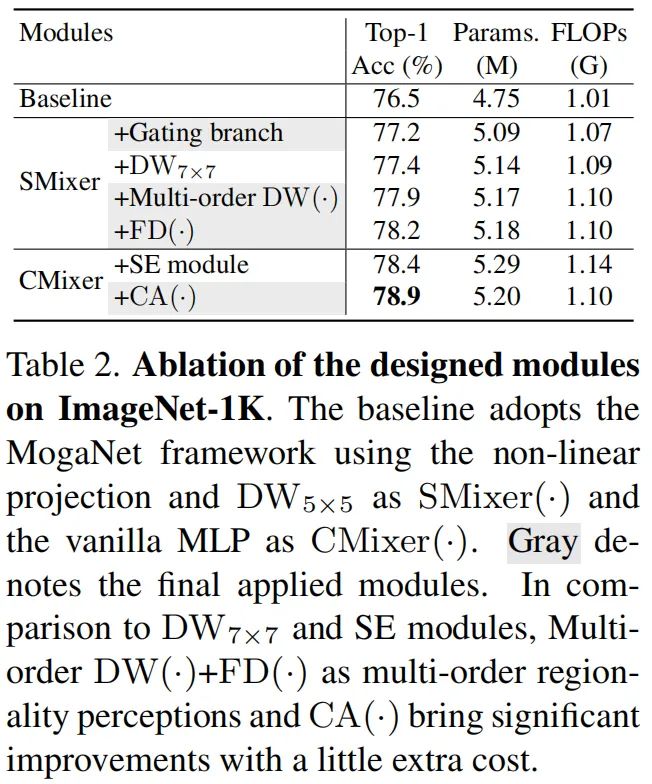
请注意,与ConvNeXt中使用的DW7×7相比,建议的FD(·)和多阶DWConv层只需要少量额外的计算开销和参数,例如,+多阶和+FD(·)比DW7×8增加了0.04M参数和0.01G FLOPS,如表2所示。
2、门控聚合
为了聚合来自上下文分支的输出上下文, 在门控分支中使用了 , 即 。如附录C.1所证实的,作者发现SiLU既具有 Sigmoid的门控效应, 又具有稳定的训练特性。以 的输出作为输入, 重写等式(4)对于 :
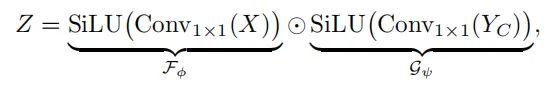
使用所提议的SA块,MogaNet捕获了更多的中间阶交互,如图3b所示。SA块产生与ConvNeXt相似的高质量多阶表示,这远远超出了现有方法的覆盖范围,而不需要应用成本消耗的聚合。
3、架构细节
实验
1、分类
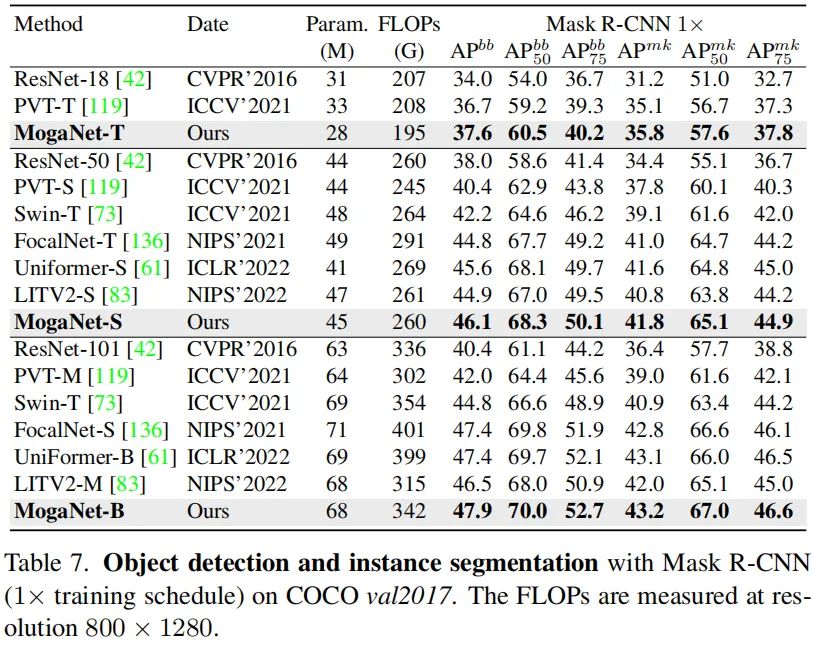
2、目标检测与实例分割
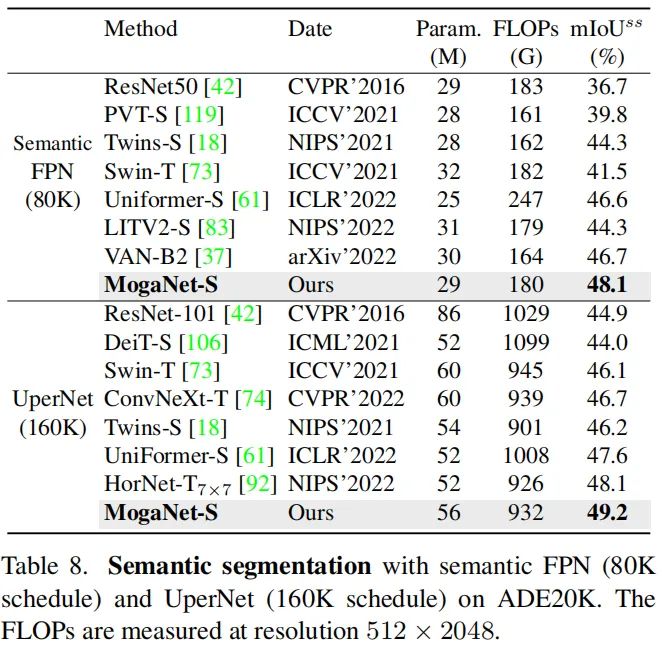
3、语义分割
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢