
论文地址:
https://arxiv.org/pdf/2210.11078.pdf
代码地址:
https://github.com/Sense-X/AGVM
导读
在当前的机器学习社区中,有三个普遍的趋势。
-
首先,神经网络模型会越来越大。在 NLP 领域中最大规模的模型已经达到了上万亿级别。在视觉领域,最大规模的模型也达到了三百亿的量级。
-
其次,训练的数据集也变得越来越大。比如,ImageNet 21k 和谷歌的 JFT 数据集都具有相当规模的数据集。
-
另外,由于数据集变得越来越大,训练 SOTA 模型的开销越来越大。
因此,提升训练效率就变得愈发重要。而分布式训练因为其适应于数据并行、模型并行和流水线并行的加速训练方法的同时,也具备较高的 Deep Learning 通信效率而被广泛认为是一个有效的解决方案。
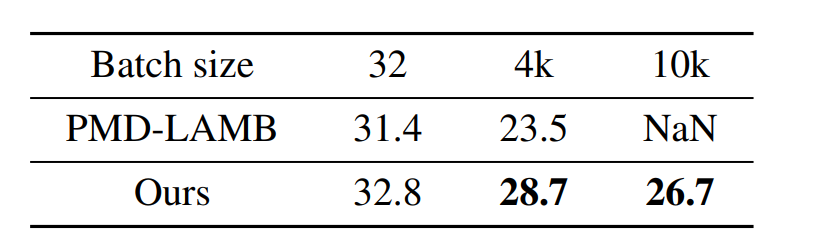
随着大模型时代的到来,目标检测器的训练速度越来越成为学术界和工业界的瓶颈,例如,在 COCO 的标准 setting 上把 mAP 训到 62 以上大概需要三天的时间,算上调试成本,这在业界几乎是不可接受的。那么,我们能不能把这个训练时间压到小时级别呢?事实上,在图片分类和自然语言处理任务上,先前的研究人员借助 32K 的批量大小(batch size),只需 14 分钟就可以完成 ImageNet 的训练,76 分钟完成 Bert 的训练。但是,在目标检测领域,还很欠缺这类研究,导致研究人员无法充分利用当前的算力,数据集和大模型。
大批量训练算法 AGVM 便是这个问题的最佳解决方案之一。为了支持如此大批量的训练,同时保持模型的训练精度,本研究提出了一套全新的训练算法,根据密集预测不同模块的梯度方差(gradient variance),动态调整每一个模块的学习率。作者在大量的密集预测网络和数据集上进行了实验,并且证实了该方法的合理性。
方法
大批量训练是加速大型分布式系统中深度神经网络训练的关键。尤其是在如今的大模型时代,如果不采用大批量训练,一个网络的训练时间几乎是难以接受的。但是,大批量训练很难,因为它会产生泛化差距(generalization gap), 直接训练会导致其准确率降低。此前的大批量工作往往针对于图像分类以及一些自然语言处理的任务,但密集预测任务(包括检测分割等),同样在视觉中处于举足轻重的位置,此前的方法并不能在密集预测任务上有很好的表现,甚至结果比基准线更差,这导致我们难以快速训练一个目标检测器。
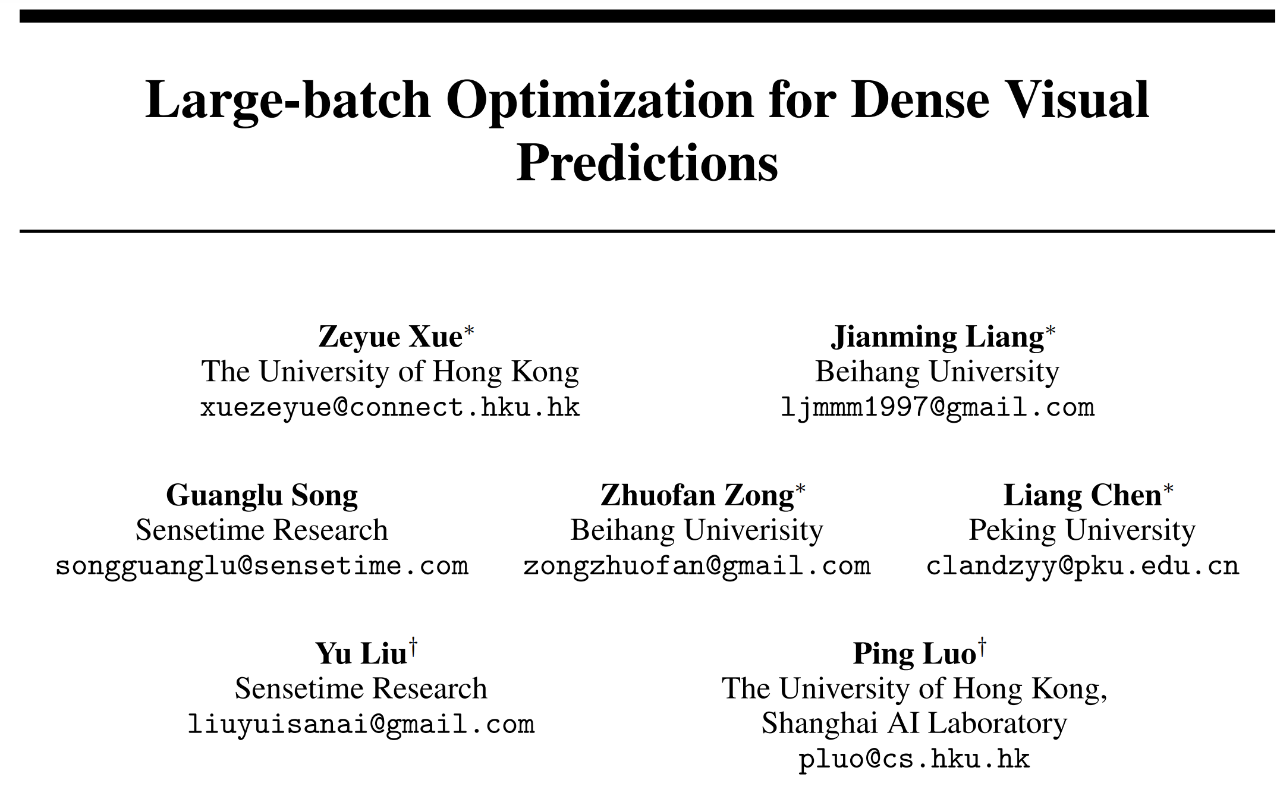
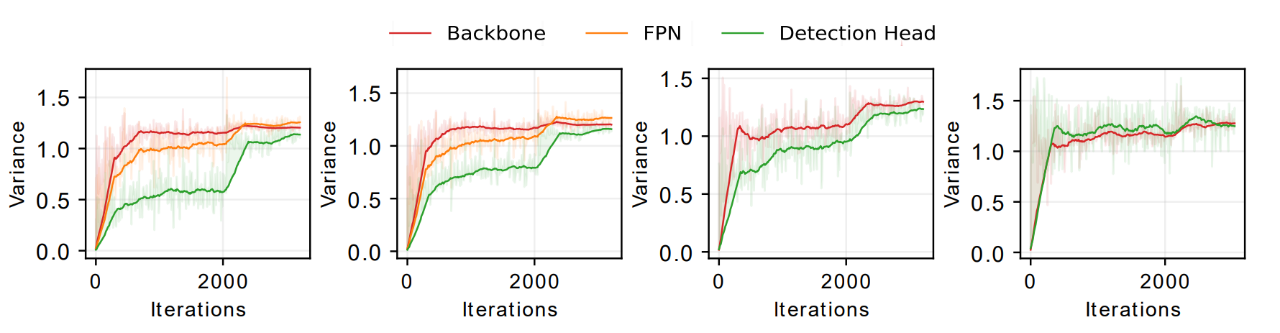
为了解决这个问题,研究人员进行了大量的实验。最后发现,相较于传统的分类网络,利用密集预测网络一个很重要的特征:密集预测网络往往是由多个组件组成的,以 Faster R-CNN 为例:它由四个部分组成,骨干网络 (Backbone),特征金字塔网络(FPN),区域生成网络(RPN) 和检测头网络(head),我们可以发现一个很有效的指标:密集预测网络不同组件的梯度方差,在训练批量很小时(例如 32),几乎是相同的,但当训练批量很大时(例如 512),它们呈现出很大的区别,如下图所示:
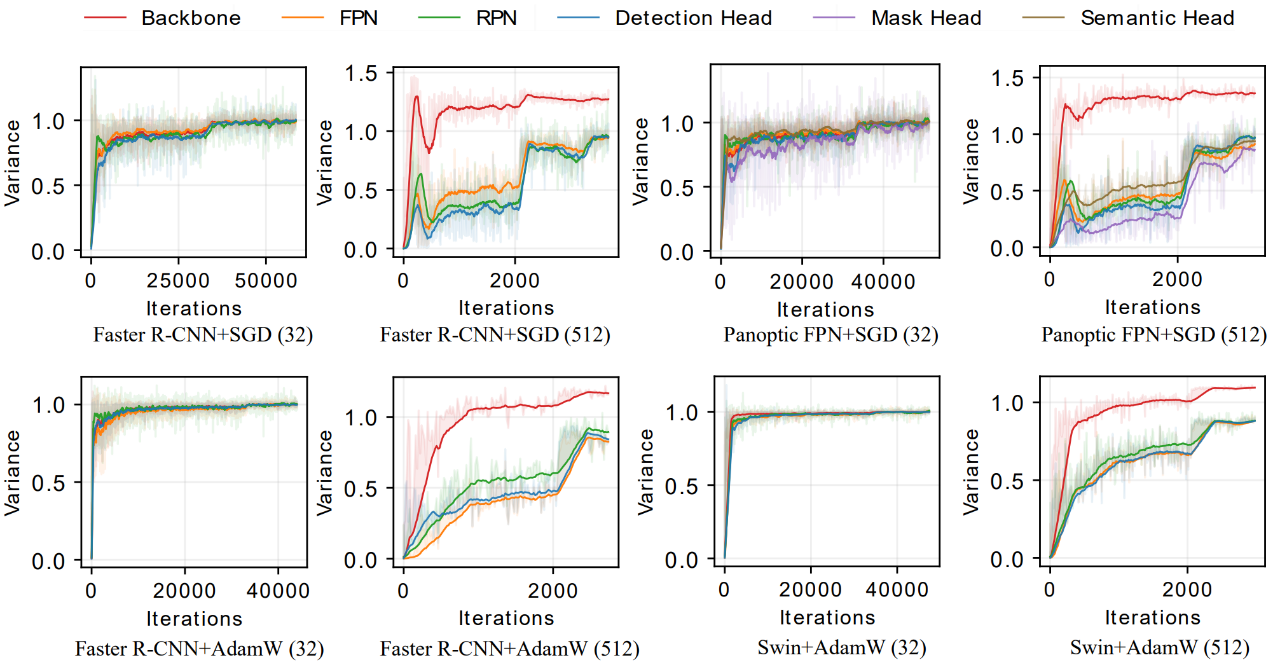
那么,能不能直接把这些拉平呢?这直接引出了 AGVM 算法。以随机梯度下降算法为例,上角标 i 代表第 i 个网络模块(例如 FPN 等),上角标 1 代表骨干网络, 代表学习率,锚定骨干网络,可以直接将不同网络组件的梯度 g 的方差 :
\( w_{t+1}^{(i)}=w_{t}^{(i)}-\hat{\eta}_{t}^{(i)} g_{t}^{(i)} , \text{where} \quad \hat{\eta}_{t}^{(i)}=\eta_{t} \mu_{t}^{(i)} \quad \text{and} \quad \mu_{t}^{(i)}=\sqrt{\frac{\Phi_{t}^{(1)}}{\Phi_{t}^{(i)}}} \)
梯度的方差 可以由以下式子估计:
\( \Phi_{t}^{(i)}=\eta_{t}^{2}\left(1-\cos \left(G_{t, 1}^{(i)}, G_{t, 2}^{(i)}\right)\right) \)
方差的具体求解细节可以参考原文,本研究同样引入了滑动平均机制,防止网络训练发散。同时,研究证明了 AGVM 在非凸情况下的收敛性。


实验
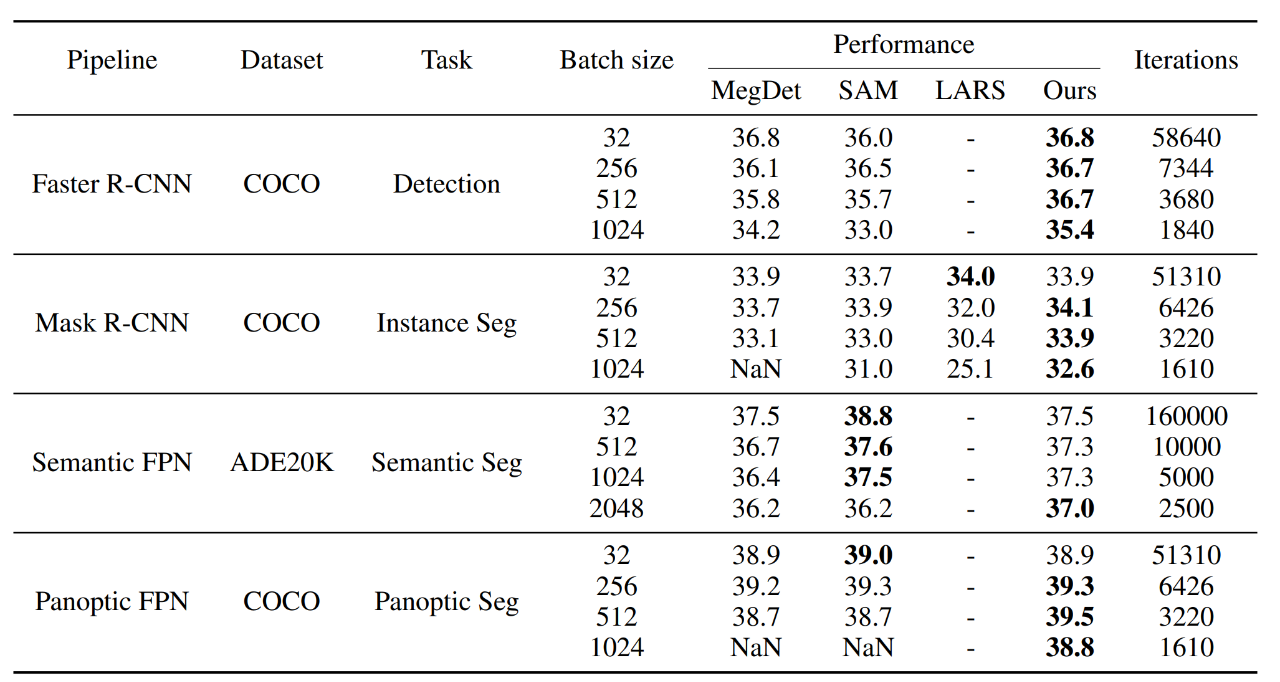
本研究首先在目标检测、实例分割、全景分割和语义分割的各种密集预测网络上进行了测试,通过下表可以看到,当用标准批量大小训练时,AGVM 相较传统方法没有明显优势,但当在超大批量下训练时,AGVM 相较传统方法拥有压倒性的优势,下图第二列从左至右分别表示目标检测,实例分割,全景分割和语义分割的表现,AGVM 超越了有史以来的所有方法:
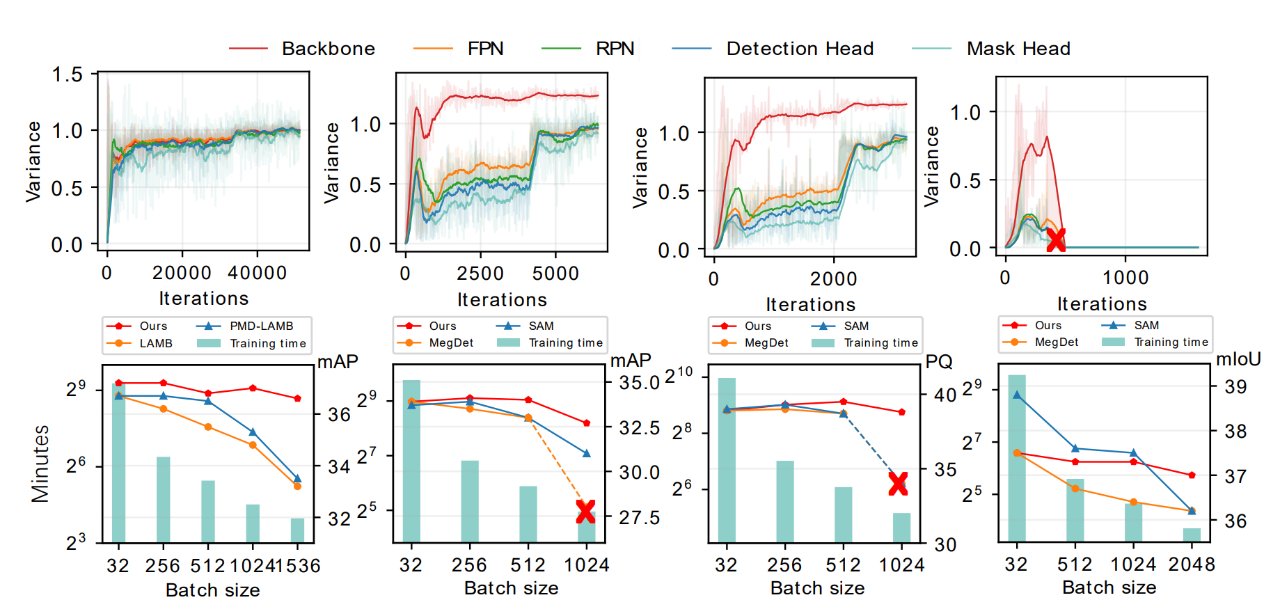
下表详细对比了 AGVM 和传统方法,体现出了本研究方法的优势:
同时,为了说明 AGVM 的优越性,本研究进行了以下三个超大规模的实验。研究人员把 Faster R-CNN 的 batch size 放到了 1536,这样利用 768 张 A100 可以在 4.2 分钟内完成训练。其次,借助 UniNet-G,本研究可以在利用 480 张 A100 的情况下,3.5 个小时让模型在 COCO 上达到 62.2mAP(不包括骨干网络预训练的时间),极大的减小了训练时间:

甚至,在 RetinaNet 上,本研究把批量大小扩展到 10K。这在目标检测领域是从未见的批量大小,在如此大的批量下,每一个 epoch 只有十几个迭代次数,AGVM 在如此大的批量下,仍然能展现出很强的稳定性,性能如下图所示:
本研究探究了一个很重要的问题:以 RetinaNet 为例,如下图第一列所示,探究为什么会出现梯度方差不匹配这一现象。
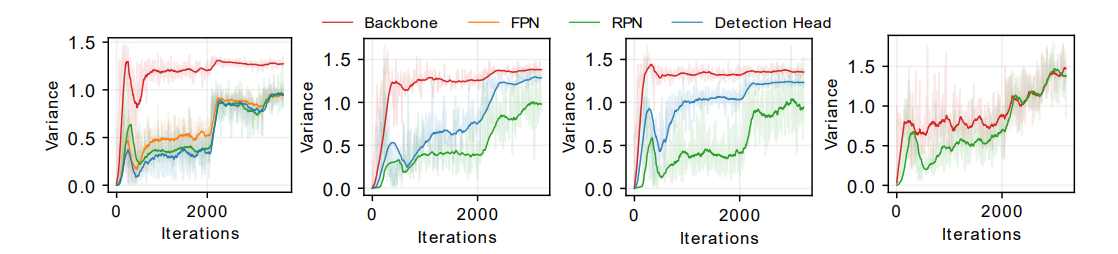
本研究认为,这一现象来自于:网络不同模块间的有效批量大小 (effective batch size) 是不同的。例如,RetinaNet 的头网络的输入是由特征金字塔的五层网络输出的,特征金字塔的 top-down 和 bottom-up pathways,以及像素维度的损失函数计算会导致头网络和骨干网络的等效批量大小不同,这一原理导致了梯度方差不匹配的现象。
为了验证这一假设,本研究依次给每一层特征使用单独的头网络,移去特征金字塔网络,随机忽略掉 75% 的用于计算损失函数的像素,最终,本研究发现骨干网络和头网络的梯度方差曲线重合了,本研究也对 Faster R-CNN 做了类似的实验,如下图第二列所示,更多的讨论请参见原文。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢