
本文旨在深入浅出的介绍图上的分布外泛化问题(一个最近刚火的研究方向)与基于(因果)不变性原理的求解思路,对相关领域研究者提供easy-to-follow的讲解。本文内容主要基于今年年初笔者发表于ICLR‘22的论文《Handling Distribution Shifts on Graphs: An Invariance Perspective》

论文地址:
https://arxiv.org/abs/2202.02466
项目地址:
https://github.com/qitianwu/GraphOOD-EERM
这项工作首次对图上的节点级任务的分布外泛化问题给出了一般化定义,并基于不变性原理给出了有理论保障的解决思路。文末还会简单介绍笔者合作参与的三个刚被NeurIPS‘22接收的相关工作,并讨论可以进一步探索的方向。
写在前面
图机器学习目前依然是炙手可热的研究领域,但不少的已有方向都遇到了瓶颈期。本文将要重点介绍的分布外泛化问题(Out-of-distribution Generalization,简称OOD泛化)也为图学习引入了一个新的子赛道,与现有的很多场景和设定都存在可能的交叉,目前有很大的研究空间。
为什么要考虑分布外泛化的问题?
如何提高在新数据(例如未知分布或未见实体)上的泛化性能是机器学习的一个核心问题。我们知道一般的学习问题都是在一个训练集上完成模型训练,而后模型需要在一个新的测试集上给出结果。机器学习问题的误差可以被大致分解为两部分:
\text{总误差} = \text{表示误差} + \text{泛化误差}
其中表征误差(反映了模型拟合训练数据的能力)是由模型的表达能力/容量决定的,而泛化误差则由在训练集与测试集模型表现的差异决定。当我们采用较为复杂的模型结构(例如神经网络)与有效的优化算法,可以大大降低表征误差。但是当测试数据分布与训练分布呈现明显不同时,模型的泛化误差则很难被控制。这样的场景在实际中也很常见,比如在线下数据进行训练的推荐模型需要泛化到线上的真实场景,在模拟场景下训练的驾驶器要泛化到具有真实交互的环境中。这就是分布外泛化要解决的核心问题:如何利用有限观测的数据,学习一个稳健的模型,能够泛化到与训练分布有明显差异的测试数据上。
图上的节点级分布外泛化的挑战
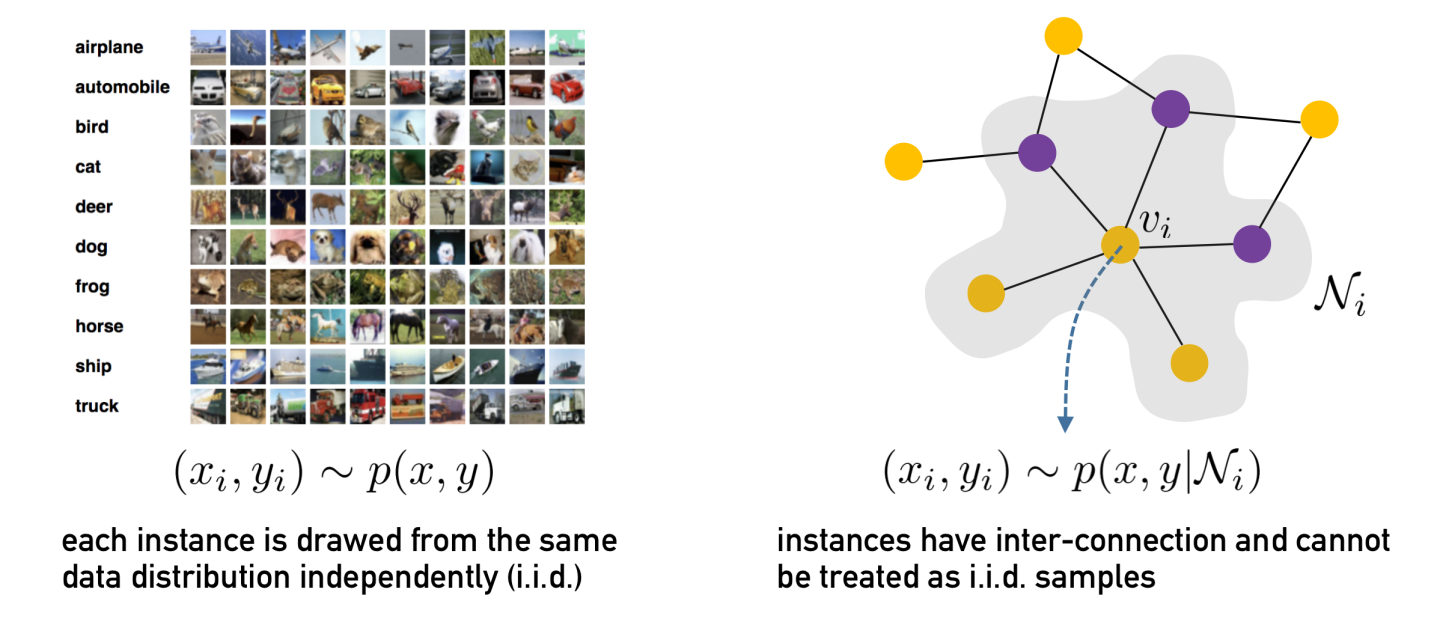
目前大部分关于分布外泛化问题的研究集中在欧式数据(如图片),而对于图结构数据的相关研究还较少。与普通欧式数据不同的是,图结构数据上节点级预测任务的分布偏移问题需要解决两个核心的技术挑战。
-
样本互连性: 由于节点的互连特性,数据样本通常是非独立同分布的,这就为数据分布的建模带来了困难。下图给出了一个简单示意,对于图片数据我们可以把生成每张图片的分布看作相同且独立的;然而对于图结构数据,每个节点的生成依赖于邻居节点,数据分布不能被看作独立的。
-
图结构信息: 除了节点特征外,图的结构也蕴含了重要的信息,会影响到表示学习和预测任务。因此,在考虑数据分布建模与模型泛化的时候,也需要挖掘结构信息的特征并兼顾其影响。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢