
ACM MM 2022:基于密度代理的半监督人群计数
*通讯作者:洪晓鹏
◆ ◆ ◆ ◆
本文提出了一种基于密度代理引导的半监督计数方法。首先,构建了一个可学习的辅助机制,称作密度代理,使前景区域(即有人的像素位置)特征接近在代理中相应的密度子类,并推远所有的背景特征。其次,提出了一种密度引导的对比学习损失来巩固人群计数模型。再次,通过前景变形器结构来辅助密度预测端口的输出,进一步细化前景特征。最后,文章还提出了有效的噪声抑制损失来最小化标注中的噪声造成的负面影响。大量实验表明,所提模型在四个具有挑战性的人群计数数据集 ShanghaiTech A&B、UCF-QNRF、JHU-CROWD++ 上取得了比之前半监督计数方法更优越的性能。
由于人群计数在人群监控、拥堵估计和公共安全方面的广泛应用,近年来受到了广泛关注。然而,稳定且准确的人群计数器通常依赖于足够多的标记图像,即需要在每个人头中心都标记点注释。这个注释过程是很耗时耗力的。例如,UCF-QNRF 数据集涉及 125 万个注释,几乎需要 2000 小时。因此,半监督人群计数(使用少量有标签数据大量无标签数据)能够降低注释成本,同时实现良好的计数精度。该方法旨在从未标记的数据中提取的知识来辅助计数任务。先前的半监督计数方法往往依赖于一个额外的辅助任务,如二进制分割任务或切图中人群数量排序的先验来实现在无标签数据上的自监督。也有方法使用高斯过程和师生模型等方法生成伪标签,可以有效地降低标注成本。但这些方法的性能依旧存在瓶颈。一方面,仅限于一张图片中的自监督学习机制可能会忽略不同图像之间的相似信息。另一方面,模型通过在少量标记图像上训练来为无标签数据生成高质量的伪标签。
为了解决这些限制,在本文中,我们提出了一种新的半监督计数框架,用于对有限标签进行可靠和充分的监督。本文的新颖之处在于密度代理机制,基本原理源于一个发现,即可以通过比较不同的图像区域来挖掘密度线索。图 1 展示了了一个例子。当我们比较背景区域 (a) 和前景区域 (b) 时,虽然这两个区域来自同一张图像,但它们看起来完全不同。另一方面,对于前景区域 (b),我们可以很容易地在其他人群图像中找到具有类似密度 (c) 的对应区域。一个合理的监督机制是根据不同的密度级别对所有图片的前景实例进行建模。
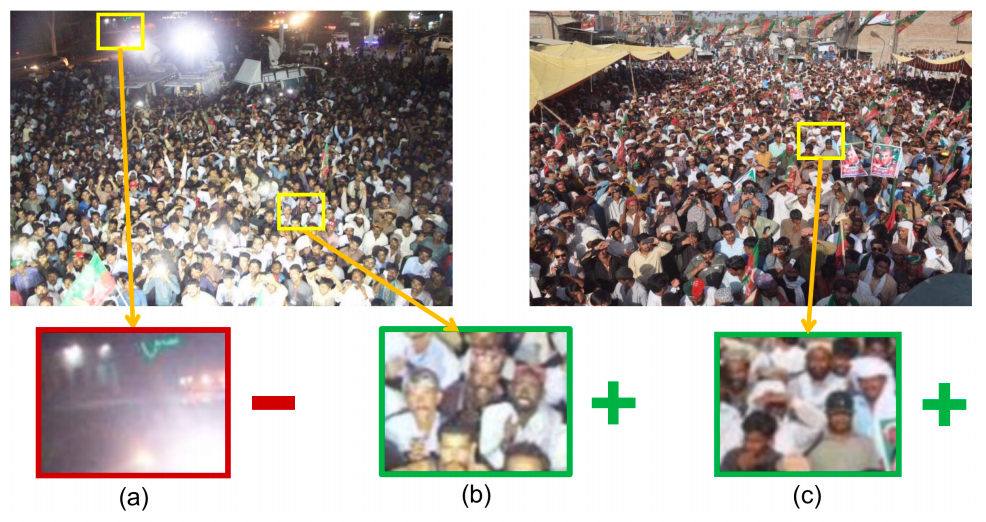
图 1 可以通过关联不同图像中的区域来探索密度信息和监督信号
在此基础上,我们提出了密度代理引导的半监督人群计数模型,将不同图像的区域关联起来,以获得可靠的监督信号。密度机构是与计数骨干网络相关的可学习辅助结构。它由一组密度级别的代理和一个代理分配器组成,并充当中介来识别实例(图像区域)是否为前景。对于前景实例,它进一步量化了姿态中前景的密度级别,根据其密度级别将前景实例(人群密集的区域)细分为子类,并分配相应的密度级别代理。然后它测量实例和代理之间的相关性,这在指导人群计数器的学习过程中起着重要作用。一般来说,在训练过程中,密度代理将识别出的前景实例带到相应的子类(密度级别代理)中,并推开特征空间中的负面实例。
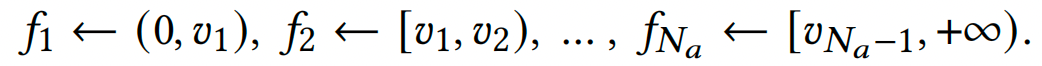
图 2 中的左下角矩形说明了代理分配器如何将每个特征划分到相应的代理。对于标记的数据,代理分配器将利用标签生成的密度图来对不同的区域进行分类。对于未标记的数据,则没有可用的标签密度图,因此未标记的数据图像首先经过计数模型生成预测的密度图,代理分配器将使用该预测作为参考。
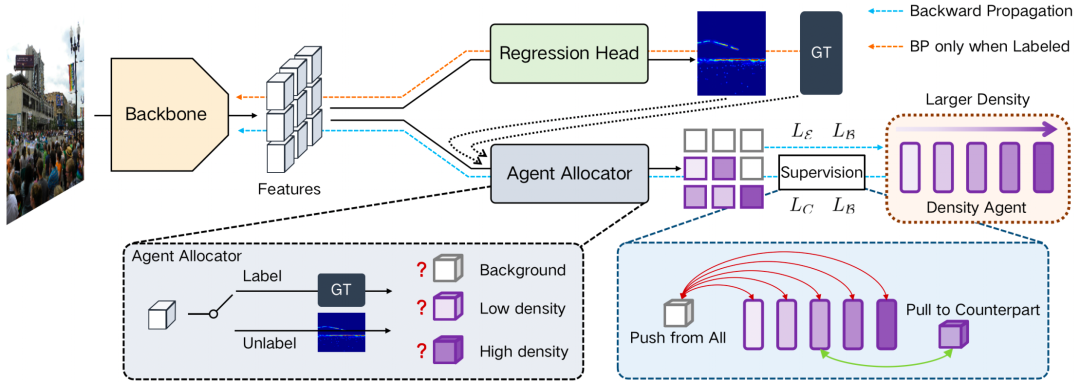
图 2 计数模型和密度代理的整体结构图
通过代理机制,我们期望将前景区域特征拉近它们对应的密度子代理,并将背景特征推离所有子代理。为了实现这一目标,模型将最大化正对之间的相似性,每个正对由前景特征向量及其密度子代理组成,并最小化负对之间的相似性,每个负对包含背景特征向量和全部子代理。
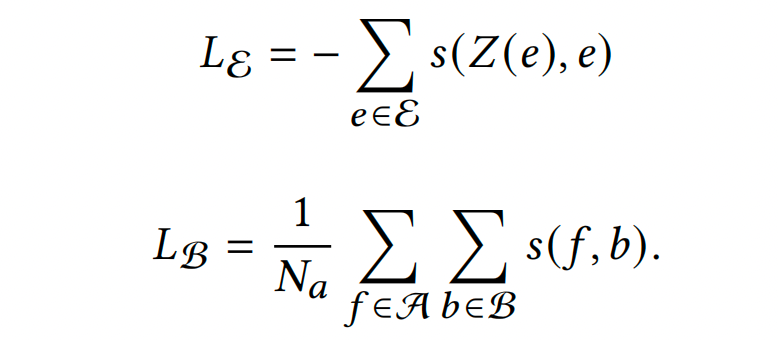
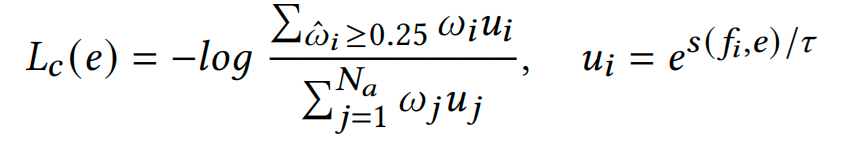
此外,我们还使用 Transformer 结构仅细化前景特征,详细信息如图 3 所示。它包括前景的自我注意力以及前景和背景特征之间的交叉注意力。在这两个注意力模块的帮助下,前景特征不仅可以与自身产生交互注意力,还可以挖掘与背景的关系。前景与背景特征之间的距离进一步扩大,前景内部的差异也得到了充分挖掘。
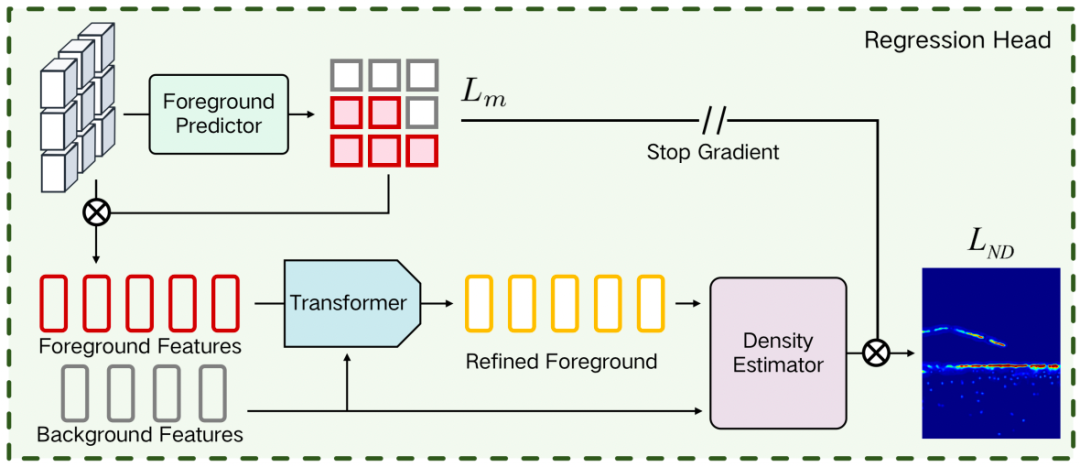
图 3 特征提取与密度回归结构图,其中Transformer 结构仅对前景特征进行细化
最后,我们设计了一种噪声抑制贝叶斯损失以尽量减少标注噪声对计数模型的负面影响。我们认为,当模型预测的密度值与标注密度值之间的差距过大时,标签中可能存在噪声。因此,我们添加一个调节因子来减轻这些大差距的权重,损失写作
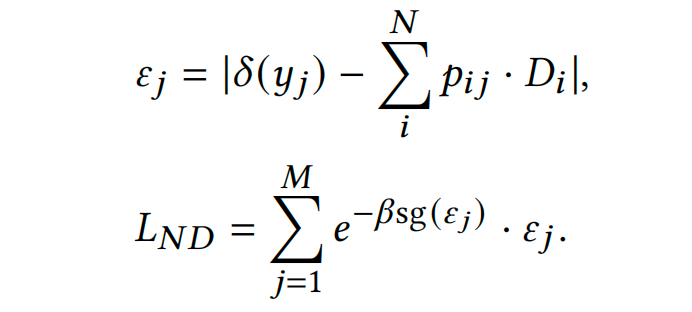
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢