
作者:Haike Xu, Zongyu Lin, Jing Zhou,等
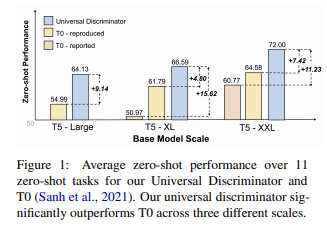
简介:本文提出以通用鉴别器来挑战零样本生成方法。生成模型已经成为大规模预训练和零样本泛化的主要方法。在这项工作中,作者通过证明在大量NLP任务中歧视性方法的表现明显优于生成性方法来挑战这一惯例。从技术上讲,作者训练单个鉴别器来预测文本样本是否来自真实的数据分布(类似于GAN)。由于许多NLP任务可以公式化为从多个选项中进行选择,因此作者使用该鉴别器来预测具有最高概率的选项。这种简单的公式在T0基准上实现了最先进的零样本结果,在不同尺度上分别比T0高16.0%、7.8%和11.5%。在微调设置中,作者的方法在广泛的NLP任务上也取得了新的SOTA结果、同时只有先前方法的1/4参数。同时,作者的方法只需要最小的Prompt提示努力,这在很大程度上提高了健壮性、对现实应用程序至关重要。此外,作者还结合生成性任务联合训练了广义通用鉴别器(在区分性任务上保持优势、同时在生成性任务上工作)。
论文下载:https://arxiv.org/pdf/2211.08099.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢