
【标题】The In-Sample Softmax for Offline Reinforcement Learning
【发表日期】2022.9.22
【论文链接】https://openreview.net/pdf?id=u-RuvyDYqCM
【推荐理由】强化学习 (RL) 智能体可以利用以前收集的成批数据来提取合理的控制策略。 然而,在这种离线 RL 设置中出现的一个新问题是,作为许多方法基础的引导更新存在动作覆盖不足的问题:标准最大运算符可能会选择数据集中未见的最大动作。 从这些不准确的值中引导可能会导致高估甚至分歧。 越来越多的方法试图逼近样本内最大值,这些方法仅使用数据集覆盖良好的动作。 本文强调一个简单的事实:仅使用数据集中的动作来近似样本内 softmax 更为直接。 作者表明基于样本内 softmax 的策略迭代收敛,并且对于降低温度它接近样本内最大值。 本文使用这个样本内 softmax 推导出一个样本内 Actor-Critic (AC),并表明它始终优于现有的离线 RL 方法或与现有的离线 RL 方法相当,并且也非常适合微调。
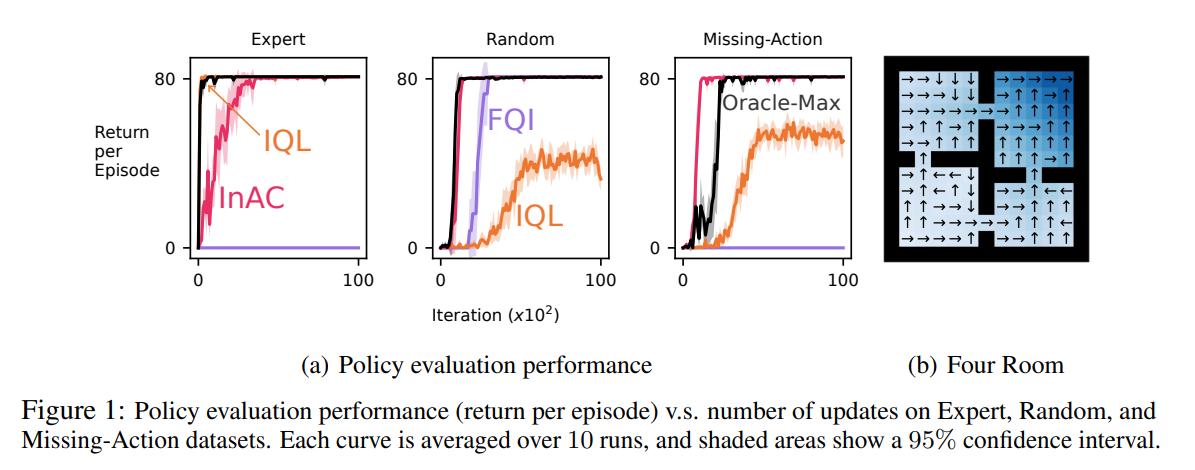
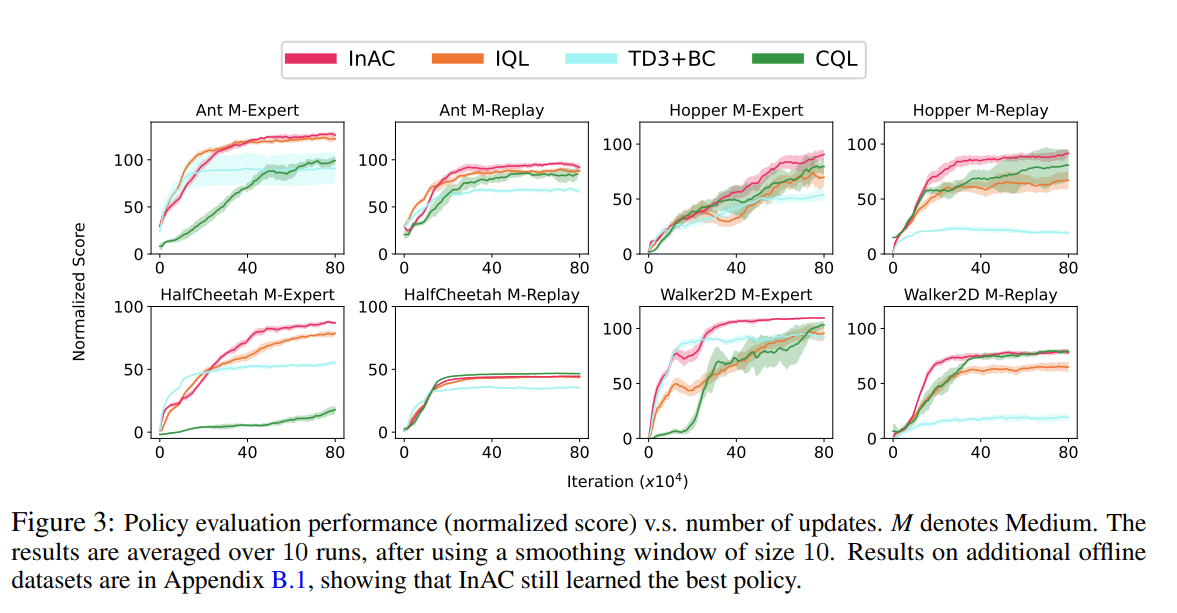
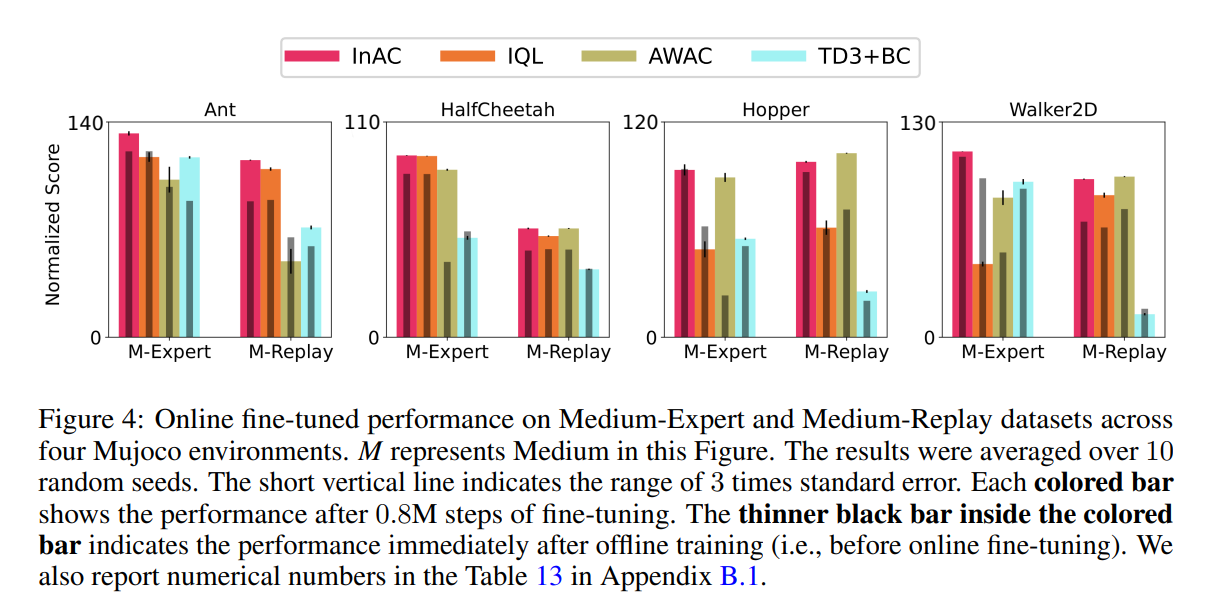
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢