
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 GR - 图形学
摘要:面向风格化物理角色控制的对抗运动先验、面向物理模拟人物的大规模可复用对抗技能嵌入、用分层混合专家学习足球花式技巧、不同模态Transformer预训练对离线强化学习的影响研究、深度生成模型流形过拟合问题的诊断和修复、基本语言任务的语言模型基准、基于自然语言补丁的模型错误修复、通过跨模态Grounding发现视频可访问性问题、用基于压缩的事后编辑提高摘要事实一致性
1、[GR] AMP: Adversarial Motion Priors for Stylized Physics-Based Character Control
X B Peng, Z Ma, P Abbeel, S Levine, A Kanazawa
[UC Berkeley & Shanghai Jiao Tong University]
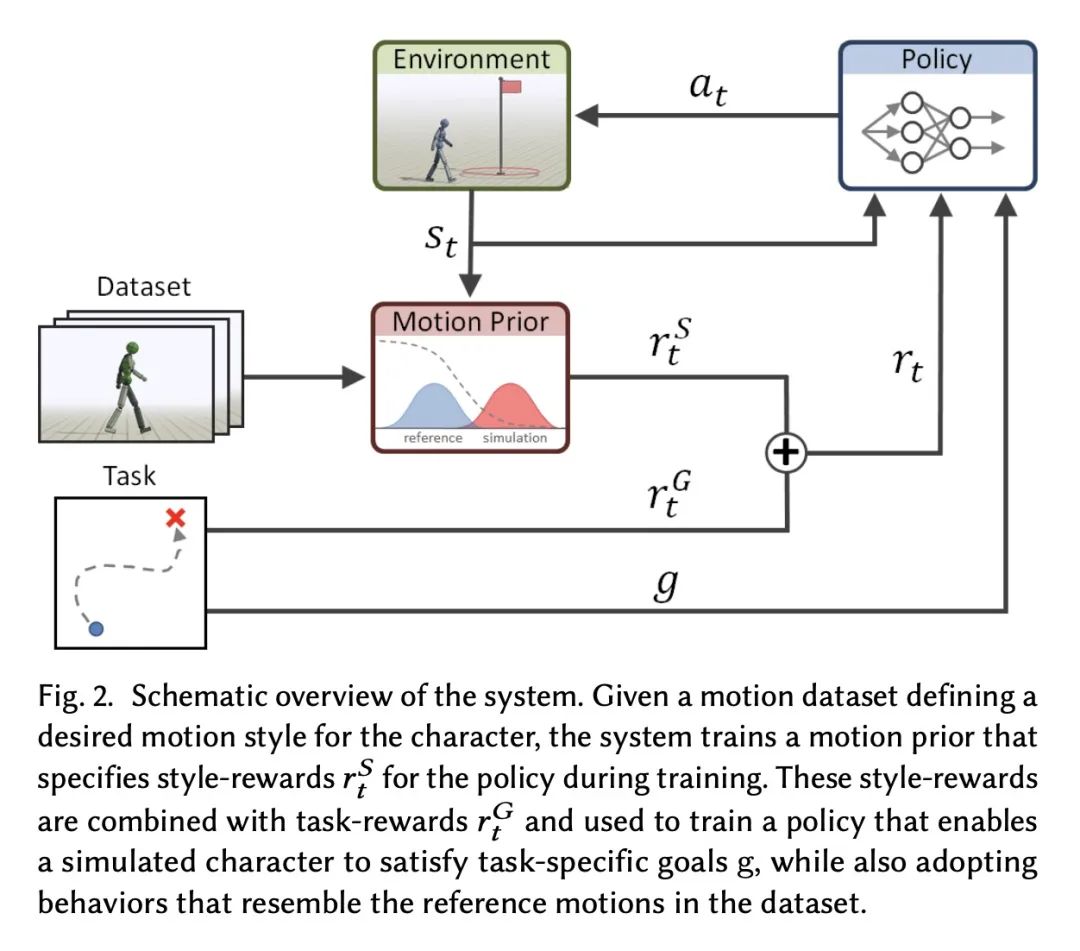
AMP: 面向风格化物理角色控制的对抗运动先验。为物理模拟角色合成优雅的、栩栩如生的行为,是计算机动画的一个基本挑战。利用运动跟踪的数据驱动方法是一类突出的技术,可以为广泛的行为产生高保真的运动。然而,这些基于跟踪的方法的有效性往往取决于精心设计的目标函数,当应用于大型和多样化的运动数据集时,这些方法需要大量的额外机制为角色选择适当的运动来跟踪给定场景。本文建议通过利用基于对抗模仿学习的完全自动化方法来避免手动设计模仿目标和运动选择机制的需要。角色应该执行的高层次任务目标可以由相对简单的奖励函数指定,而角色行为的低层次风格可以由非结构化的运动片段数据集指定,不需要任何明确的片段选择或排序。这些运动片段被用来训练一个对抗运动先验,通过强化学习(RL)来指定训练角色的风格奖励。对抗强化学习程序自动选择要执行的运动,动态地从数据集中插值和泛化。所提出系统产生了高质量的运动,可与最先进的基于跟踪的技术相媲美,同时也能够轻松地适应非结构化运动片段的大型数据集。不同技能的组合从运动先验中自动出现,而不需要高级运动规划器或其他特定任务的运动片段标注。在各种复杂的模拟人物和一套具有挑战性的运动控制任务上证明了所提出框架的有效性。
Synthesizing graceful and life-like behaviors for physically simulated characters has been a fundamental challenge in computer animation. Data-driven methods that leverage motion tracking are a prominent class of techniques for producing high fidelity motions for a wide range of behaviors. However, the effectiveness of these tracking-based methods often hinges on carefully designed objective functions, and when applied to large and diverse motion datasets, these methods require significant additional machinery to select the appropriate motion for the character to track in a given scenario. In this work, we propose to obviate the need to manually design imitation objectives and mechanisms for motion selection by utilizing a fully automated approach based on adversarial imitation learning. High-level task objectives that the character should perform can be specified by relatively simple reward functions, while the low-level style of the character's behaviors can be specified by a dataset of unstructured motion clips, without any explicit clip selection or sequencing. These motion clips are used to train an adversarial motion prior, which specifies style-rewards for training the character through reinforcement learning (RL). The adversarial RL procedure automatically selects which motion to perform, dynamically interpolating and generalizing from the dataset. Our system produces high-quality motions that are comparable to those achieved by state-of-the-art tracking-based techniques, while also being able to easily accommodate large datasets of unstructured motion clips. Composition of disparate skills emerges automatically from the motion prior, without requiring a high-level motion planner or other task-specific annotations of the motion clips. We demonstrate the effectiveness of our framework on a diverse cast of complex simulated characters and a challenging suite of motor control tasks.
https://arxiv.org/abs/2104.02180


2、[GR] ASE: Large-Scale Reusable Adversarial Skill Embeddings for Physically Simulated Characters
X B Peng, Y Guo, L Halper, S Levine, S Fidler
[UC Berkeley & NVIDIA & University of Toronto]
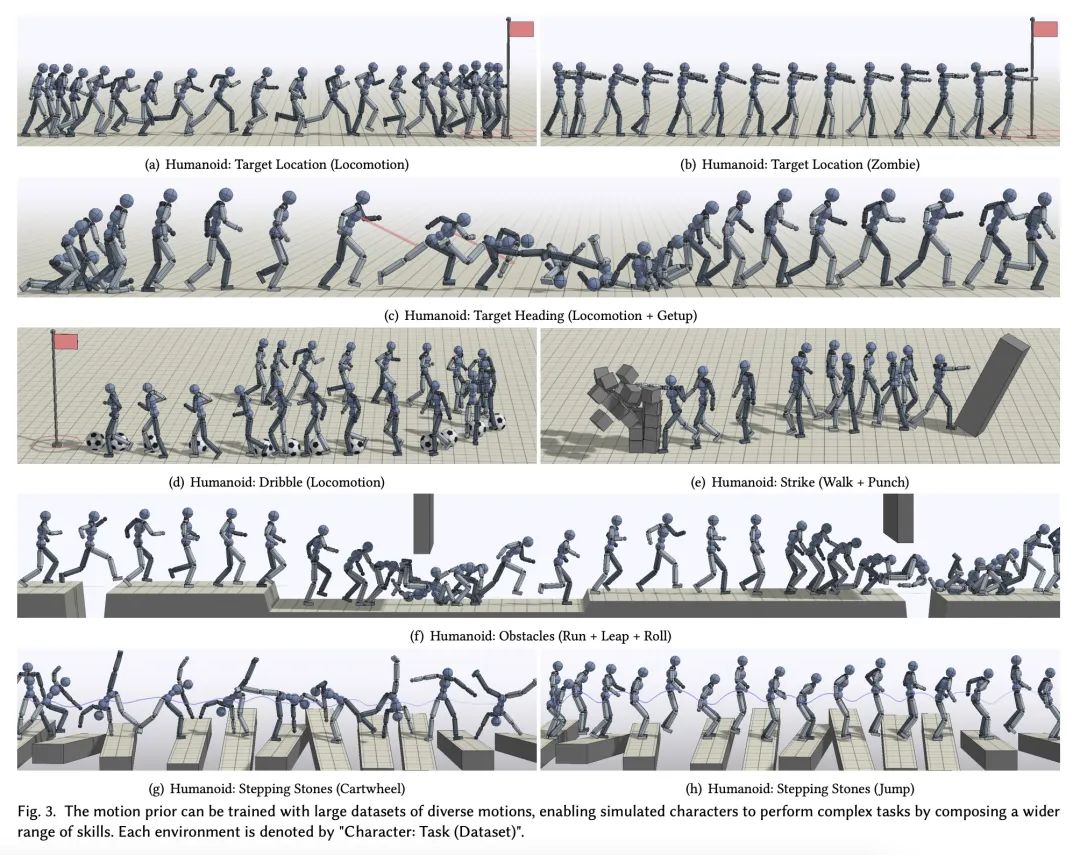
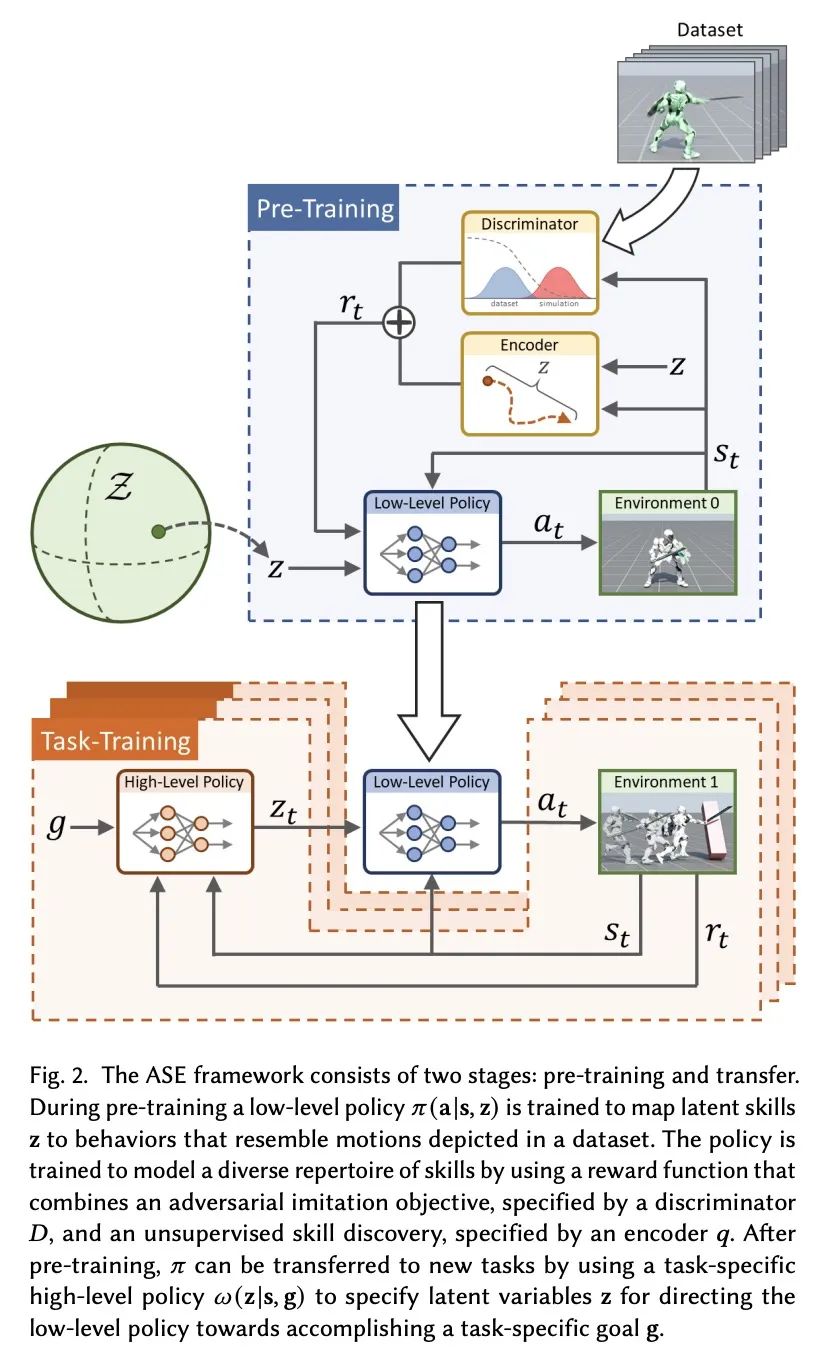
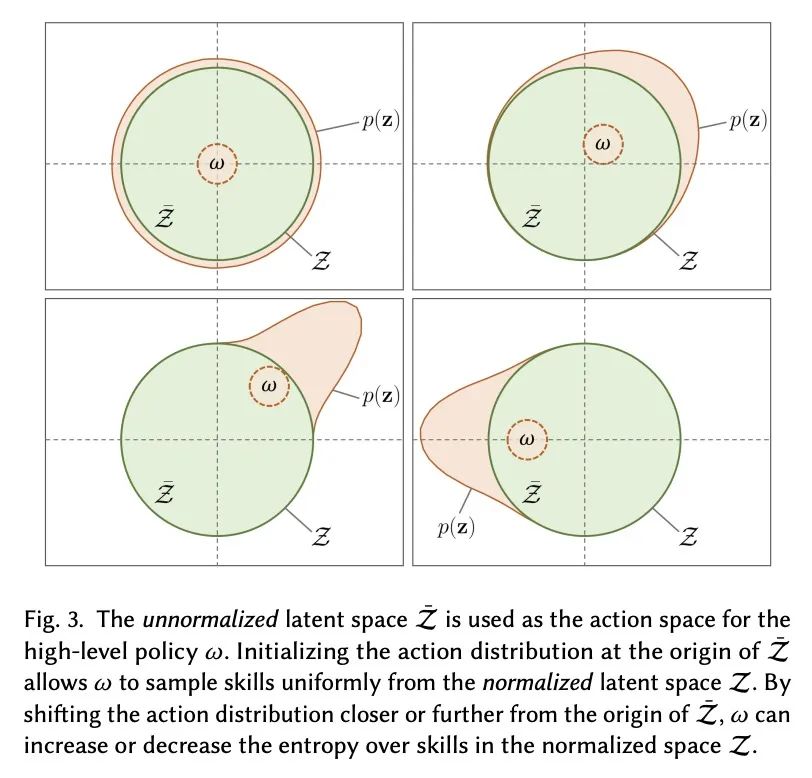
ASE:面向物理模拟人物的大规模可复用对抗技能嵌入。人类所表现出的令人难以置信的运动能力,部分是通过多年的练习和经验获得的大量通用运动技能而实现的。这些技能不仅使人类能够完成复杂的任务,而且在学习新任务时为指导他们的行为提供了强有力的先验。这与物理角色动画的通常做法形成鲜明对比,在这种情况下,控制策略通常是为每个任务从头开始训练的。本文提出了一种大规模数据驱动框架,用于学习物理模拟角色的多功能和可复用的技能嵌入。该方法结合了对抗模仿学习和无监督强化学习的技术来开发技能嵌入,以产生栩栩如生的行为,同时也为新的下游任务提供一个易于控制的表示。该模型可以使用非结构化运动片段的大型数据集进行训练,不需要任何特定任务的标注或运动数据的分割。通过利用大规模并行的基于GPU的模拟器,能使用超过十年的模拟经验来训练技能嵌入,使模型能学习到丰富而多样的技能。一个预训练好的模型可以有效地应用于执行各种新的任务。该系统还允许用户通过简单的奖励函数指定任务,然后技能嵌入使角色能够自动合成复杂和自然的策略,以实现任务目标。
The incredible feats of athleticism demonstrated by humans are made possible in part by a vast repertoire of general-purpose motor skills, acquired through years of practice and experience. These skills not only enable humans to perform complex tasks, but also provide powerful priors for guiding their behaviors when learning new tasks. This is in stark contrast to what is common practice in physics-based character animation, where control policies are most typically trained from scratch for each task. In this work, we present a large-scale data-driven framework for learning versatile and reusable skill embeddings for physically simulated characters. Our approach combines techniques from adversarial imitation learning and unsupervised reinforcement learning to develop skill embeddings that produce life-like behaviors, while also providing an easy to control representation for use on new downstream tasks. Our models can be trained using large datasets of unstructured motion clips, without requiring any task-specific annotation or segmentation of the motion data. By leveraging a massively parallel GPU-based simulator, we are able to train skill embeddings using over a decade of simulated experiences, enabling our model to learn a rich and versatile repertoire of skills. We show that a single pre-trained model can be effectively applied to perform a diverse set of new tasks. Our system also allows users to specify tasks through simple reward functions, and the skill embedding then enables the character to automatically synthesize complex and naturalistic strategies in order to achieve the task objectives.
https://arxiv.org/abs/2205.01906


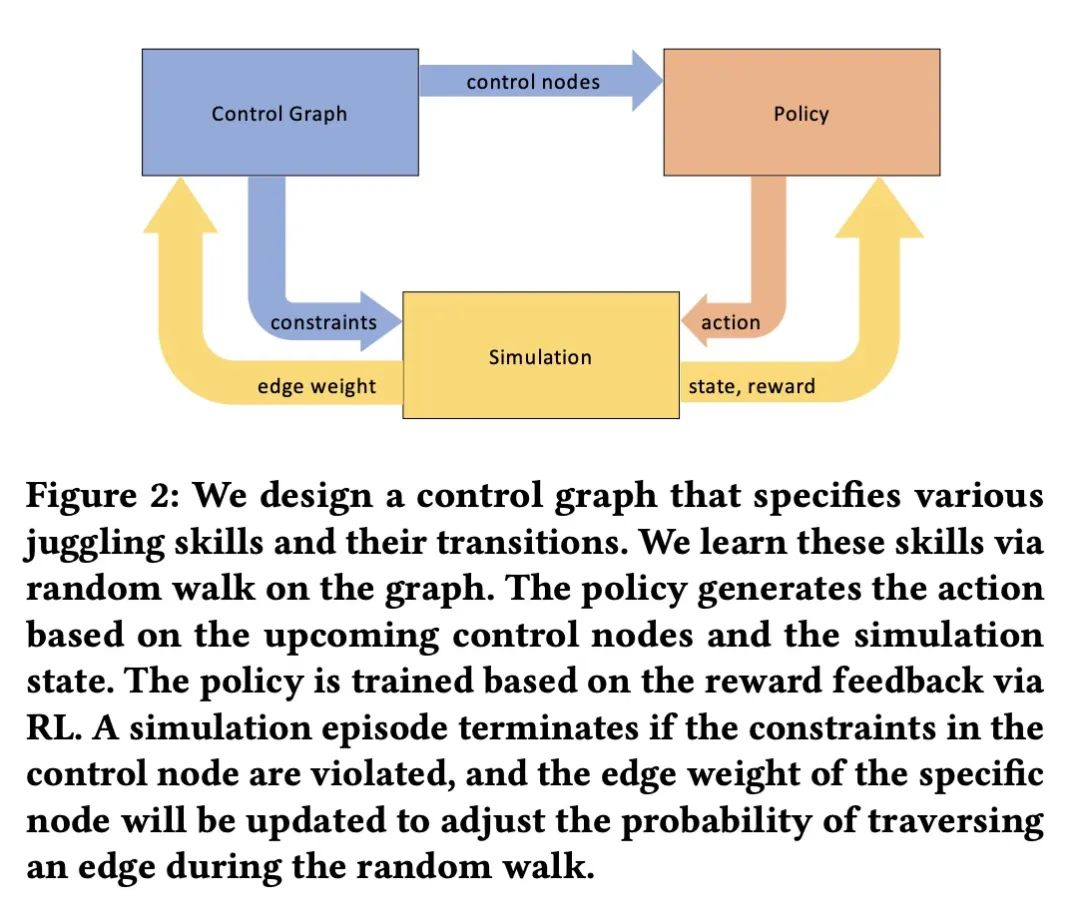
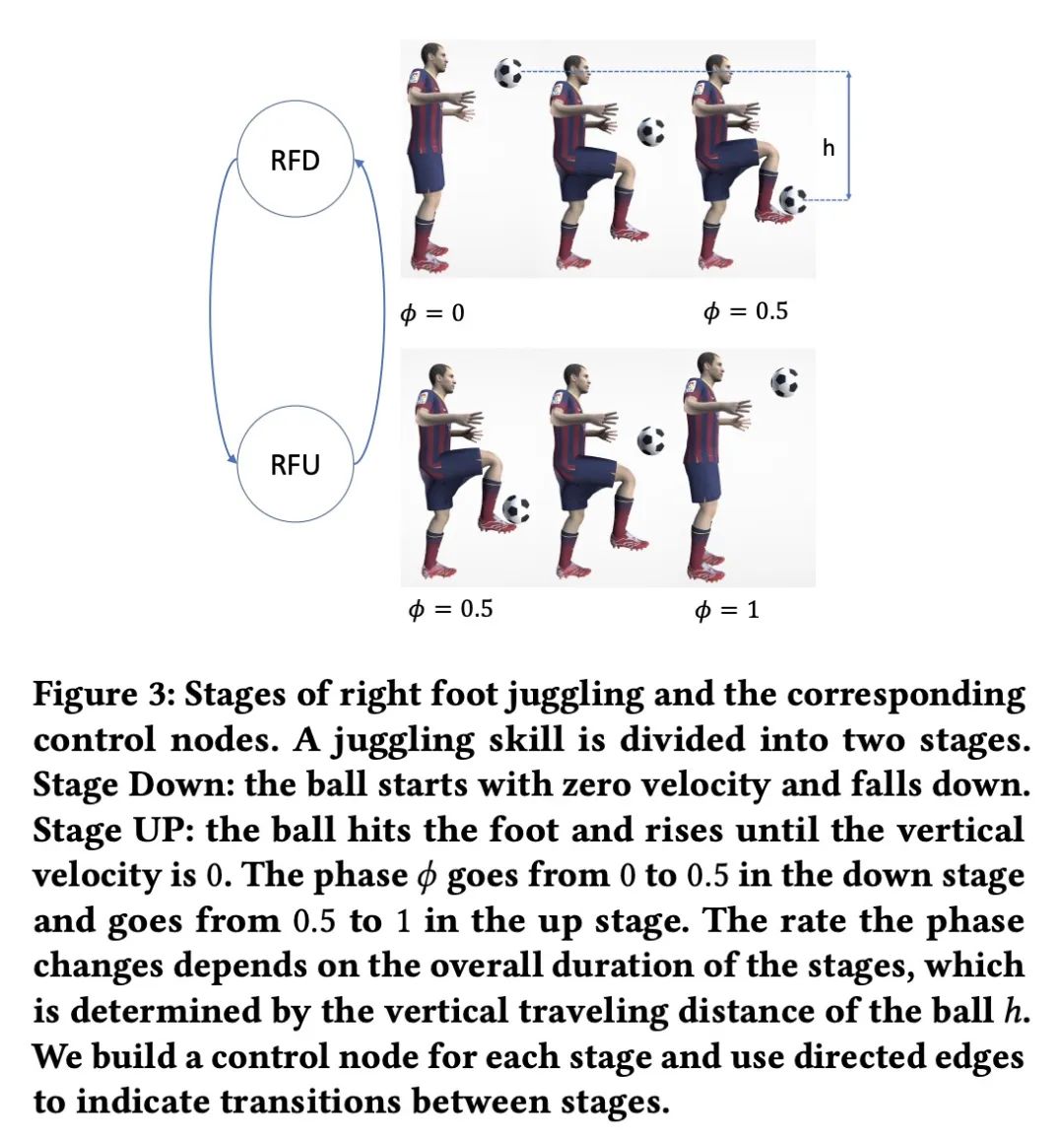
3、[LG] Learning Soccer Juggling Skills with Layer-wise Mixture-of-Experts
Z Xie, S Starke, HY Ling, M van de Panne
[University of British Columbia & University of Edinburgh]
用分层混合专家学习足球花式技巧。学习基于物理学角色控制器,用单一的策略成功地整合各种运动技能,仍然是一个具有挑战性的问题。本文提出一种基于深度强化学习的系统,用于学习多种足球花式技巧的控制策略。为这些技能提出一个任务描述框架,有助于规范单个足球花式任务和它们之间的转换。期望的动作可以通过插值粗略的参考姿态或基于运动捕捉数据来编写。一个分层的专家混合架构提供了显著的好处。在训练过程中,在自适应随机游走的帮助下选择过渡,以支持高效学习。本文展示了脚、头、膝盖和胸部的花样、脚的停顿、具有挑战性的巡回技巧,以及鲁棒的转换。本文工作为实现基于物理的角色提供了重要的一步,使其能够具备人类运动员的精确运动技能。
Learning physics-based character controllers that can successfully integrate diverse motor skills using a single policy remains a challenging problem. We present a system to learn control policies for multiple soccer juggling skills, based on deep reinforcement learning. We introduce a task-description framework for these skills which facilitates the specification of individual soccer juggling tasks and the transitions between them. Desired motions can be authored using interpolation of crude reference poses or based on motion capture data. We show that a layer-wise mixtureof-experts architecture offers significant benefits. During training, transitions are chosen with the help of an adaptive random walk, in support of efficient learning. We demonstrate foot, head, knee, and chest juggles, foot stalls, the challenging around-the-world trick, as well as robust transitions. Our work provides a significant step towards realizing physics-based characters capable of the precision-based motor skills of human athletes. Code is available at https://github.com/ZhaomingXie/soccer_juggle_release. https://cs.ubc.ca/~van/papers/2022-SIGGRAPH-juggle/soccer_juggling.pdf


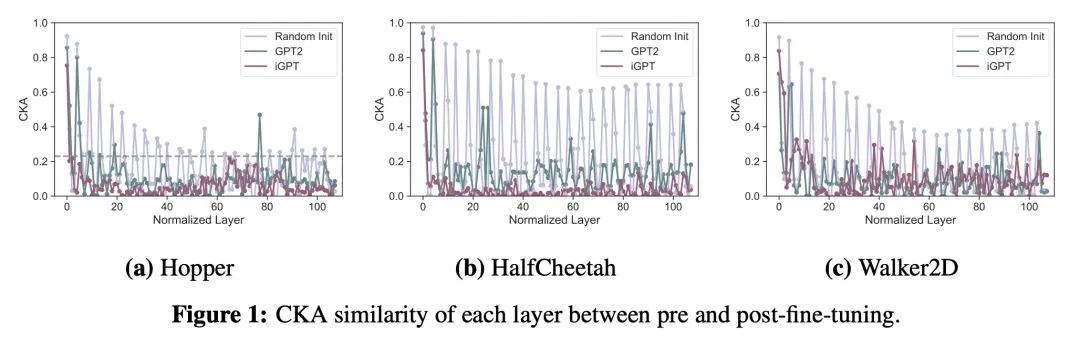
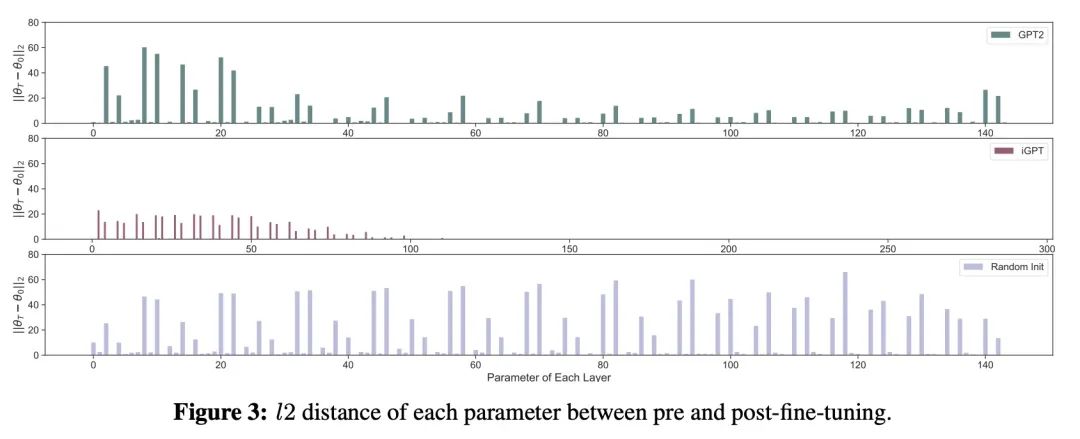
4、[LG] On the Effect of Pre-training for Transformer in Different Modality on Offline Reinforcement Learning
S Takagi (2022)
不同模态Transformer预训练对离线强化学习的影响研究。本文实证研究了不同模态数据(如语言和视觉)的预训练如何影响基于Transformer的模型对Mujoco离线强化学习任务的微调。对内部表示的分析显示,预训练的Transformer在预训练前后获得的表示基本不同,但在微调中获得的数据信息比随机初始化的要少。仔细观察预训练Transformer的参数变化,发现它们的参数变化不大,用图像数据预训练的模型的不良表现可能部分来自大梯度和梯度裁剪。为了研究用语言数据预训练的Transformer利用了哪些信息,在不提供上下文的情况下对该模型进行了微调,发现即使没有上下文信息,模型也能有效地学习。随后的跟踪分析支持了这样的假设:用语言数据进行预训练有可能使Transformer获得类似于上下文的信息并利用它来解决下游的任务。
We empirically investigate how pre-training on data of different modalities, such as language and vision, affects fine-tuning of Transformer-based models to Mujoco offline reinforcement learning tasks. Analysis of the internal representation reveals that the pre-trained Transformers acquire largely different representations before and after pre-training, but acquire less information of data in fine-tuning than the randomly initialized one. A closer look at the parameter changes of the pre-trained Transformers reveals that their parameters do not change that much and that the bad performance of the model pre-trained with image data could partially come from large gradients and gradient clipping. To study what information the Transformer pre-trained with language data utilizes, we fine-tune this model with no context provided, finding that the model learns efficiently even without context information. Subsequent follow-up analysis supports the hypothesis that pre-training with language data is likely to make the Transformer get context-like information and utilize it to solve the downstream task.
https://openreview.net/forum?id=9GXoMs__ckJ

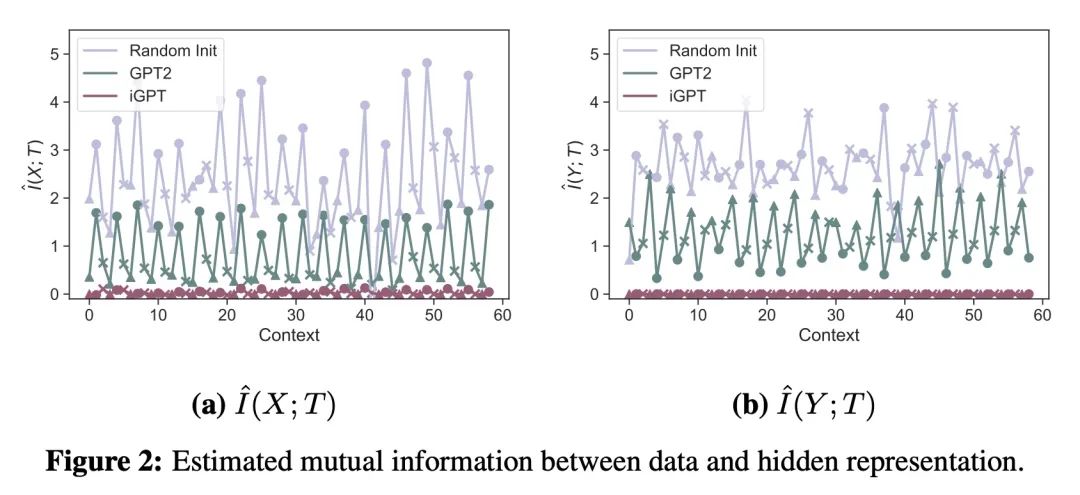
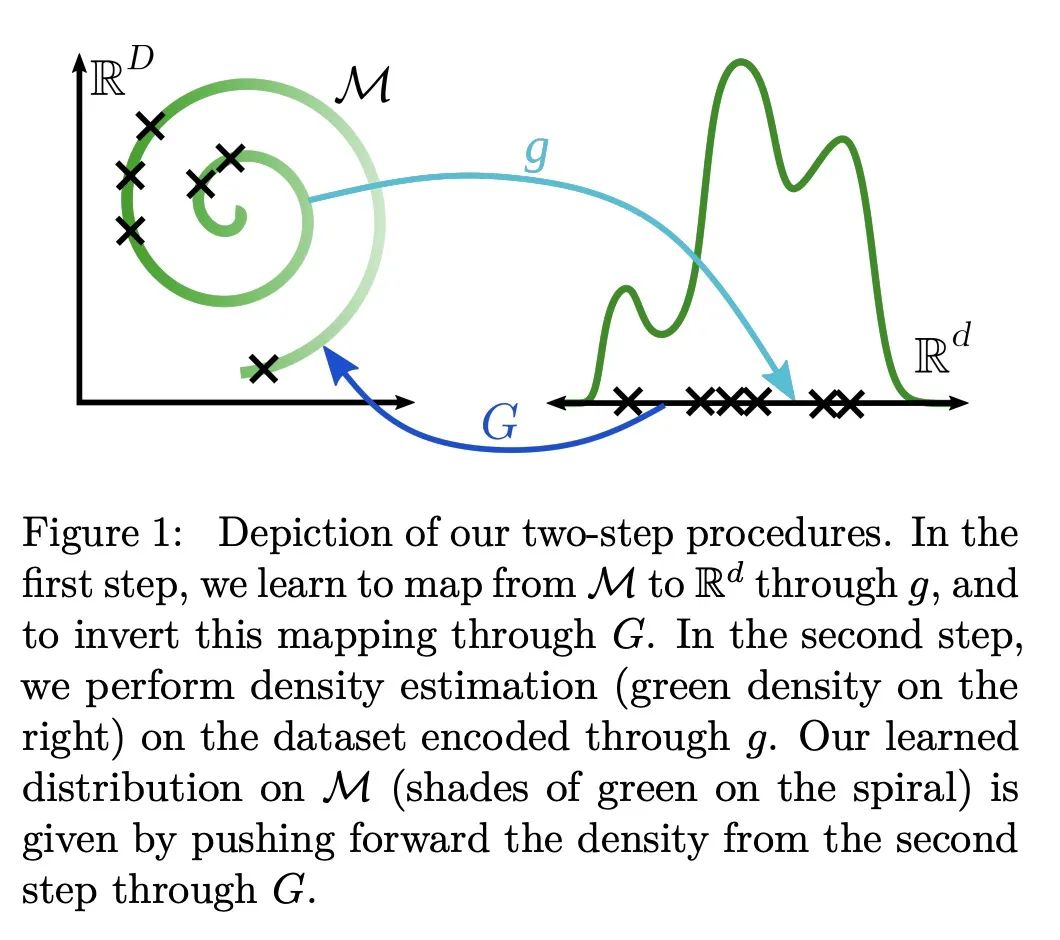
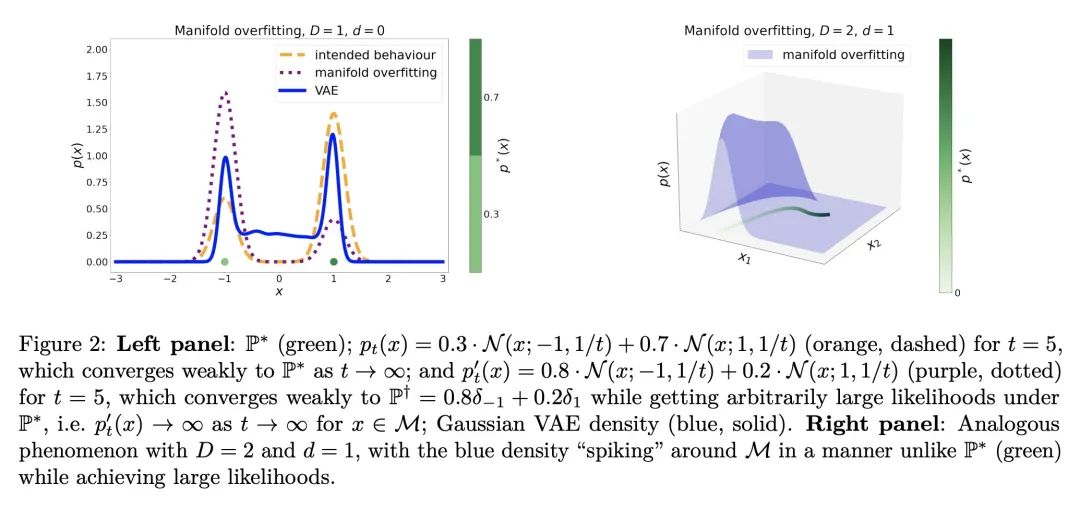
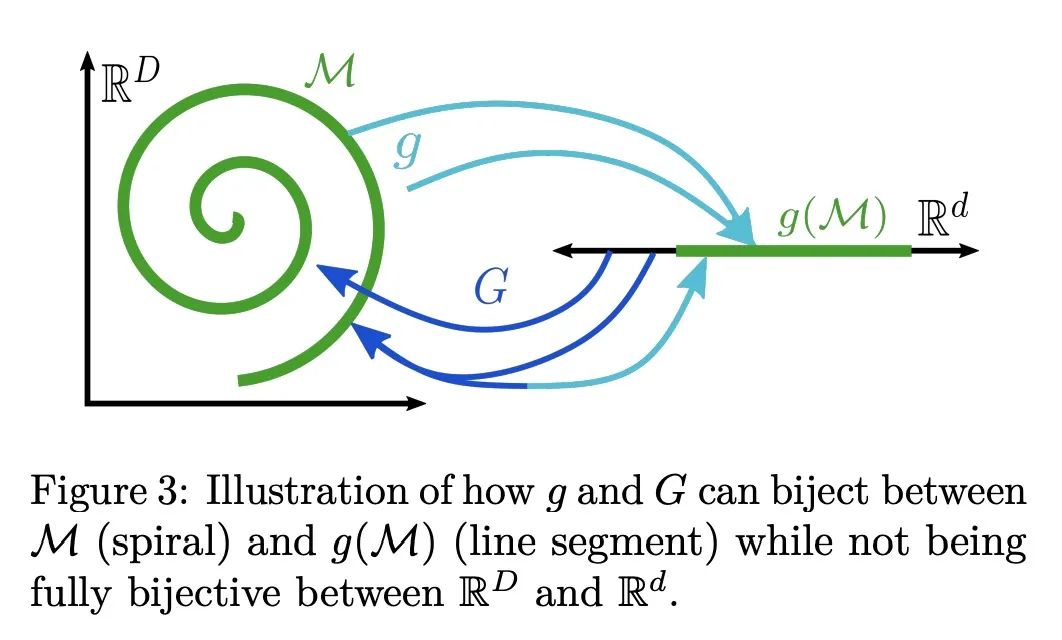
5、[LG] Diagnosing and Fixing Manifold Overfitting in Deep Generative Models
G Loaiza-Ganem, B L Ross, J C. Cresswell, A L. Caterini
[Layer 6 AI]
深度生成模型流形过拟合问题的诊断和修复。基于似然,或显式地,深度生成模型用神经网络来构建灵活的高维密度。这种表述直接违背了流形假说,即观察到的数据位于嵌入高维环境空间的低维流形上。本文研究了在这种维度不匹配的情况下最大似然训练的病态。本文正式证明,在流形本身被学习但流形上的分布没有被学习的情况下,会达到退化的最优状态,这种现象称为流形过拟合。本文提出了一类由降维步骤和最大似然密度估计组成的两步程序,并证明它们能在非参数系统中恢复数据生成的分布,从而避免流形过拟合。本文还表明,这些程序能对隐含模型学到的流形进行密度估计,例如生成对抗网络,从而解决了这些模型的一个主要缺陷。最近提出的一些方法是所述两步程序的实例;因此本文统一、扩展并在理论上证明了一大类模型。
Likelihood-based, or explicit, deep generative models use neural networks to construct flexible high-dimensional densities. This formulation directly contradicts the manifold hypothesis, which states that observed data lies on a low-dimensional manifold embedded in high-dimensional ambient space. In this paper we investigate the pathologies of maximum-likelihood training in the presence of this dimensionality mismatch. We formally prove that degenerate optima are achieved wherein the manifold itself is learned but not the distribution on it, a phenomenon we call manifold overfitting. We propose a class of two-step procedures consisting of a dimensionality reduction step followed by maximum-likelihood density estimation, and prove that they recover the data-generating distribution in the nonparametric regime, thus avoiding manifold overfitting. We also show that these procedures enable density estimation on the manifolds learned by implicit models, such as generative adversarial networks, hence addressing a major shortcoming of these models. Several recently proposed methods are instances of our two-step procedures; we thus unify, extend, and theoretically justify a large class of models.
https://openreview.net/forum?id=0nEZCVshxS

另外几篇值得关注的论文:
[CL] LMentry: A Language Model Benchmark of Elementary Language Tasks
LEntry:基本语言任务的语言模型基准
A Efrat, O Honovich, O Levy
[Tel Aviv University]
https://arxiv.org/abs/2211.02069


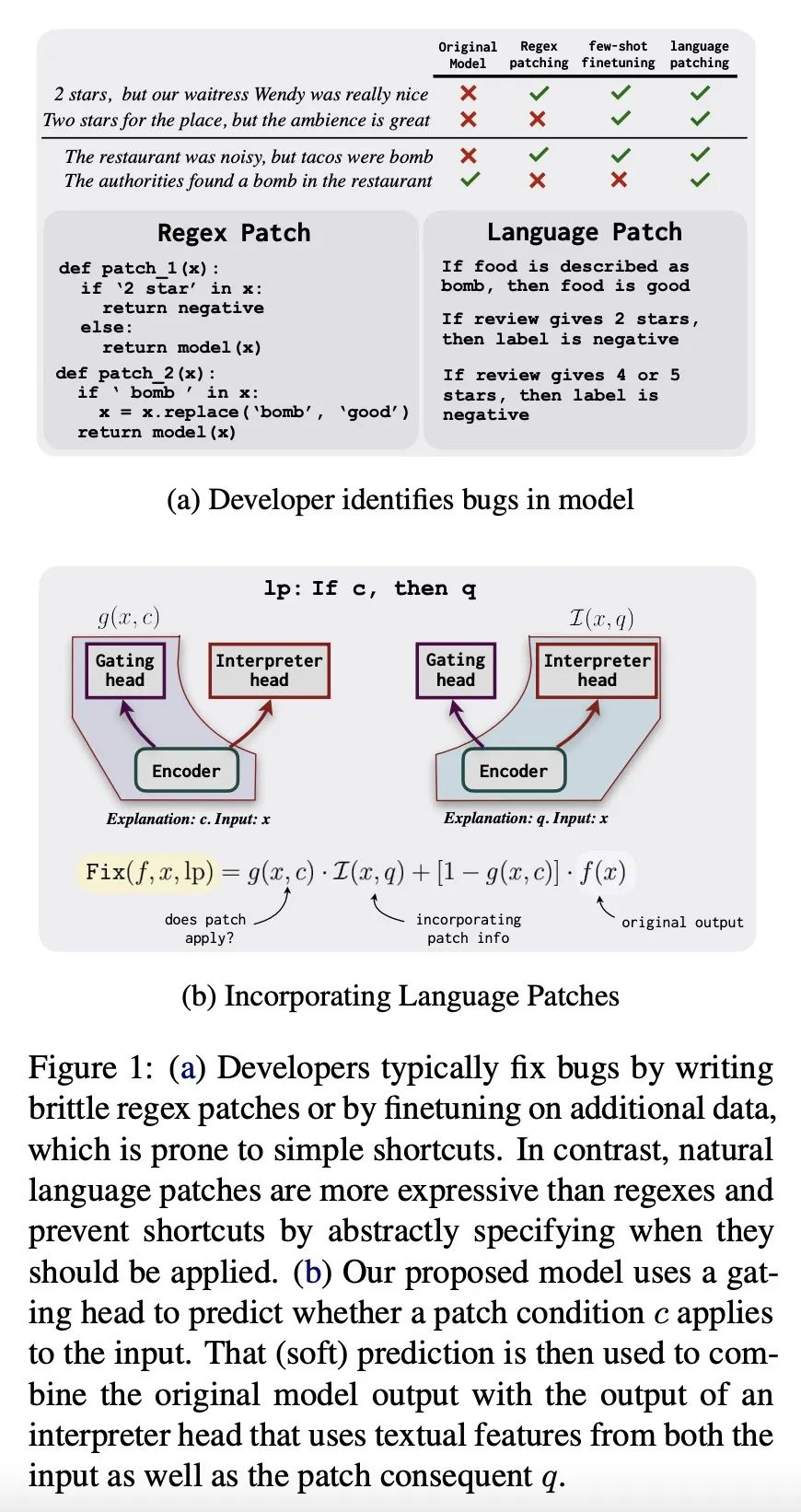
[CL] Fixing Model Bugs with Natural Language Patches
基于自然语言补丁的模型错误修复
S Murty, C D. Manning, S Lundberg, M T Ribeiro
[Stanford University & Microsoft Research]
https://arxiv.org/abs/2211.03318



[LG] CrossA11y: Identifying Video Accessibility Issues via Cross-modal Grounding
CrossA11y:通过跨模态Grounding发现视频可访问性问题
XB Liu, R Wang, D Li, XA Chen, A Pavel
[UCLA & Adobe Research & The University of Texas at Austin]
https://dl.acm.org/doi/abs/10.1145/3526113.3545703




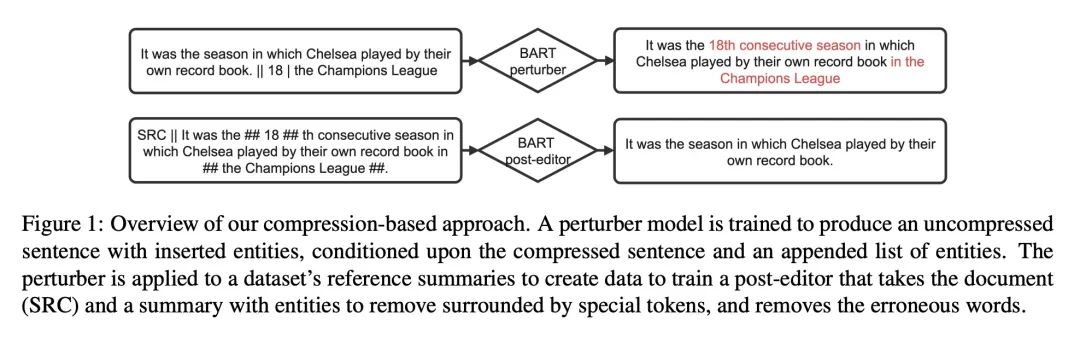
[CL] Improving Factual Consistency in Summarization with Compression-Based Post-Editing
用基于压缩的事后编辑提高摘要事实一致性
A R. Fabbri, P K Choubey, J Vig, C Wu, C Xiong
[Salesforce AI Research]
https://arxiv.org/abs/2211.06196

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢