
在前的文章 《知识图谱落地不可回避的重头戏:文档版面分析关键技术、开放数据与开源组件概述》 中,我们从知识图谱在工业界落地中受忽视的一环、文档版面分析关键技术与数据集、现有开放可用的工具模型三个方向进行了版面分析在知识图谱构建环节中的重要性。
而进一步的,我们可以看到,目前很多pdf文档中包含了包括图片、表格等丰富的信息,例如,财务报表、技术报告、学术期刊和各种论文等带有大量绘制图表信息的文档,经常采用PDF格式保存,PDF内容提取版时应避免图表文字混入正文,或针对图表数据做进一步分析处理,都需要识别图表信息。
而完整地将表格、图片区域进行识别,并进行分离,可以支持多种应用场景,例如研报、年报中有大量的图片,如果进行提取,可以进行图片定位和搜索,通过对产业链研报的解析,还可以为产业链构建提供支撑。
因此,本文主要围绕PDF图片提取这一任务,从PDF区域bouding box坐标识别、PDF文件向图片转换以及PDF文件图片提取三个方面进行论述,供大家一起参考。
一、PDF区域bouding box坐标识别
PDF区域boudingbox是当前PDF分析的一个重要组成部分,通过给定一个pdf文档,需要从中找到对应的区域以及其位于pdf的坐标,下面介绍几个代表方法:
1、基于pdfminer获取区域的bounding box
pdfminer是一个Python的PDF解析器,用于从PDF文档中提取信息,它专注于获取和分析文本数据。PDFMiner允许获取某一页中文本的准确位置和一些诸如字体、行数的信息。基于PDFminer的图表识别提取不需要准备数据集、花费大量时间去打标训练,也不需要高占用GPU,识别速度快,对于机器性能的要求较低,对于大多数的报告文件都具有适用性。
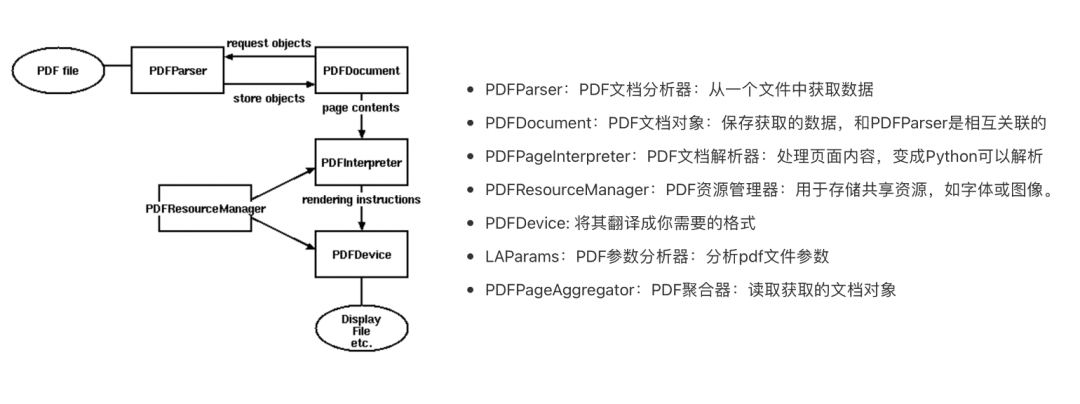
布局分析返回的PDF文档中的每个页面LTPage对象。这个对象和页内包含的子对象,形成一个树结构,如图所示:
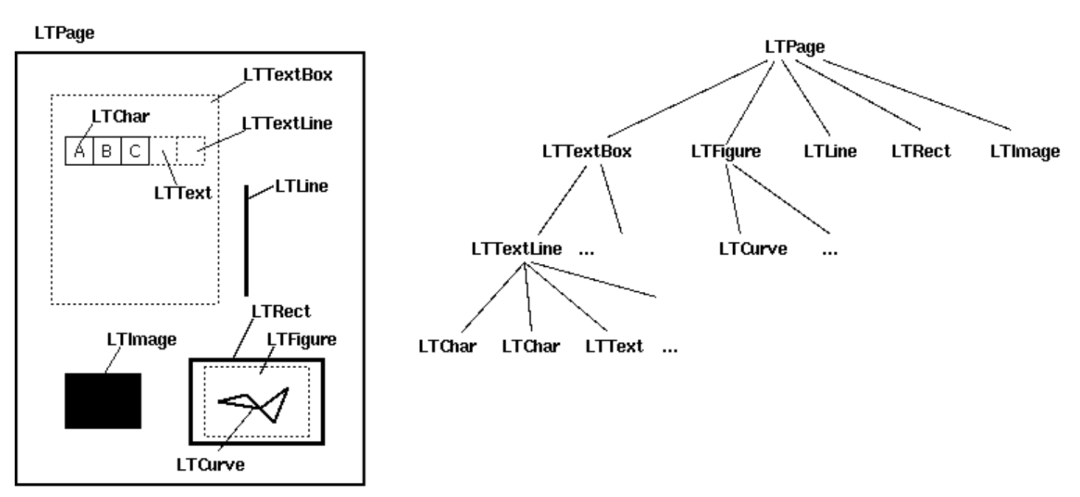
layout是一个LTPage对象 里面存放着 这个page解析出的各种对象 一般包括LTTextBox, LTFigure, LTImage, LTTextBoxHorizontal等,其中:
-
LTPage:表示整个页。可能会含有LTTextBox,LTFigure,LTImage,LTRect,LTCurve和LTLine子对象;
-
LTTextBox:表示一组文本块可能包含在一个矩形区域。此box是由几何分析中创建,并且不一定表示该文本的一个逻辑边界,包含LTTextLine对象的列表;
-
LTTextLine:包含表示单个文本行LTChar对象的列表。字符对齐要水平或垂直,取决于文本的写入模式;
-
LTAnno:在文本中实际的字母表示为Unicode字符串; LTAnno对象没有,因为这些是“虚拟”的字符,根据两个字符间的关系(例如,一个空格)由布局分析后插入;
-
LTImage:表示一个图像对象。嵌入式图像可以是JPEG或其它格式,但是目前PDFMiner没有放置太多精力在图形对象;
-
LTLine:代表一条直线。可用于分离文本或附图;
-
LTRect:表示矩形。可用于框架的另一图片或数字;
-
LTCurve:表示一个通用的Bezier曲线;
# bbox:
# x0:从页面左侧到框左边缘的距离。
# y0:从页面底部到框的下边缘的距离。
# x1:从页面左侧到方框右边缘的距离。
# y1:从页面底部到框的上边缘的距离
from pdfminer.pdfparser import PDFParser
from pdfminer.pdfdocument import PDFDocument
from pdfminer.pdfpage import PDFPage
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.pdfpage import PDFTextExtractionNotAllowed
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LTTextBoxHorizontal, LAParams, LTImage, LTFigure, LTLine,LTRect
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
def parse(pdf_path):
fp = open(pdf_path, 'rb') # 以二进制读模式打开
parser = PDFParser(fp)
doc = PDFDocument(parser)
if not doc.is_extractable:
raise PDFTextExtractionNotAllowed
else:
# 创建PDf 资源管理器 来管理共享资源
rsrcmgr = PDFResourceManager()
# 创建一个PDF设备对象
laparams = LAParams()
device = PDFPageAggregator(rsrcmgr, laparams=laparams)
# 创建一个PDF解释器对象
interpreter = PDFPageInterpreter(rsrcmgr, device)
# 循环遍历列表,每次处理一个page的内容
for i, page in enumerate(PDFPage.create_pages(doc)):
datas = []
interpreter.process_page(page)
# 接受该页面的LTPage对象
layout = device.get_result()
# 这里layout是一个LTPage对象 里面存放着 这个page解析出的各种对象 一般包括LTTextBox, LTFigure, LTImage, LTTextBoxHorizontal 等等 想要获取文本就获得对象的text属性,
for x in layout:
data = {"page_idx":i, "label":str(type(x)),"pos":list(x.bbox)}
print(data)2、基于pp structure获取区域的bounding box
pp structure给出了一个版面分析方法下的bounding box坐标提取方法,通过publayout版面分析,可以得到各个区域的坐标信息。
import os
import cv2
from paddleocr import PPStructure,draw_structure_result,save_structure_res
table_engine = PPStructure(show_log=True, image_orientation=True)
save_folder = './output'
img_path = 'ppstructure/docs/table/1.png'
img = cv2.imread(img_path)
result = table_engine(img)
save_structure_res(result, save_folder,os.path.basename(img_path).split('.')[0])三、PDF文件向图片转换
PDF转换为图片,是我们进行版面分析的一个重要前置性步骤,给定一个PDF文件,需要根据每一页,将PDF进行切割,并转换为一定清晰度的图片集合。
目前,支持这一处理的包括pdfplumber以及pyMuPDF等,下面对实践脚本进行介绍。
1、基于pdfplumber进行图片转换
import pdfplumber
def pdf2img(pdf_path, img_dir):
pdf = pdfplumber.open(pdf_path)
for i, page in enumerate(pdf.pages):
first_page = pdf.pages[i]
## resolution用于控制图片转换后的清晰度,值越大,得到的文件越清晰
im = first_page.to_image(resolution=200)
im.save('%s/%s.jpg'%(img_dir, i) )
pdf.close()
return2、基于pyMuPDF进行图片转换
import fitz # fitz就是pip install PyMuPDF
def pdf2img(pdf_path, image_dir):
pdfDoc = fitz.open(pdf_path)
for pg in range(pdfDoc.pageCount):
page = pdfDoc[pg]
rotate = int(0)
# 每个尺寸的缩放系数为4,这将为我们生成分辨率提高4的图像。
# 此处若是不做设置,默认图片大小为:792X612, dpi=96
zoom_x = 4 # (1.33333333-->1056x816) (2-->1584x1224)
zoom_y = 4
mat = fitz.Matrix(zoom_x, zoom_y).preRotate(rotate)
pix = page.getPixmap(matrix=mat, alpha=False)
if not os.path.exists(image_path): # 判断存放图片的文件夹是否存在
os.makedirs(image_path) # 若图片文件夹不存在就创建
pix.writePNG(image_path + '/' + 'images_%s.png' % pg) # 将图片写入指定的文件夹内三、PDF文件图片提取
与将PDF切割为图片不同,PDF文件图片提取旨在将PDF中所包含的图片进行分离,这种任务主要分成两种情况,一种是图片型的pdf,无法直接解析pdf文件本身,而是需要进行版式分析,如使用paddlpadlle ocr进行提取。另一种是非图片型pdf,可以通过解析pdf的内部元素构成来完成提取,如基于pyMuPDF、pdf2image等。
1、基于pyMuPDF进行图片提取
import fitz
import re
import os
def save_pdf_img(pdf_path, save_path):
# 使用正则表达式来查找图片
checkXO = r"/Type(?= */XObject)"
checkIM = r"/Subtype(?= */Image)"
# 打开pdf
doc = fitz.open(pdf_path)
# 图片计数
imgcount = 0
# 获取对象数量长度
lenXREF = doc.xref_length()
# 遍历每一个图片对象
for i in range(1, lenXREF):
text = doc.xref_object(i)
isXObject = re.search(checkXO, text)
# 使用正则表达式查看是否是图片
isImage = re.search(checkIM, text)
# 如果不是对象也不是图片,则continue
if not isXObject or not isImage:
continue
imgcount += 1
# 根据索引生成图像
pix = fitz.Pixmap(doc, i)
# 根据pdf的路径生成图片的名称
new_name = path.replace('\\', '_') + "_img{}.png".format(imgcount)
new_name = new_name.replace(':', '')
# 如果pix.n<5,可以直接存为PNG
if pix.n < 5:
pix.writePNG(os.path.join(save_path, new_name))
# 否则先转换CMYK
else:
pix0 = fitz.Pixmap(fitz.csRGB, pix)
pix0.writePNG(os.path.join(save_path, new_name))
pix0 = None
# 释放资源
pix = None2、基于pdf2image进行图片提取
from pdf2image import convert_from_path
pdf_path = "test.pdf"
save_path = "./imagefolder"
convert_from_path(
pdf_path=pdf_path, # 要转换的pdf的路径
dpi=200, # dpi中的图像质量(默认200)
output_folder=save_path, # 将生成的图像写入文件夹(而不是直接写入内存)#注意中文名的目录可能会出问题
first_page=None, # 要处理的第一页
last_page=None, # 停止前要处理的最后一页
fmt="png", # 输出图像格式
jpegopt=None, # jpeg选项“quality”、“progressive”和“optimize”(仅适用于jpeg格式)
thread_count=4, # 允许生成多少线程进行处理
userpw=None, # PDF密码
use_cropbox=False, # 使用cropbox而不是mediabox
strict=False, # 当抛出语法错误时,它将作为异常引发
transparent=False, # 以透明背景而不是白色背景输出。
single_file=False, # 使用pdftoppm/pdftocairo中的-singlefile选项
poppler_path=None, # 查找poppler二进制文件的路径
grayscale=False, # 输出灰度图像
size=None, # 结果图像的大小,使用枕头(宽度、高度)标准
paths_only=False, # 不加载图像,而是返回路径(需要output_文件夹)
use_pdftocairo=False, # 用pdftocairo而不是pdftoppm,可能有助于提高性能
timeout=None, # 超时
)3、基于pdfminer.six提取图片
地址:https://pdfminersix.readthedocs.io/en/latest/howto/images.html
pip install pdfminer.six
pdf2txt.py xxxx.pdf --output-dir save_path
4、基于paddleocr的图片提取
地址:https://aistudio.baidu.com/aistudio/projectdetail/2274897
import datetime
import os
import fitz
import cv2
import shutil
from paddleocr import PPStructure,draw_structure_result,save_structure_res
table_engine = PPStructure(show_log=True)
save_folder = './result'//图片保存地址
img_dir = './imgs'//pdf转换为img图片的地址
files = os.listdir(img_dir)
for fi in files:
fi_d = os.path.join(img_dir,fi)
# print(fi_d)
for img in os.listdir(fi_d):
img_path = os.path.join(fi_d,img)
img = cv2.imread(img_path)
result = table_engine(img)
# 保存在每张图片对应的子目录下
save_structure_res(result, os.path.join(save_folder,fi), os.path.basename(img_path).split('.')[0])总结
完整地将表格、图片区域进行识别,并进行分离,可以支持多种应用场景,例如研报、年报中有大量的图片,如果进行提取,可以进行图片定位和搜索,通过对产业链研报的解析,还可以为产业链构建提供支撑。
因此,本文主要围绕PDF图片提取这一任务,从PDF区域bouding box坐标识别、PDF文件向图片转换以及PDF文件图片提取三个方面进行论述,并给出了一些开源的识别脚本和组件,感兴趣的可以多多关注,最后感谢开源工作者的无私奉献。
参考文献
1、https://huggingface.co/bert-base-uncased
2、https://aistudio.baidu.com/aistudio/projectdetail/2274897
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢