
转自爱可可爱生活
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 GR - 图形学
摘要:高分辨率文本到3D内容创作、面向3D重建补全和生成的图像扩散、程序辅助语言模型、基于一般价值函数的随机好奇心探索、准确高效的大型语言模型训练后量化技术、基于因果自我对话的可解释性、路径独立平衡模型可以更好地利用测试时计算、面向大块多样化图像补全的结构引导扩散模型、数字存档生物彩色3D形态数据及相关挑战
1、[CV] Magic3D: High-Resolution Text-to-3D Content Creation
C Lin, J Gao, L Tang, T Takikawa, X Zeng, X Huang, K Kreis, S Fidler, M Liu, T Lin
[NVIDIA]
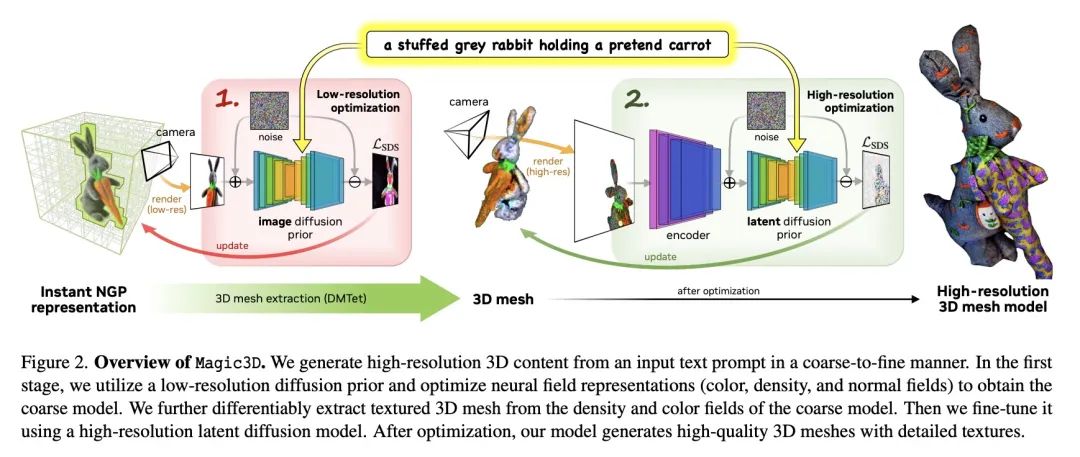
Magic3D:高分辨率文本到3D内容创作。DreamFusion最近展示了预训练文本到图像扩散模型在神经辐射场(NeRF)优化方面的效用,取得了显著的文本到3D的合成效果。然而,该方法有两个固有的局限性:NeRF的优化速度极慢;NeRF的低分辨率图像空间监督,导致低质量的3D模型,处理时间长。本文通过一个两阶段的优化框架来解决这些限制。首先,利用低分辨率的扩散先验获得一个粗略的模型,并以稀疏的3D哈希网格结构加速。用粗略表示作为初始化,进一步优化纹理3D网格模型,用高效可微渲染器与高分辨率潜扩散模型交互。所提出方法称为Magic3D,可在40分钟内创建高质量3D网格模型,比DreamFusion(据说平均需要1.5小时)快2倍,同时还可以实现更高的分辨率。用户研究表明,61.7%的评分者喜欢本文方法而不是DreamFusion。再加上图像条件下的生成能力,本文为用户提供了控制3D合成的新方法,为各种创造性的应用开辟了新的途径。
DreamFusion has recently demonstrated the utility of a pre-trained text-to-image diffusion model to optimize Neural Radiance Fields (NeRF), achieving remarkable text-to-3D synthesis results. However, the method has two inherent limitations: (a) extremely slow optimization of NeRF and (b) low-resolution image space supervision on NeRF, leading to low-quality 3D models with a long processing time. In this paper, we address these limitations by utilizing a two-stage optimization framework. First, we obtain a coarse model using a low-resolution diffusion prior and accelerate with a sparse 3D hash grid structure. Using the coarse representation as the initialization, we further optimize a textured 3D mesh model with an efficient differentiable renderer interacting with a high-resolution latent diffusion model. Our method, dubbed Magic3D, can create high quality 3D mesh models in 40 minutes, which is 2x faster than DreamFusion (reportedly taking 1.5 hours on average), while also achieving higher resolution. User studies show 61.7% raters to prefer our approach over DreamFusion. Together with the image-conditioned generation capabilities, we provide users with new ways to control 3D synthesis, opening up new avenues to various creative applications.
https://arxiv.org/abs/2211.10440



2、[CV] RenderDiffusion: Image Diffusion for 3D Reconstruction, Inpainting and Generation
T Anciukevičius, Z Xu, M Fisher...
[University of Edinburgh & Adobe Research & University of Glasgow]
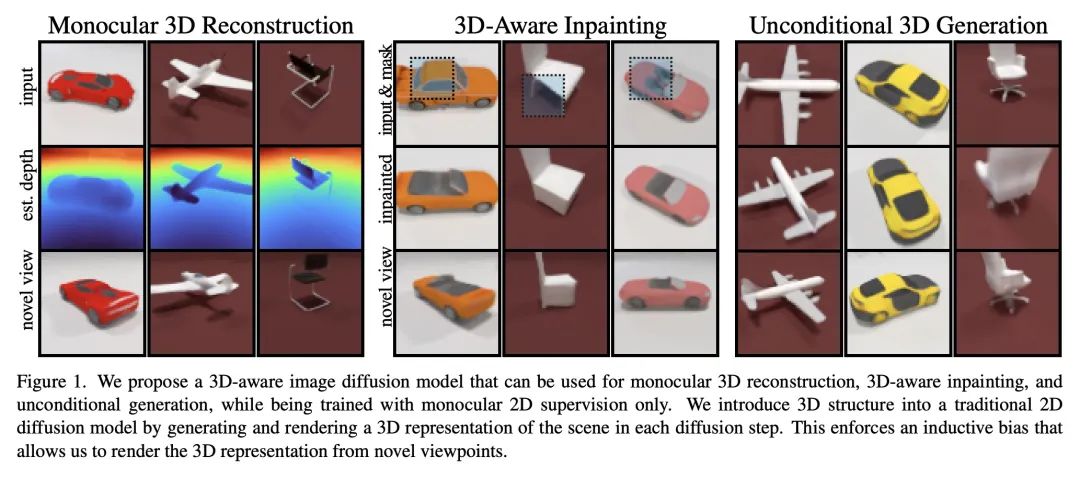
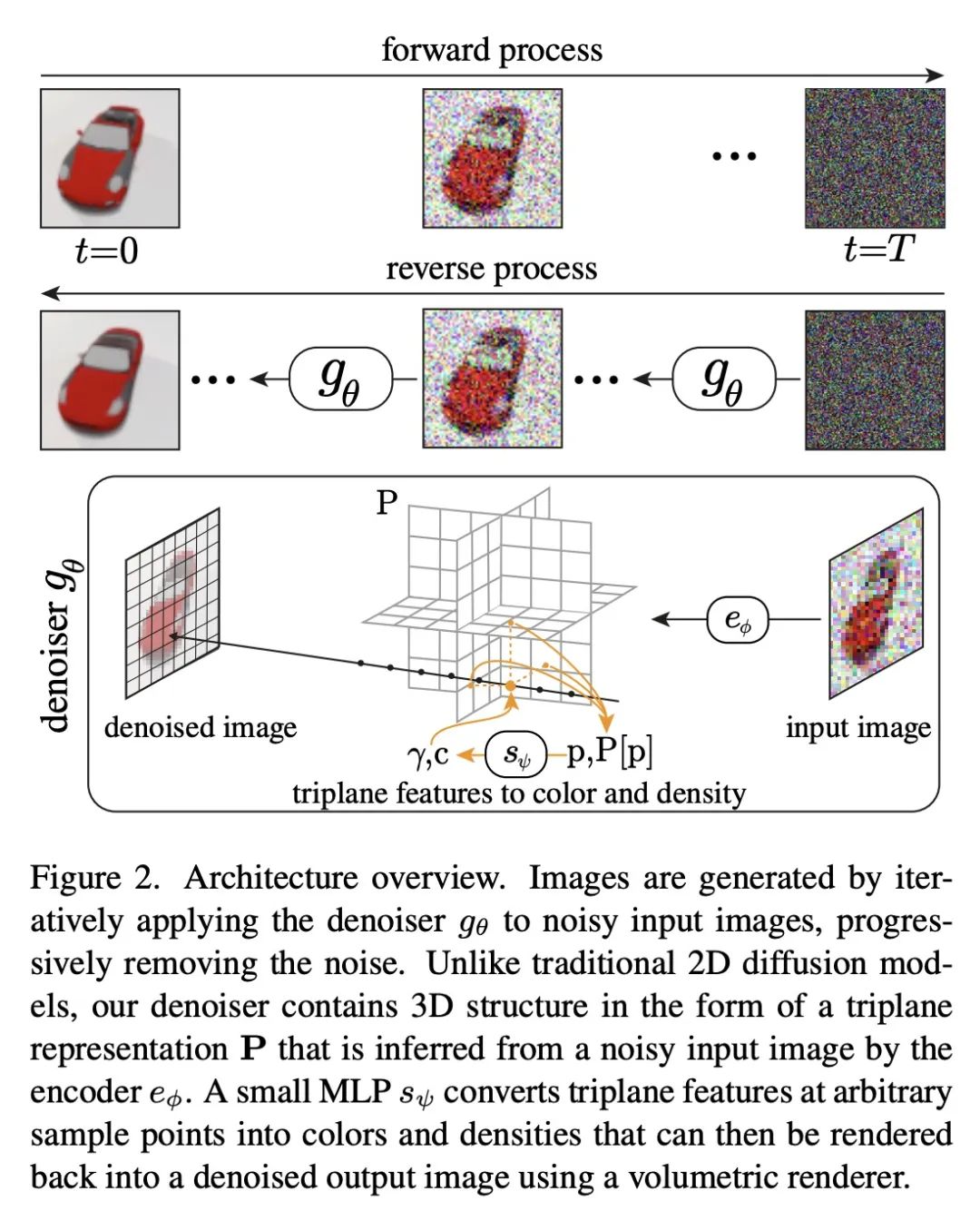
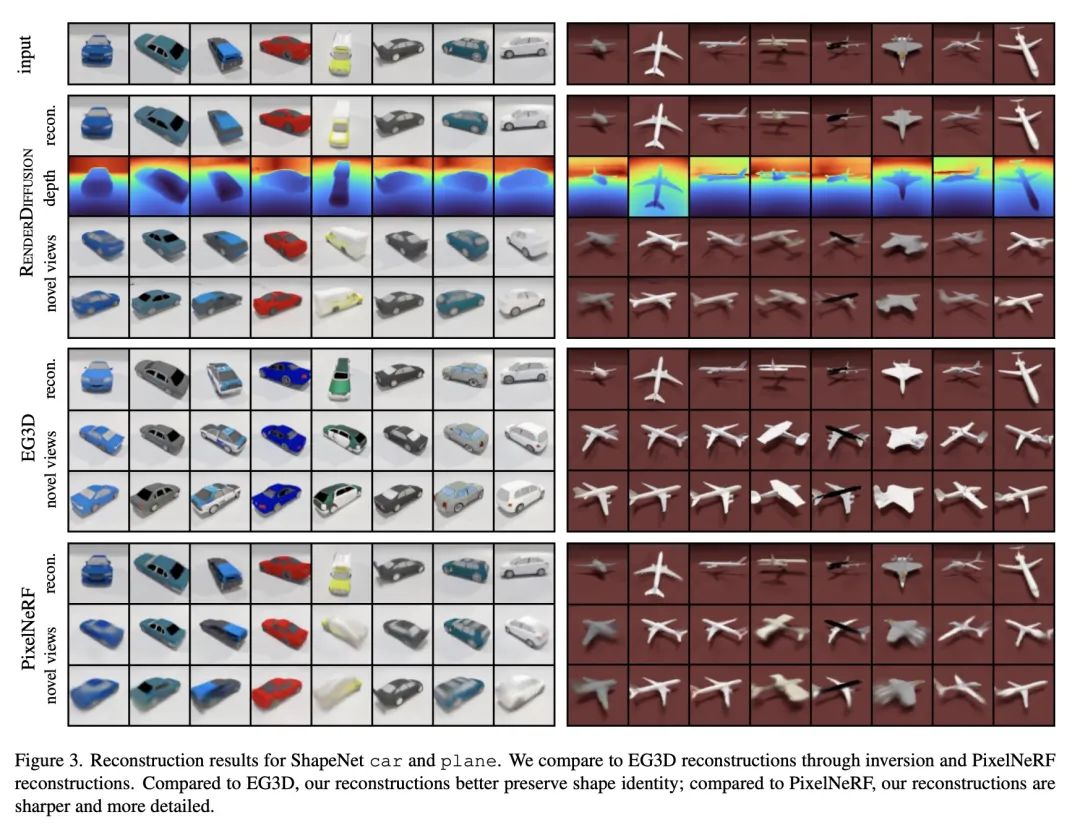
RenderDiffusion: 面向3D重建、补全和生成的图像扩散。扩散模型目前在有条件和无条件的图像生成方面都取得了最先进的性能。然而,到目前为止,图像扩散模型并不支持3D理解所需的任务,如视图一致的3D生成或单视图物体重建。本文提出RenderDiffusion,作为第一个用于3D生成和推理的扩散模型,可以只用单目2D监督来训练。该方法的核心是一个新的图像去噪架构,在每个去噪步骤中生成和渲染场景的中间3D表示。这在扩散过程中强化了一个强大的归纳结构,在只需要2D监督的情况下得到3D的一致表示。由此产生的3D表示可以从任意视角进行渲染。在ShapeNet和Clevr数据集上评估了RenderDiffusion,并显示了在生成3D场景和从2D图像推断3D场景方面具有竞争力的性能。此外,基于扩散的方法允许使用2D补全来编辑3D场景。
Diffusion models currently achieve state-of-the-art performance for both conditional and unconditional image generation. However, so far, image diffusion models do not support tasks required for 3D understanding, such as view-consistent 3D generation or single-view object reconstruction. In this paper, we present RenderDiffusion as the first diffusion model for 3D generation and inference that can be trained using only monocular 2D supervision. At the heart of our method is a novel image denoising architecture that generates and renders an intermediate three-dimensional representation of a scene in each denoising step. This enforces a strong inductive structure into the diffusion process that gives us a 3D consistent representation while only requiring 2D supervision. The resulting 3D representation can be rendered from any viewpoint. We evaluate RenderDiffusion on ShapeNet and Clevr datasets and show competitive performance for generation of 3D scenes and inference of 3D scenes from 2D images. Additionally, our diffusion-based approach allows us to use 2D inpainting to edit 3D scenes. We believe that our work promises to enable full 3D generation at scale when trained on massive image collections, thus circumventing the need to have large-scale 3D model collections for supervision.
https://arxiv.org/abs/2211.09869

3、[CL] PAL: Program-aided Language Models
L Gao, A Madaan, S Zhou, U Alon, P Liu, Y Yang, J Callan, G Neubig
[CMU]
PAL:程序辅助语言模型。大型语言模型(LLM)最近表现出令人印象深刻的能力,当在测试时提供几个样例,就能完成算术和符号推理任务(少样本提示)。这种成功在很大程度上可以归功于推理的提示方法,如思维链,采用了大型语言模型,通过将问题分解成步骤来理解问题描述,并对问题的每一步进行求解。虽然LLM似乎很擅长这种分步分解,但即使问题被正确分解,LLM也经常在解决部分犯逻辑和算术错误。本文提出程序辅助语言模型(PaL):一种新方法,用LLM来理解自然语言问题,并生成程序作为中间推理步骤,但将解决步骤转交给程序化运行时,如Python解释器。在PaL中,将自然语言问题分解成可运行的步骤仍然是LLM唯一的学习任务,而求解则委托给解释器。用BIG-Bench Hard和其他基准的12个推理任务进行实验,包括数学推理、符号推理和算法问题。在所有这些自然语言推理任务中,用LLM生成代码并用Python解释器进行推理,比大得多的模型带来了更准确的结果,在所有12个基准中都创造了新的最先进的结果。例如,当模型只被允许进行一次解码时,用Codex的PaL在GSM基准的数学词问题上取得了最先进的几率准确性,超过了带有思维链提示的PaLM-540B,绝对值为8%。在BIG-Bench Hard基准的三个推理任务中,PaL比CoT高出11%。在创建的更具挑战性的GSM-hard版本中,PaL的表现绝对超过了思维链的40%。
Large language models (LLMs) have recently demonstrated an impressive ability to perform arithmetic and symbolic reasoning tasks when provided with a few examples at test time (few-shot prompting). Much of this success can be attributed to prompting methods for reasoning, such as chain-of-thought, that employ LLMs for both understanding the problem description by decomposing it into steps, as well as solving each step of the problem. While LLMs seem to be adept at this sort of step-by-step decomposition, LLMs often make logical and arithmetic mistakes in the solution part, even when the problem is correctly decomposed. We present Program-Aided Language models (PaL): a new method that uses the LLM to understand natural language problems and generate programs as the intermediate reasoning steps, but offloads the solution step to a programmatic runtime such as a Python interpreter. With PaL, decomposing the natural language problem into runnable steps remains the only learning task for the LLM, while solving is delegated to the interpreter. We experiment with 12 reasoning tasks from BIG-Bench Hard and other benchmarks, including mathematical reasoning, symbolic reasoning, and algorithmic problems. In all these natural language reasoning tasks, generating code using an LLM and reasoning using a Python interpreter leads to more accurate results than much larger models, and we set new state-of-the-art results in all 12 benchmarks. For example, PaL using Codex achieves state-of-the-art few-shot accuracy on the GSM benchmark of math word problems when the model is allowed only a single decoding, surpassing PaLM-540B with chain-of-thought prompting by an absolute 8% .In three reasoning tasks from the BIG-Bench Hard benchmark, PaL outperforms CoT by 11%. On GSM-hard, a more challenging version of GSM that we create, PaL outperforms chain-of-thought by an absolute 40%.
https://arxiv.org/abs/2211.10435




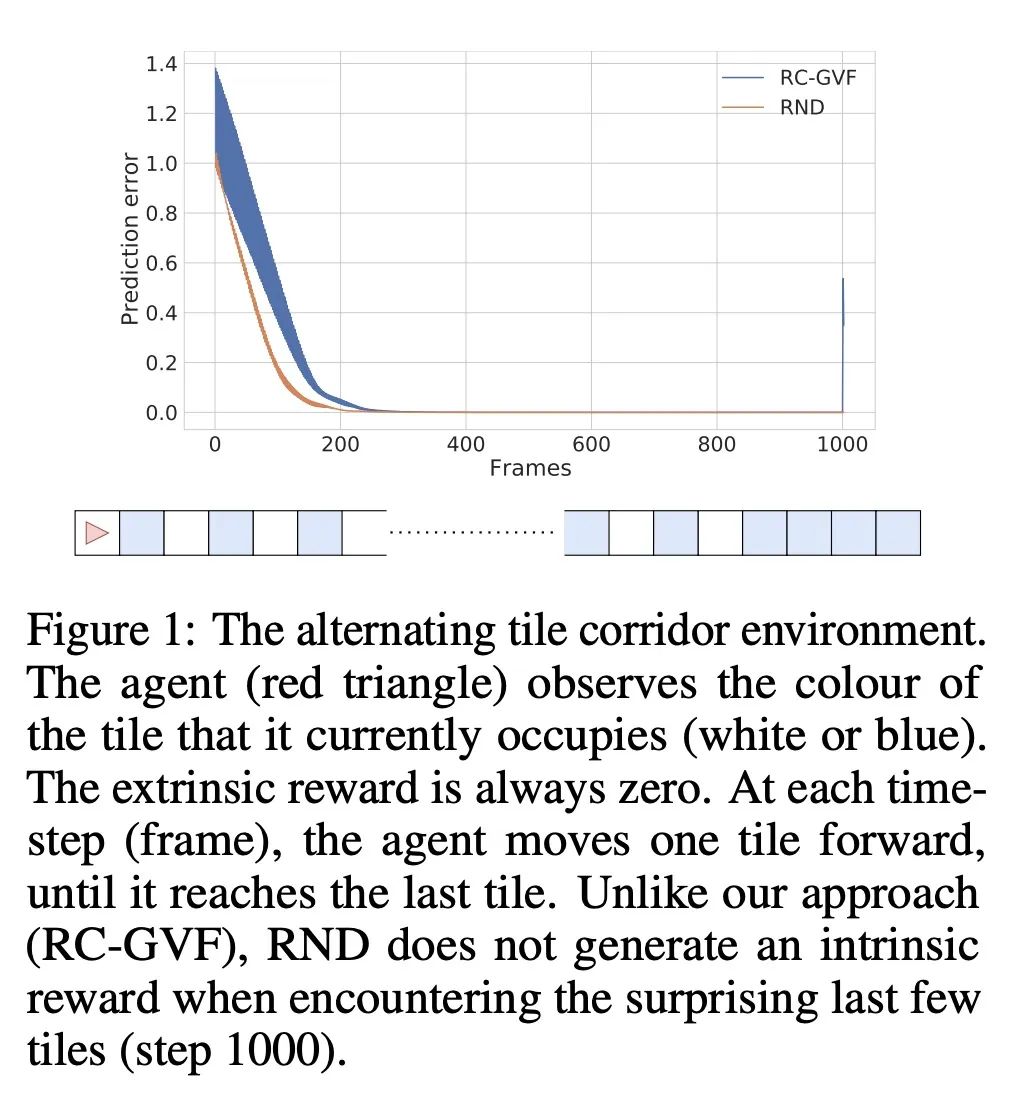
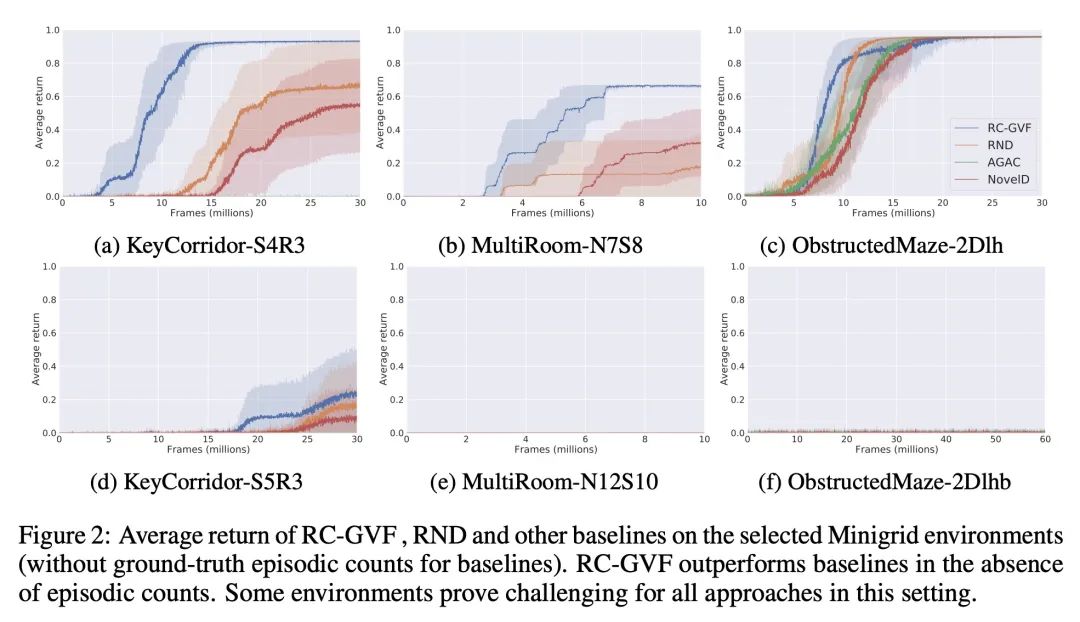
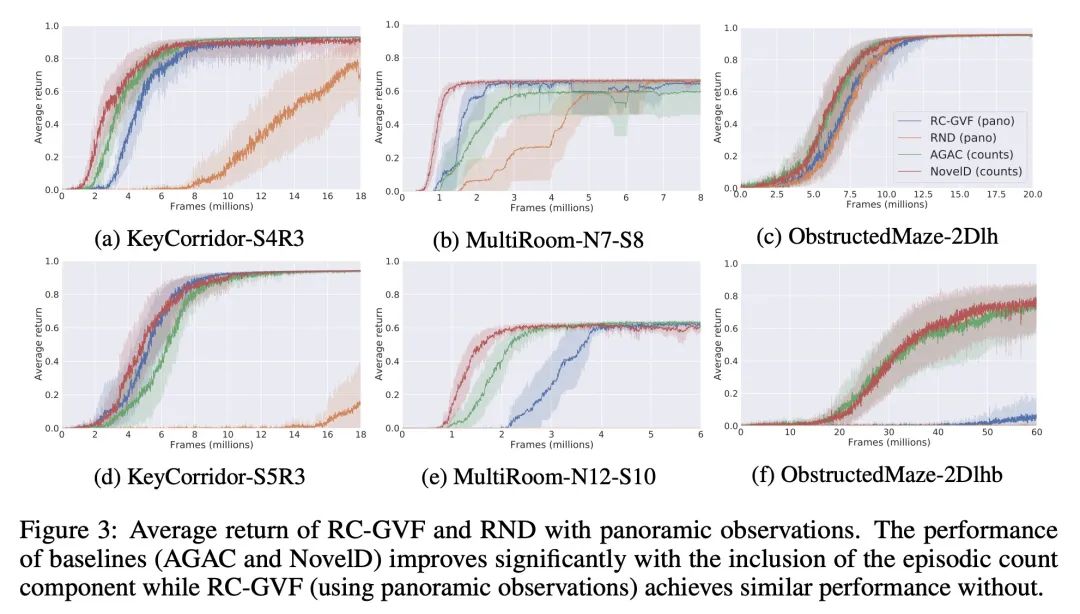
4、[LG] Exploring through Random Curiosity with General Value Functions
A Ramesh, L Kirsch, S v Steenkiste, J Schmidhuber
[IDSIA & Google Research]
基于一般价值函数的随机好奇心探索。强化学习中的高效探索是一个具有挑战性的问题,通常通过内在奖励来解决。最近突出的方法是基于状态的新颖性或人工好奇心的变种。然而,直接将它们应用于部分可观察的环境可能是无效的,并导致内在奖励的过早消散。本文提出具有一般价值函数的随机好奇心(RC-GVF),一种新的内在奖励函数,借鉴了这些不同方法之间的联系。RC-GVF不是只用当前观察的新颖性或因未能预测精确环境动态而获得的好奇心奖励,而是通过预测时间上扩展的一般价值函数来获得内在奖励。本文证明,这改善了在一个难以探索的diabolical lock问题中的探索。此外,在部分可观察的MiniGrid环境中,RC-GVF在缺乏真实事件计数的情况下明显优于之前的方法。MiniGrid上的全景观测进一步提高了RC-GVF的性能,使其在利用偶发计数形式的特权信息的基线上具有竞争力。
Efficient exploration in reinforcement learning is a challenging problem commonly addressed through intrinsic rewards. Recent prominent approaches are based on state novelty or variants of artificial curiosity. However, directly applying them to partially observable environments can be ineffective and lead to premature dissipation of intrinsic rewards. Here we propose random curiosity with general value functions (RC-GVF), a novel intrinsic reward function that draws upon connections between these distinct approaches. Instead of using only the current observation's novelty or a curiosity bonus for failing to predict precise environment dynamics, RC-GVF derives intrinsic rewards through predicting temporally extended general value functions. We demonstrate that this improves exploration in a hard-exploration diabolical lock problem. Furthermore, RC-GVF significantly outperforms previous methods in the absence of ground-truth episodic counts in the partially observable MiniGrid environments. Panoramic observations on MiniGrid further boost RC-GVF's performance such that it is competitive to baselines exploiting privileged information in form of episodic counts.
https://arxiv.org/abs/2211.10282

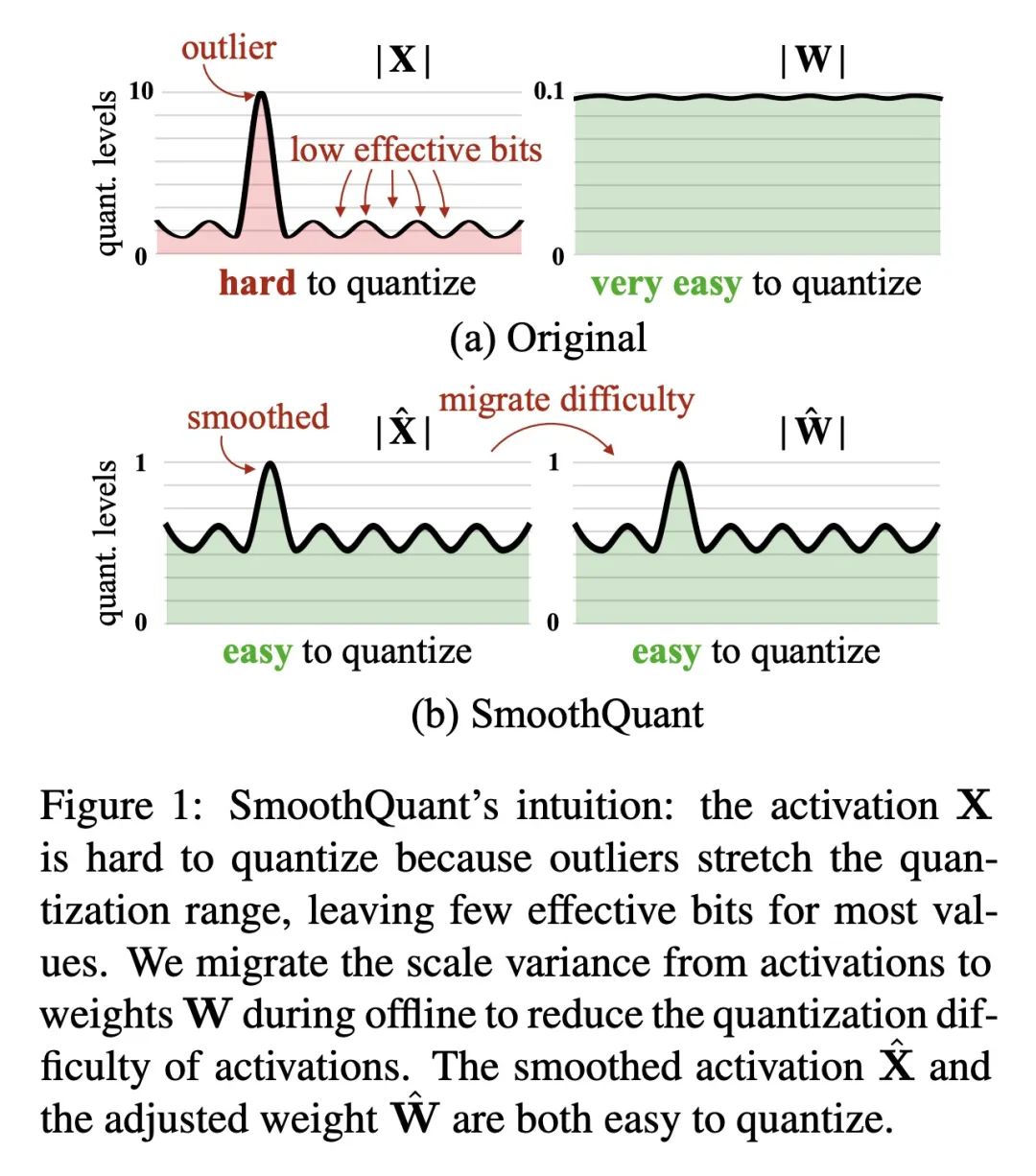
5、[CL] SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models
G Xiao, J Lin, M Seznec, J Demouth, S Han
[MIT & NVIDIA]
SmoothQuant: 准确高效的大型语言模型训练后量化技术。大型语言模型(LLM)表现出优异的性能,但需要大量的计算和内存。量化可以减少内存并加速推理。然而,对超过1000亿参数的LLM,现有方法不能保持准确性,或者不能在硬件上高效运行。本文提出SmoothQuant,一种免训练、保持精度、通用的训练后量化(PTQ)解决方案,以实现LLM的8位权重、8位激活(W8A8)量化,并能有效实施。在固定的激活通道上会出现系统的异常值。基于权重容易量化而激活不容易量化的事实,SmoothQuant通过将量化难度从激活转移到权重,以数学上的等效转换来平滑激活异常值。SmoothQuant使LLMs中的所有GEMMs的权重和激活都能进行INT8量化,包括OPT-175B、BLOOM-176B和GLM-130B。与使用混合精度激活量化或只使用权重量化的现有技术相比,SmoothQuant具有更好的硬件效率。本文证明LLM的速度提高了1.56倍,内存减少了2倍,而精度的损失可以忽略不计。由于硬件友好的设计,将SmoothQuant整合到FasterTransformer——最先进的LLM服务框架中,与FP16相比,用一半的GPU就能实现更快的推理速度。
Large language models (LLMs) show excellent performance but are compute- and memory-intensive. Quantization can reduce memory and accelerate inference. However, for LLMs beyond 100 billion parameters, existing methods cannot maintain accuracy or do not run efficiently on hardware. We propose SmoothQuant, a training-free, accuracy-preserving, and general-purpose post-training quantization (PTQ) solution to enable 8-bit weight, 8-bit activation (W8A8) quantization for LLMs that can be implemented efficiently. We observe that systematic outliers appear at fixed activation channels. Based on the fact that weights are easy to quantize while activations are not, SmoothQuant smooths the activation outliers by migrating the quantization difficulty from activations to weights with a mathematically equivalent transformation. SmoothQuant enables an INT8 quantization of both weights and activations for all the GEMMs in LLMs, including OPT-175B, BLOOM-176B and GLM-130B. SmoothQuant has better hardware efficiency than existing techniques using mixed-precision activation quantization or weight-only quantization. We demonstrate up to 1.56x speedup and 2x memory reduction for LLMs with negligible loss in accuracy. Thanks to the hardware-friendly design, we integrate SmoothQuant into FasterTransformer, a state-of-the-art LLM serving framework, and achieve faster inference speed with half the number of GPUs compared to FP16. Our work offers a turn-key solution that reduces hardware costs and democratizes LLMs. Code will be released at: this https URL.
https://arxiv.org/abs/2211.10438

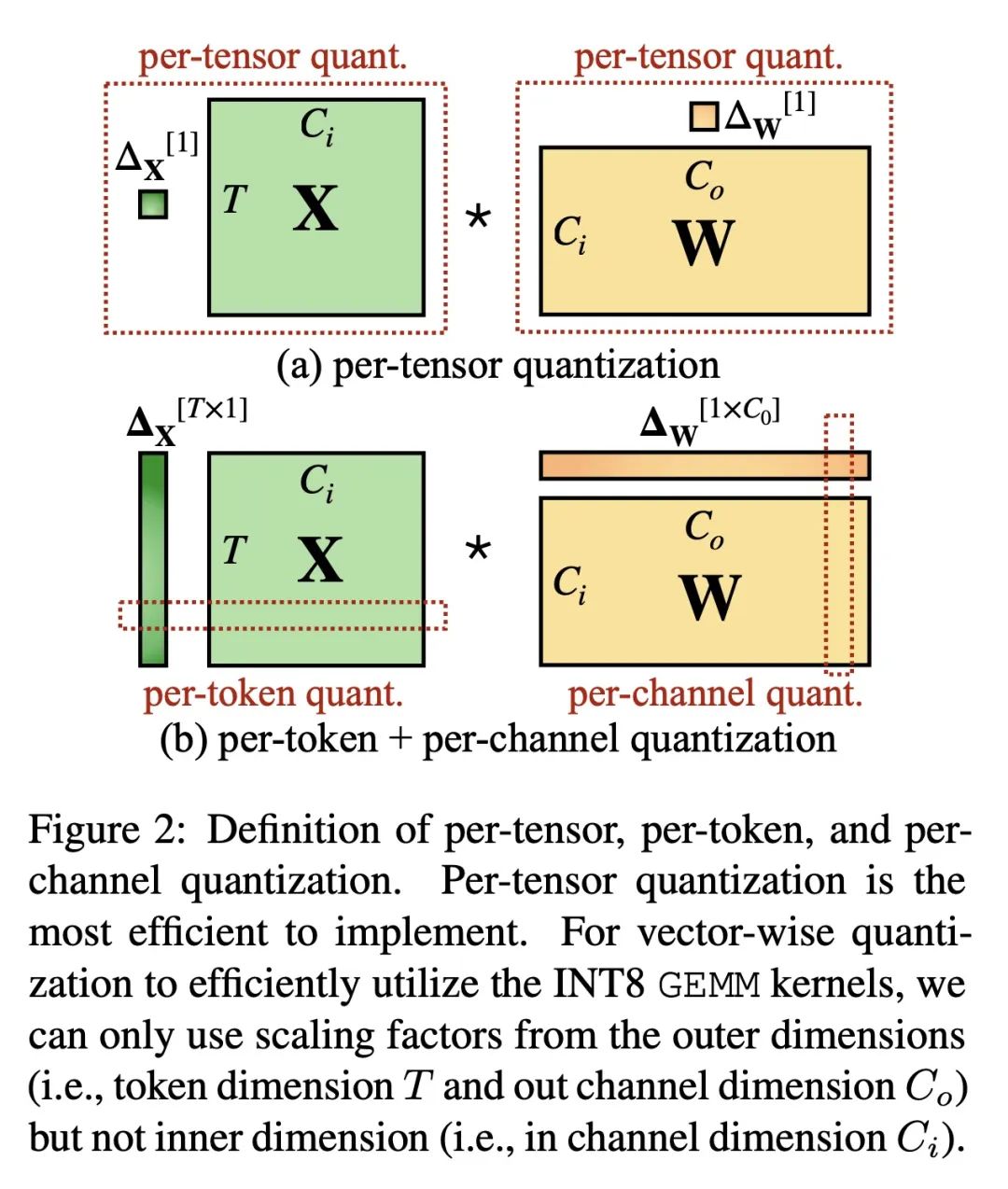
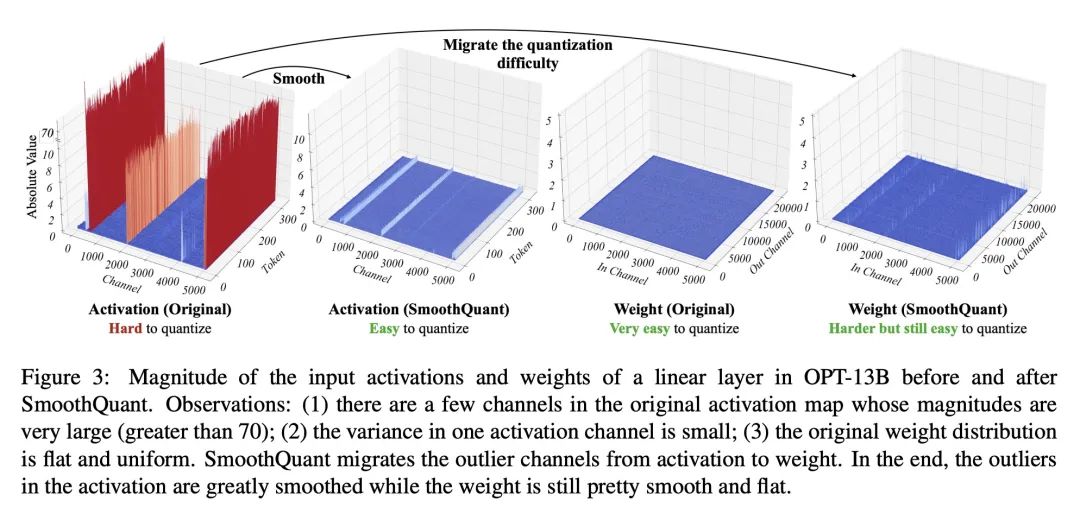
另外几篇值得关注的论文:
[LG] Explainability Via Causal Self-Talk
基于因果自我对话的可解释性
N A. Roy, J Kim, N Rabinowitz
[DeepMind]
https://arxiv.org/abs/2211.09937

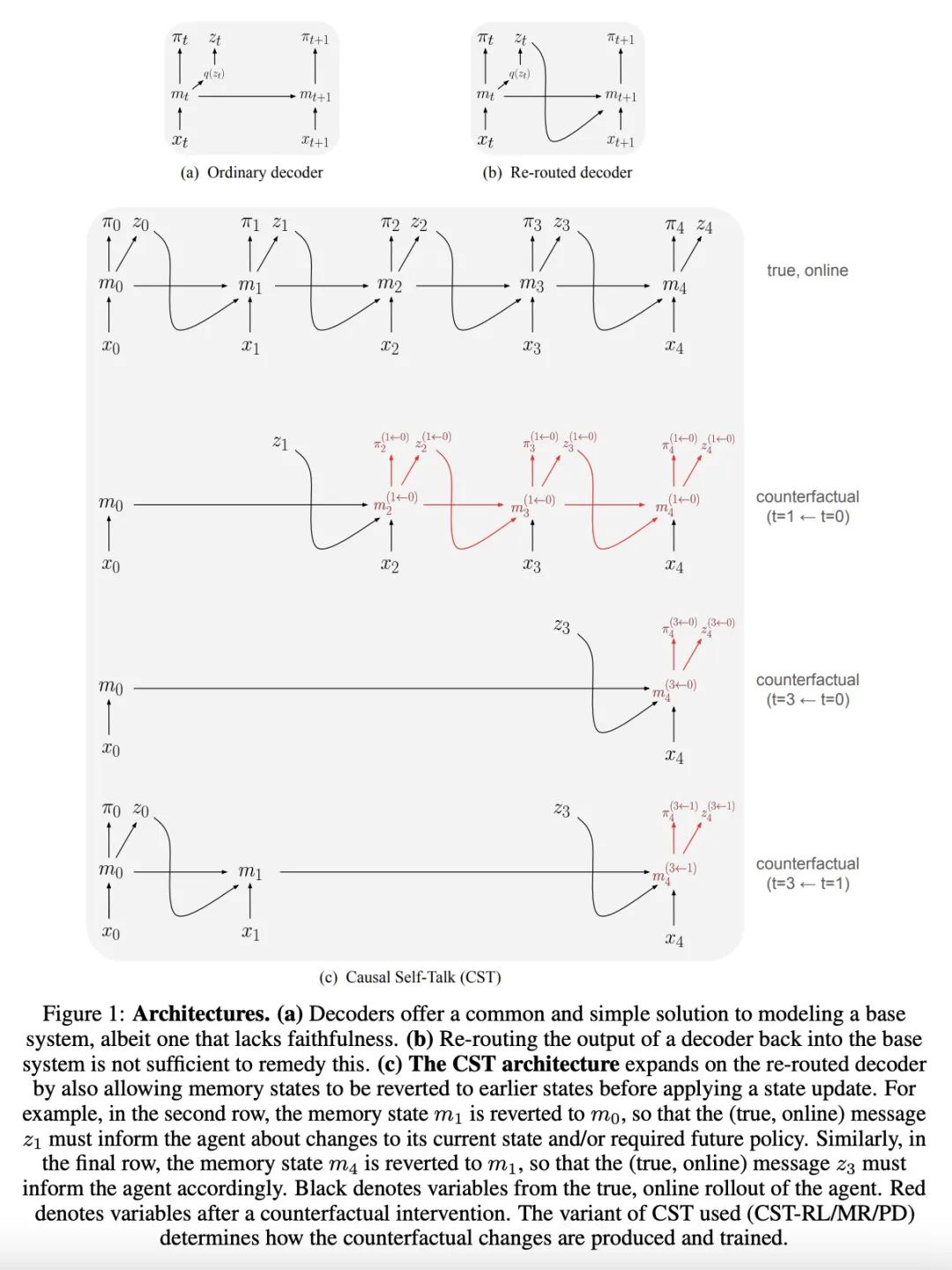
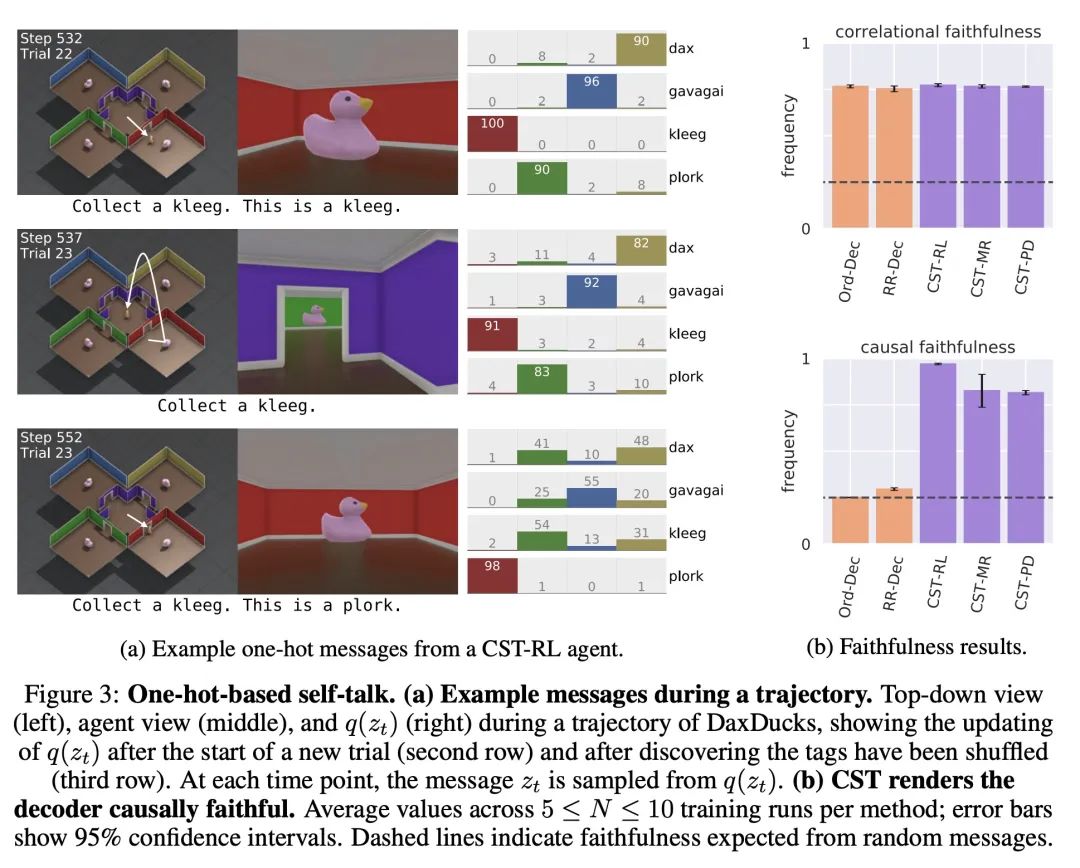
[LG] Path Independent Equilibrium Models Can Better Exploit Test-Time Computation
路径独立平衡模型可以更好地利用测试时计算
C Anil, A Pokle, K Liang, J Treutlein, Y Wu, S Bai...
[University of Toronto & CMU & Princeton University & Stanford University]
https://arxiv.org/abs/2211.09961

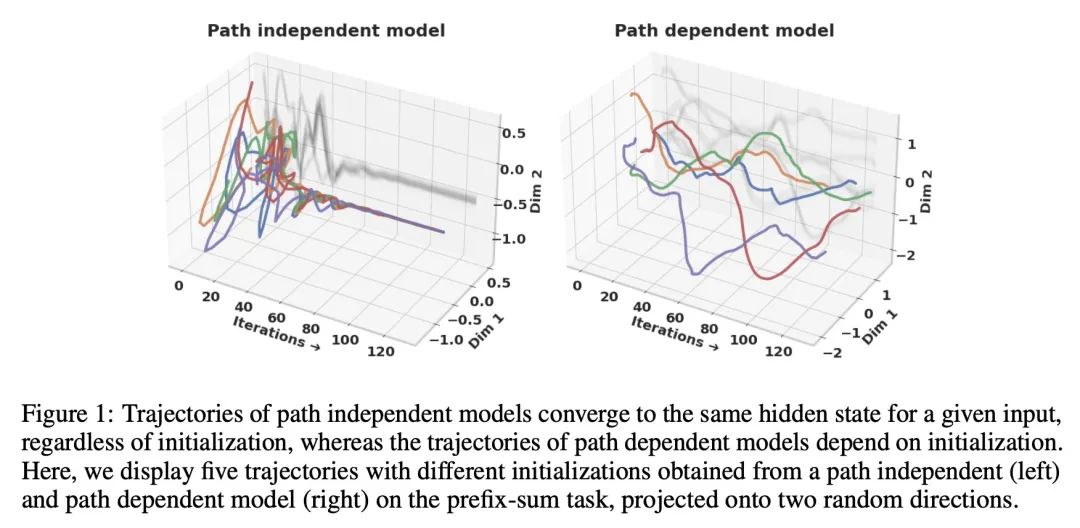
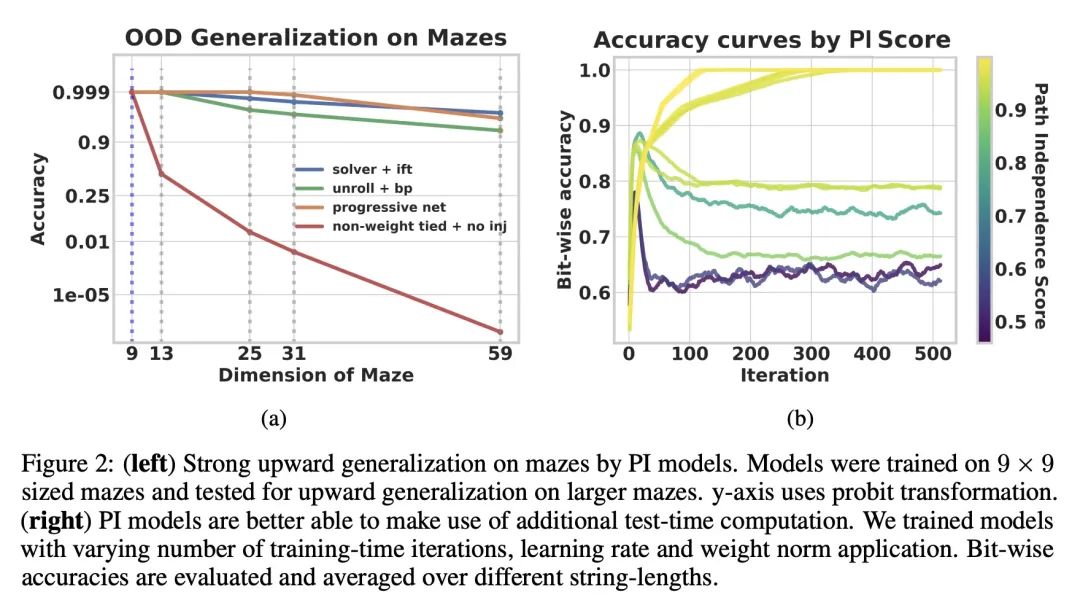
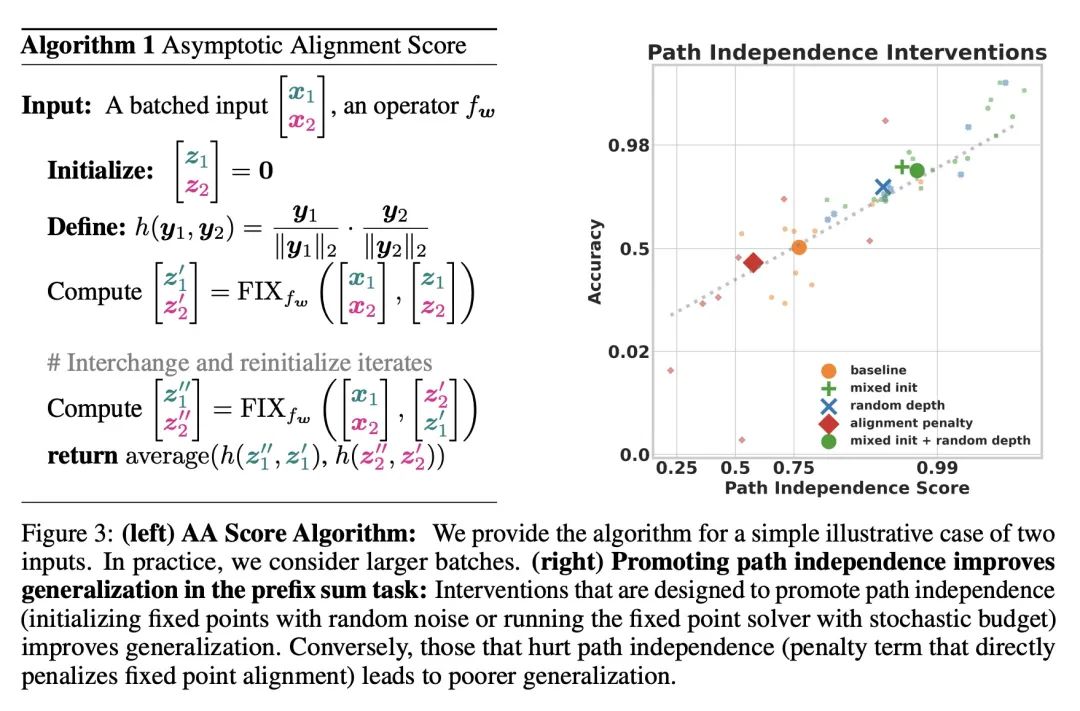
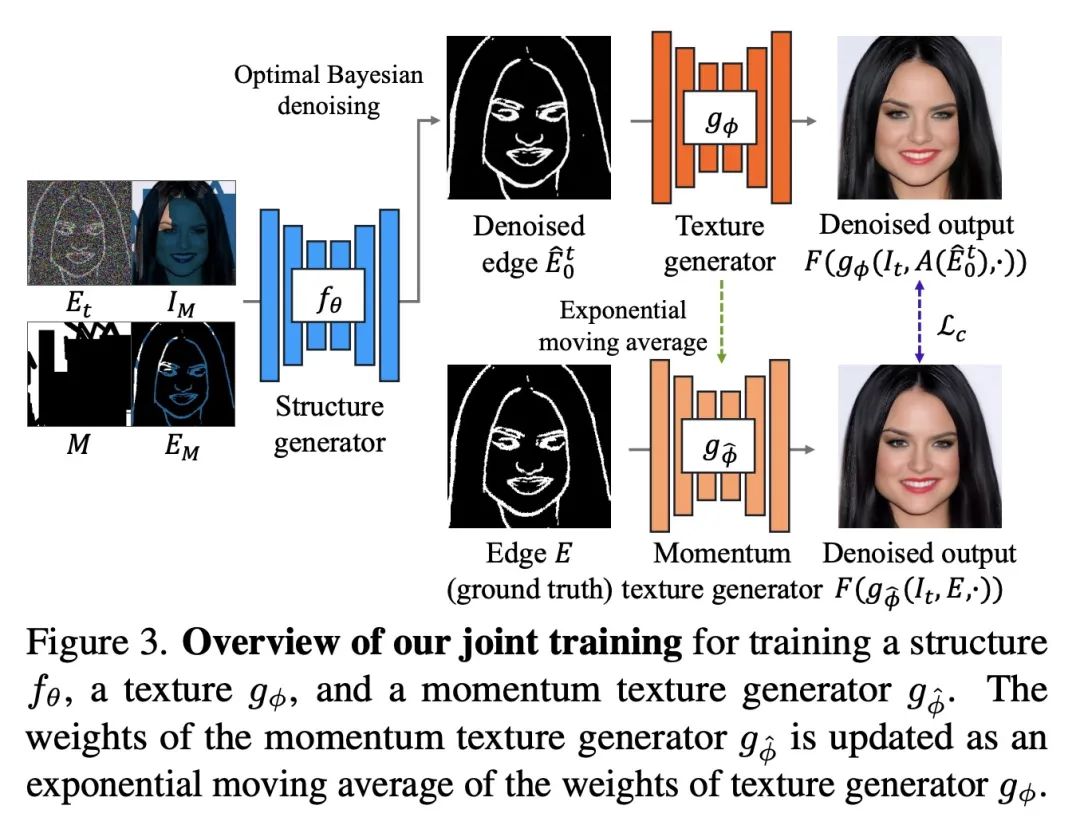
[CV] A Structure-Guided Diffusion Model for Large-Hole Diverse Image Completion
面向大块多样化图像补全的结构引导扩散模型
D Horita, J Yang, D Chen, Y Koyama, K Aizawa
[The University of Tokyo & Microsoft Research Asia & AIST]
https://arxiv.org/abs/2211.10437



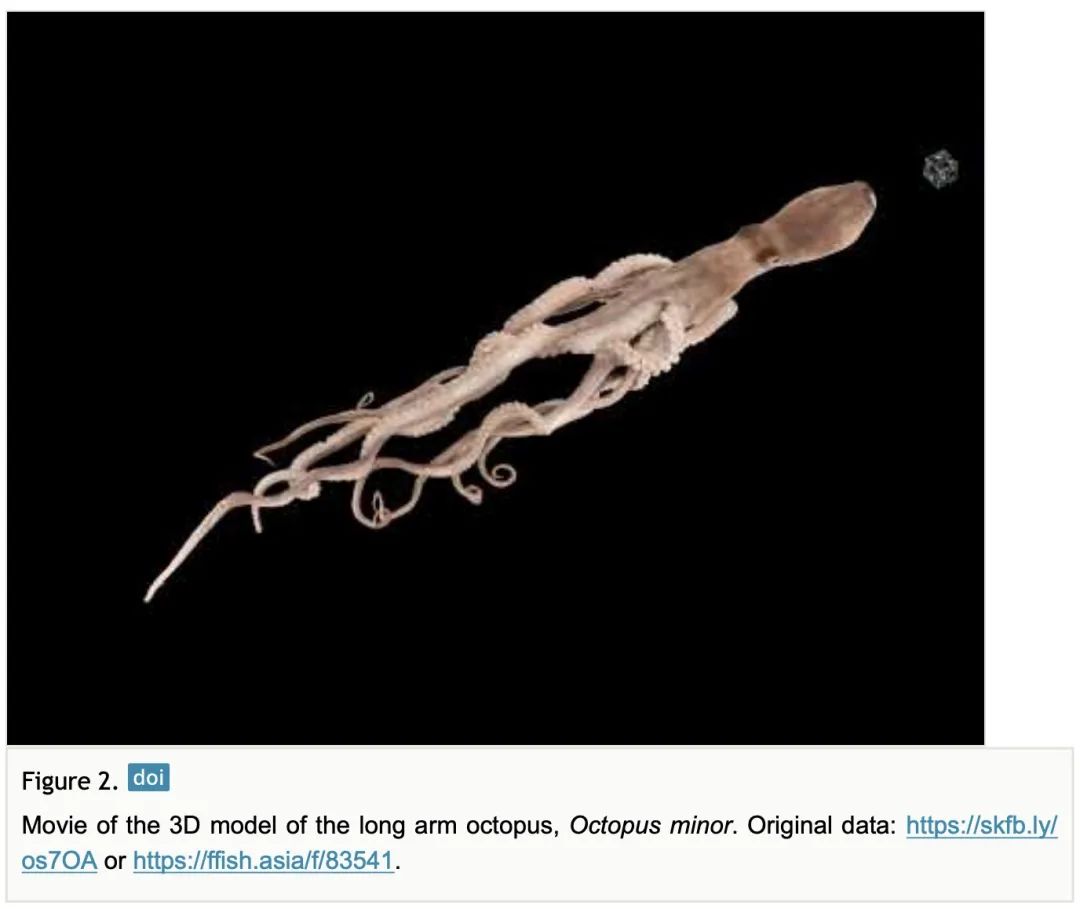
[CV] Bio-photogrammetry: digitally archiving coloured 3D morphology data of creatures and associated challenges
生物摄影测量:数字存档生物彩色3D形态数据及相关挑战
Y Kano
[Kyushu Open University]
https://riojournal.com/article/86985/list/2/



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢