
作者:Igor Melnyk, Pierre Dognin, Payel Das
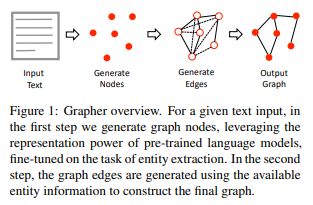
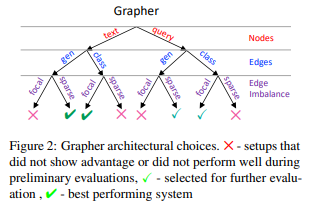
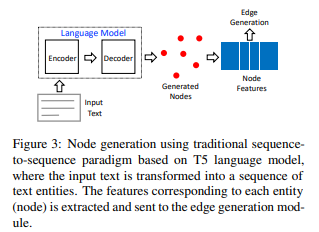
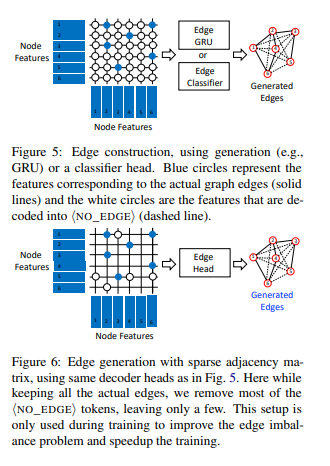
简介:本文研究基于预训练语言模型从文本中构建知识图谱。在这项工作中,作者提出了一种新颖的基于文本输入的端到端多阶段知识图谱(KG)生成系统。整个过程分为两个阶段:首先使用预训练的语言模型生成图节点,然后使用简单的边缘构建头,从而从文本中高效地提取KG。对于每个阶段,作者都会根据可用的训练资源考虑多种可使用的体系结构选择。作者在最近的WebNLG 2020 Challenge数据集上评估了该模型(使其在文本到RDF生成任务),与最先进的性能相匹配;在《纽约时报》(NYT)数据集与大型TekGen数据集上显示出强大的整体性能、优于现有的基线!
作者认为作者所提出的系统可以作为现有线性化或基于采样的图形生成方法的可行KG构建替代方案!
论文下载:https://arxiv.org/pdf/2211.10511
代码下载:https://github.com/IBM/Grapher
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢