
作者:Aochuan Chen, Yuguang Yao, Pin-Yu Chen, 等
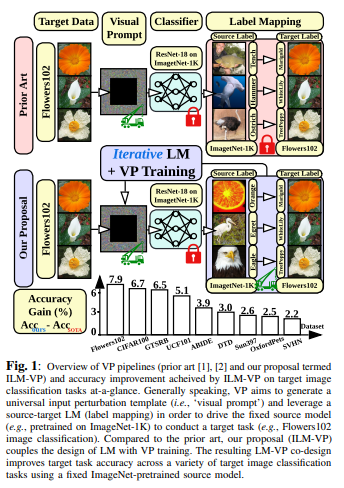
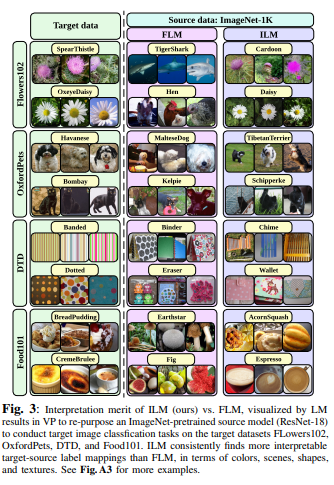
简介:作者重新审视并改进了视觉Prompt提示(VP),这是一种视觉任务的输入提示技术。VP可以通过简单地将通用提示(根据输入扰动模式)结合到下游数据点中,来重新编程固定的、预训练的源模型,以完成目标域中的下游任务。然而,即使给定源类和目标类之间的无规则标签映射(LM),VP仍然保持有效的原因仍然难以理解。受上述启发,试问:LM与VP是如何相互关联的?如何利用这种关系来提高目标任务的准确性?作者研究了LM对VP的影响,并提供了一个肯定的答案,即更好的LM“质量”(通过映射精度和解释进行评估)可以持续提高VP的有效性。这与缺少LM因子的现有技术形成对比。为了优化LM,作者提出了一种新的VP框架,称为ILM-VP(基于迭代标签映射的视觉提示),它自动将源标签重新映射到目标标签,并逐步提高VP的目标任务准确性。此外,当使用对比语言图像预训练模型(CLIP)时,作者建议集成LM过程来辅助CLIP的文本提示选择,并提高目标任务的准确性。广泛的实验表明:作者的建议显著优于最先进的VP方法。作者表明:当将ImageNet预训练的ResNet-18重新编程为13个目标任务时,作者的方法以显著的优势优于基线(如:将学习转移到目标Flowers102和CIFAR100数据集的准确度提高了7.9%和6.7%)。此外,作者对基于CLIP的VP的建议:在Flowers102和DTD上分别实现了13.7%和7.1%的精度改进。
论文下载:https://arxiv.org/pdf/2211.11635.pdf
代码下载:https://github.com/OPTML-Group/ILM-VP
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢