
实体分类(entity typing)旨在为实体指定类型,使机器可以更好地理解自然语言,并有利于实体链接和文本分类等下游任务。传统的实体分类范式存在两个问题:1. 它无法给实体分配预定义类型集以外的类型;2. 长尾类型存在很少的训练样本,因此难以解决少/零样本问题。
为了解决这些问题,本文提出了GET,一种新的生成式实体分类范式,通过预训练语言模型(PLM)为文本实体生成多个类型。图1是基于生成范式和分类范式对文本进行实体分类的结果展示图:
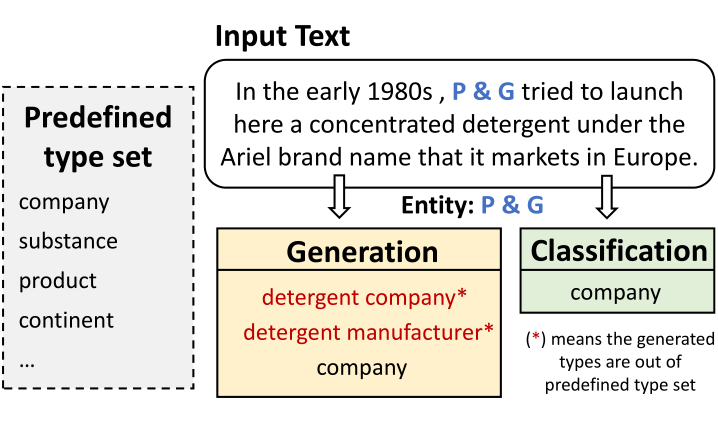
▲ 图1:基于生成式和分类范式的实体分类结果图
可以发现,PLM 可以为实体生成预定义类型集以外的类型,这些类型包含更丰富的语义信息。同时由于在预训练阶段已经学习到大量的知识,PLM 能够进行概念推理并有效解决少/零样本问题。
然而 PLM 存在的问题是无论最终是否在细粒度数据集上进行微调,都倾向于生成高频但粗粒度的类型,因此该范式引入课程学习(CL)的思想,仅需为模型提供少量人工标注数据和大量自动生成的低质量数据组成的异构数据,采用自步学习的方法,依靠课程对类型粒度以及数据异构型的理解自我调整学习进度,使 PLM 生成高质量的细粒度类型。
通过对不同语言和下游任务的数据进行的大量实验,证明了我们的 GET 模型优于 SOTA 的实体分类模型。该工作目前已被 EMNLP 2022 接收,论文和代码链接如下:

论文链接:
代码链接:
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢