
在SIGGRAPH 2022上,南洋理工大学-商汤科技联合研究中心S-Lab团队提出了基于零次学习的文本驱动的三维数字人模型与动作生成方法AvatarCLIP。利用大规模视觉语言模型CLIP的跨模态能力以及可微渲染工具,AvatarCLIP实现了以自然语言输入,无需任何训练,便可高质量生成三维数字人的模型。再结合大量动作数据的预训练模型,AvatarCLIP进一步实现了以自然语言为输入的角色动作的生成。在数字人生成的任务上,AvatarCLIP相较已有方案在质量上提升明显;而基于零次学习的文本驱动的动作生成,是AvatarCLIP首次提出并给出了有效方案。
论文名称:AvatarCLIP : Zero-Shot Text-Driven Generation and Animation of 3D Avatars

Part 1
背景

图一
如果借鉴之前图像生成方法的成功经验,则需要大量与文本配对的三维模型或者动作数据进行有监督训练。然而,现在没有这样的数据,且很难收集,数据量也很难提升到百万量级。因此,在这篇工作中,我们选择使用零次学习的方式,即不使用任何与文本配对的数据,进行三维数字人以及动作的生成。
Part 2
基本原理
CLIP相信大家都比较熟悉,它的图像与文本编码器可以将两种模态的数据映射到同一个隐空间。利用这一性质,我们可以先初始化一种三维表示,如图二左侧所示。它可以是隐函数,也可以是mesh。
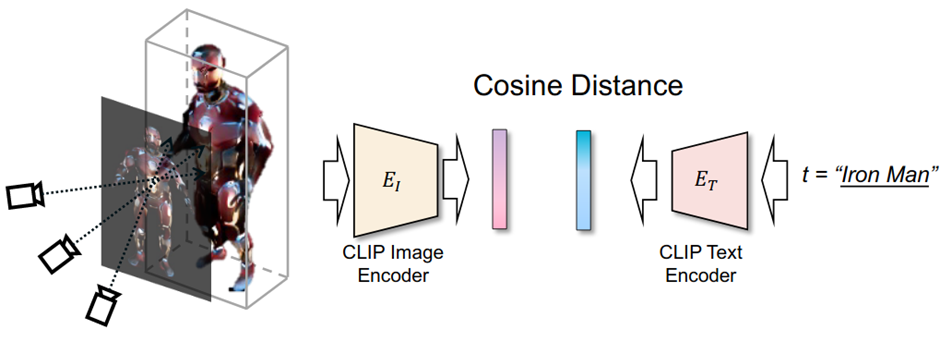
图二
然后,利用可微渲染,渲染出对应的图像,输入CLIP的图像编码器,将得到的渲染图像特征与目标文本的特征之间计算cosine距离,以最大化cosine距离为优化目标,对三维表示进行优化。最终,我们期望优化出与目标文本相近的三维表达。
虽然这个原理相对简单,但若想要让这个算法有效成功优化出合理的三维形状以及动作,仍需要很多其它努力。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢