


收录会议:
论文链接:
简介与主要贡献
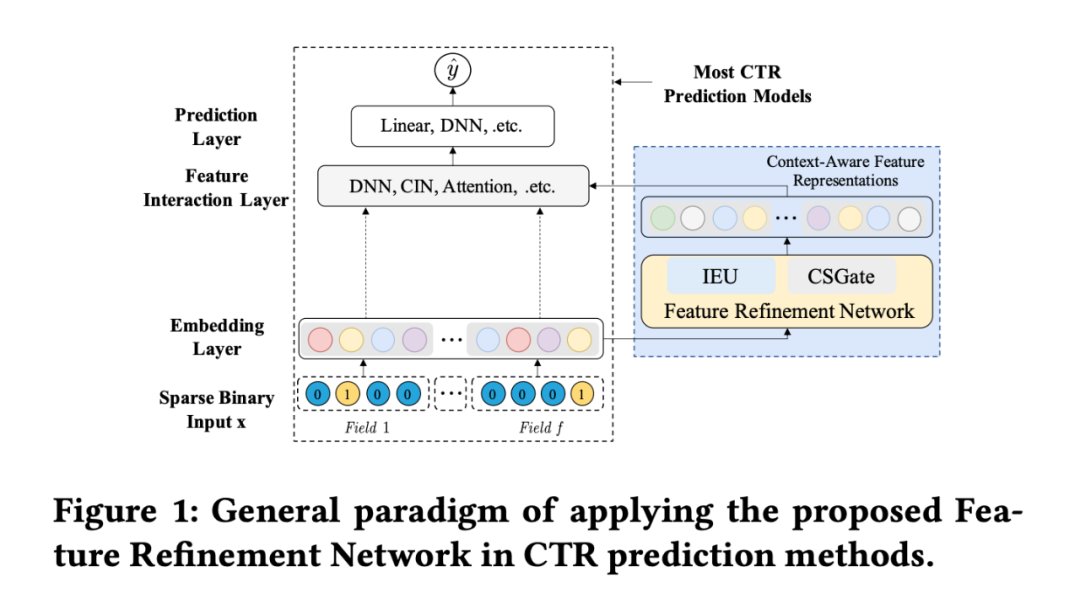
目前大多数提升点击率预估效果的模型主要是通过建模特征交互,但是如何设计有效的特征交互结构需要设计人员对数据特点以及结构设计等方面有很强的要求。目前的以建模特征交互为主的模型可以总结为三层范式:embedding layer, feature interaction layer, 以及 prediction layer。大多数论文改进集中在 Featrue interaction layer。
然而大部分的模型都存在一个问题:对于一个相同的特征,他们仅仅学到了一个固定的特征表示,而没有考虑到这个特征在不同实例中不同上下文环境下的重要性。例如实例 1:{female, white, computer, workday} 和实例 2:{female, red, lipstick, workday} 中,特征 “female” 在这两个实例中的重要性(对最后的预测结果的影响或者与其他特征的关系)是不同的,因此在输入特征交互层之前我们就可以调整特征 “female” 的重要性或者是表示。
现有的工作已经注意到了这个问题,例如 IFM、DIFM 等,但是他们仅仅在不同的实例中为相同特征赋予不同的权重(vector-level weights),导致不同实例中的相同特征的表示存在严格的线性关系,而这显然是不太合理的。
另一方面,本文希望一个理想的特征细化模块应该识别重要的跨实例上下文信息,并学习不同上下文下显著不同的表示。
给出了一个例子:{female, red, lipstick, workday} and {female, red, lipstick, weekend},在这两个实例汇总,如果使用self-attention(在 CTR 中很常用的模块,来识别特征之间的关系),那么因为 “female”和“red”以及“lipstick”的关系比“workday”或者“weekend”的更加紧密,所以在两个实例中,都会赋予“red”和“lipstick”更大的注意力权重,而对“workday”或者“weekend”的权重都很小。但是用户的行为会随着“workday”到“weekend”的变化而变化。
因此本文提出了一个模型无关的模块 Feature Refinement Network(FRNet)来学习上下文相关的特征表示,能够使得相同的特征在不同的实例中根据与共现特征的关系以及完整的上下文信息进行调整。主要贡献如下:
-
本文提出了一个名为 FRNet 的新模块,它是第一个通过将原始和互补的特征表示与比特级权值相结合来学习上下文感知特征表示的工作。
-
FRNet 可以被认为是许多 CTR 预测方法的基本组成部分,可以插入在 embedding layer 之后,提高 CTR 预测方法的性能。
-
FRNet 表现出了极强集兼容性和有效性。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢