内容详情可关注“智源社区”公众号,或者点击这里「Stable Diffusion 2.0版本」进行查看,Stability AI发布了Stable Diffusion 2.0 版本,以下为发布全文:
我们很高兴地宣布 Stable Diffusion 2的开源版本。
GitHub地址:https://github.com/Stability-AI/stablediffusion
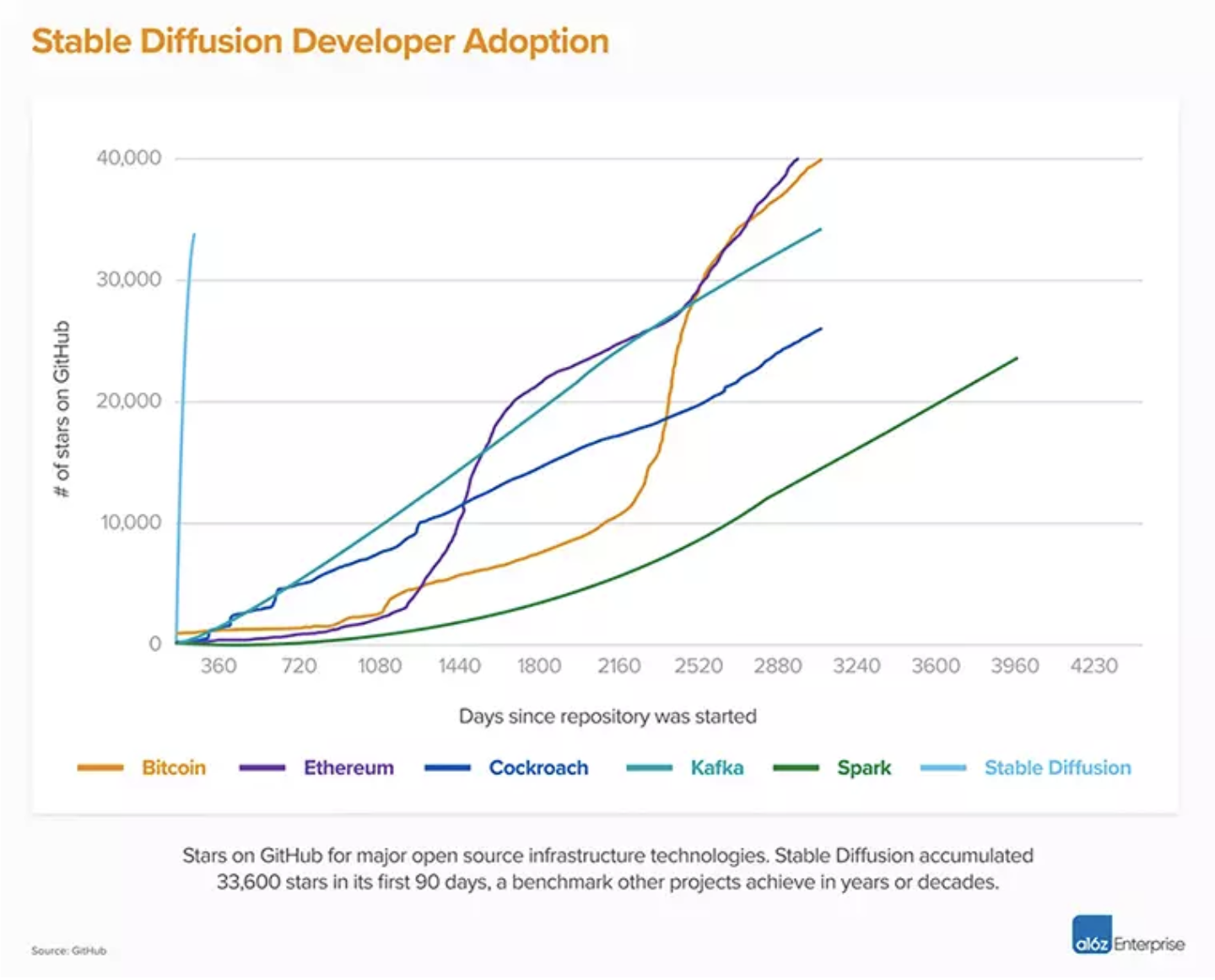
Stable Diffusion V1版本改变了开源AI模型的本质,并在世界各地催生了数以百计的其他模型和创新。在所有软件中,它是攀升到Github 10K星最快的软件之一,在不到两个月的时间里就突破了33K 星。
![]() 资料来源: A16z 和 Github
来自慕尼黑大学的 Robin Rombach (Stability AI)和 Patrick Esser (Runway ML)的团队,在Björn Ommer 教授的领导下,主导了最初V1版本版本。他们以先前实验室工作Latent Diffusion模型为基础,并得到了 LAION 和 Eleuther AI 的关键支持。
与最初的 V1版本相比,Stable Diffusion 2.0提供了许多重大的改进和特性,让我们深入了解一下它们。
资料来源: A16z 和 Github
来自慕尼黑大学的 Robin Rombach (Stability AI)和 Patrick Esser (Runway ML)的团队,在Björn Ommer 教授的领导下,主导了最初V1版本版本。他们以先前实验室工作Latent Diffusion模型为基础,并得到了 LAION 和 Eleuther AI 的关键支持。
与最初的 V1版本相比,Stable Diffusion 2.0提供了许多重大的改进和特性,让我们深入了解一下它们。
![]() 新的文生图Diffusion模型
Stable Diffusion 2.0版本包括使用一种全新的文本编码器(OpenCLIP)训练的鲁棒文生图模型,该模型由 LAION 公司在Stability AI 公司的支持下开发,与早期的 V1版本相比,它极大地提高了生成图像的质量。本版本中的文生图模型可以生成默认分辨率为512x512像素和768x768像素的图像。
这些模型是在Stability AI 下面的 DeepFloyd 团队创建的 LAION-5B (https://laion.ai/blog/laion-5b/)
数据集的美学子集上所训练的,然后进一步过滤,使用 LAION 的 NSFW 过滤器去除成人内容。
新的文生图Diffusion模型
Stable Diffusion 2.0版本包括使用一种全新的文本编码器(OpenCLIP)训练的鲁棒文生图模型,该模型由 LAION 公司在Stability AI 公司的支持下开发,与早期的 V1版本相比,它极大地提高了生成图像的质量。本版本中的文生图模型可以生成默认分辨率为512x512像素和768x768像素的图像。
这些模型是在Stability AI 下面的 DeepFloyd 团队创建的 LAION-5B (https://laion.ai/blog/laion-5b/)
数据集的美学子集上所训练的,然后进一步过滤,使用 LAION 的 NSFW 过滤器去除成人内容。
![]() Stable Diffusion 2.0以768x768图像分辨率生成的图像示例。
Stable Diffusion 2.0还包括一个高阶Diffusion模型,将图像分辨率提高了4倍。下面是我们的模型将低分辨率生成的图像(128x128)升级为高分辨率图像(512x512)的示例。Stable Diffusion 2.0现在可以生成分辨率为2048x2048-甚至更高的图像。
Stable Diffusion 2.0以768x768图像分辨率生成的图像示例。
Stable Diffusion 2.0还包括一个高阶Diffusion模型,将图像分辨率提高了4倍。下面是我们的模型将低分辨率生成的图像(128x128)升级为高分辨率图像(512x512)的示例。Stable Diffusion 2.0现在可以生成分辨率为2048x2048-甚至更高的图像。
![]() 左: 128x128低分辨率图像,右: 512x512分辨率图像由高阶模型制作。
Depth-to-Image Diffusion 模型
新的以深度信息为指引的stable diffusion模型,称为 depth2img,扩展了 V1版本中的图像到图像特性,为创造性应用提供了全新的可能性。Depth2img 可以推断输入图像的深度信息(使用现有模型),然后利用文本和深度信息生成新图像。
左: 128x128低分辨率图像,右: 512x512分辨率图像由高阶模型制作。
Depth-to-Image Diffusion 模型
新的以深度信息为指引的stable diffusion模型,称为 depth2img,扩展了 V1版本中的图像到图像特性,为创造性应用提供了全新的可能性。Depth2img 可以推断输入图像的深度信息(使用现有模型),然后利用文本和深度信息生成新图像。
内容中包含的图片若涉及版权问题,请及时与我们联系删除



评论
沙发等你来抢