
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 GR - 图形学
转自爱可可爱生活
摘要:基于音频空间分解的实时神经辐射说话人像合成、从音乐中生成可编辑舞蹈、基于潜扩散模型的高效视频生成、基于神经辐射场的多视分割和感知补全、带KL惩罚的强化学习看做贝叶斯推理更合适、工业级规模弱监督端到端语音识别、基于神经动态图像的渲染、基于动态词法路由条件Token交互的有效且高效多向量检索、未见语言的跨语种少样本学习
1、[CV] Real-time Neural Radiance Talking Portrait Synthesis via Audio-spatial Decomposition
J Tang, K Wang, H Zhou, X Chen, D He, T Hu, J Liu, G Zeng, J Wang
[Baidu Inc & Peking University & The University of Sydney]
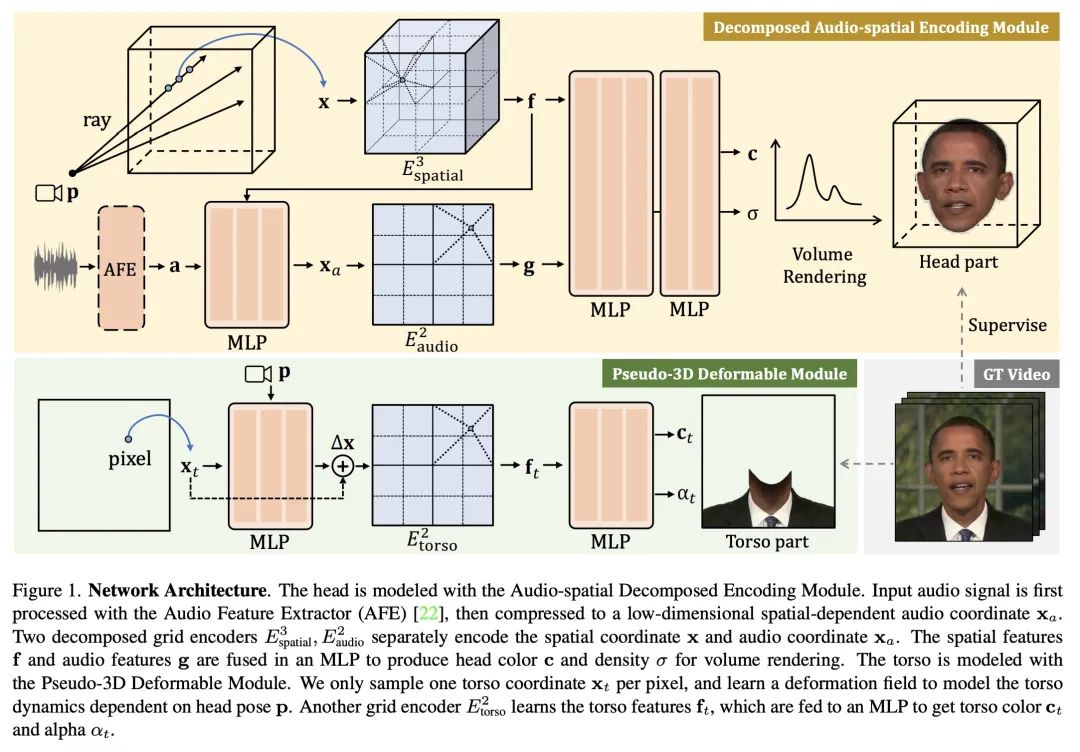
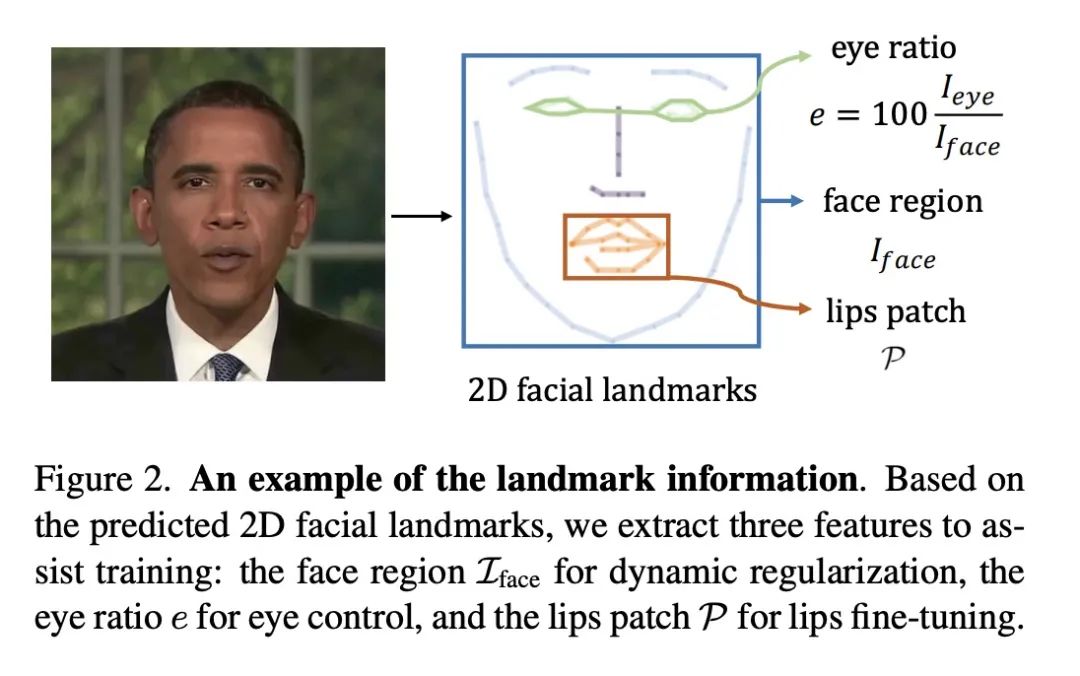
基于音频空间分解的实时神经辐射说话人像合成。虽然动态神经辐射场(NeRF)在高保真3D人像建模方面取得了成功,但其缓慢的训练和推理速度严重阻碍了其潜在应用。本文提出一种高效的基于NeRF的框架,通过利用最近基于网格的NeRF的成功,实现了实时合成说话人像以及更快的收敛。本文的关键思想是将固有的高维说话人像表示法分解为三个低维特征网格。具体来说,一个分解的音频空间编码模块用一个3D空间网格和一个2D音频网格来模拟动态头部。肢体在一个轻量的伪3D可变形模块中用另一个2D网格处理。这两个模块在良好的渲染质量的前提下保证了效率。大量实验表明,所提出方法可以生成逼真的、与音频-嘴唇同步的说话人像视频,同时与之前的方法相比也非常高效。
While dynamic Neural Radiance Fields (NeRF) have shown success in high-fidelity 3D modeling of talking portraits, the slow training and inference speed severely obstruct their potential usage. In this paper, we propose an efficient NeRF-based framework that enables real-time synthesizing of talking portraits and faster convergence by leveraging the recent success of grid-based NeRF. Our key insight is to decompose the inherently high-dimensional talking portrait representation into three low-dimensional feature grids. Specifically, a Decomposed Audio-spatial Encoding Module models the dynamic head with a 3D spatial grid and a 2D audio grid. The torso is handled with another 2D grid in a lightweight Pseudo-3D Deformable Module. Both modules focus on efficiency under the premise of good rendering quality. Extensive experiments demonstrate that our method can generate realistic and audio-lips synchronized talking portrait videos, while also being highly efficient compared to previous methods.
https://arxiv.org/abs/2211.12368


2、[AS] EDGE: Editable Dance Generation From Music
J Tseng, R Castellon, C. K Liu
[Stanford University]
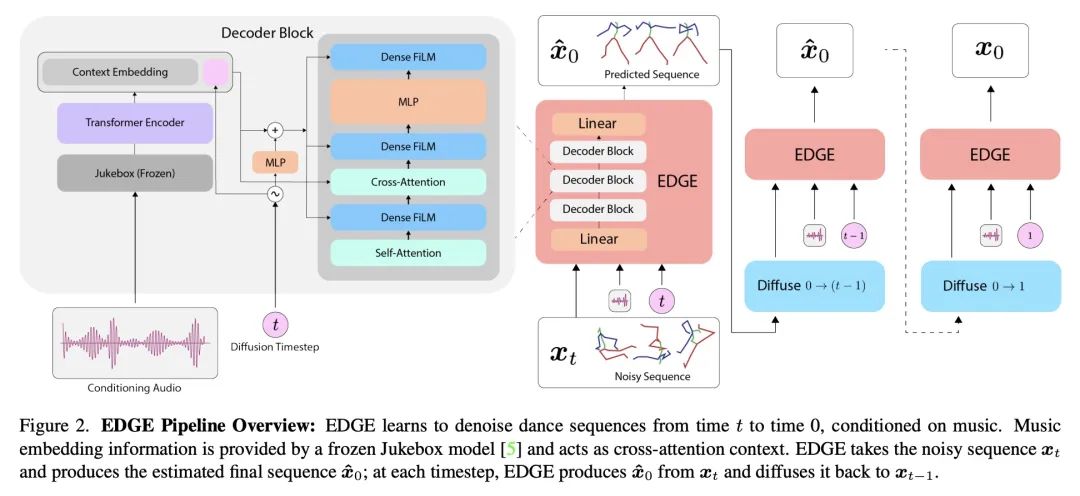
EDGE:从音乐中生成可编辑舞蹈。舞蹈是一种重要的人类艺术形式,但创造新舞蹈可能是困难和耗时的。本文提出可编辑舞蹈生成(EDGE),一种最先进的可编辑舞蹈生成方法,能在忠实于输入音乐的同时创造出逼真的、物理上合理的舞蹈。EDGE使用一个基于Transformer的扩散模型与Jukebox(一种强大的音乐特征提取器)相结合,并赋予适合舞蹈的强大编辑能力,包括联合级调节和中间级调节。本文提出一种新的物理可信度指标,并通过(1)物理可信度、节拍对齐和多样性基准的多个定量指标,以及更重要的(2)大规模用户研究,广泛评估所提出方法产生的舞蹈质量,显示出比之前最先进方法有明显的改进。
Dance is an important human art form, but creating new dances can be difficult and time-consuming. In this work, we introduce Editable Dance GEneration (EDGE), a state-of-the-art method for editable dance generation that is capable of creating realistic, physically-plausible dances while remaining faithful to the input music. EDGE uses a transformer-based diffusion model paired with Jukebox, a strong music feature extractor, and confers powerful editing capabilities well-suited to dance, including joint-wise conditioning, and in-betweening. We introduce a new metric for physical plausibility, and evaluate dance quality generated by our method extensively through (1) multiple quantitative metrics on physical plausibility, beat alignment, and diversity benchmarks, and more importantly, (2) a large-scale user study, demonstrating a significant improvement over previous state-of-the-art methods. Qualitative samples from our model can be found at our website.
https://arxiv.org/abs/2211.10658



3、[CV] MagicVideo: Efficient Video Generation With Latent Diffusion Models
D Zhou, W Wang, H Yan, W Lv, Y Zhu, J Feng
[ByteDance Inc.]
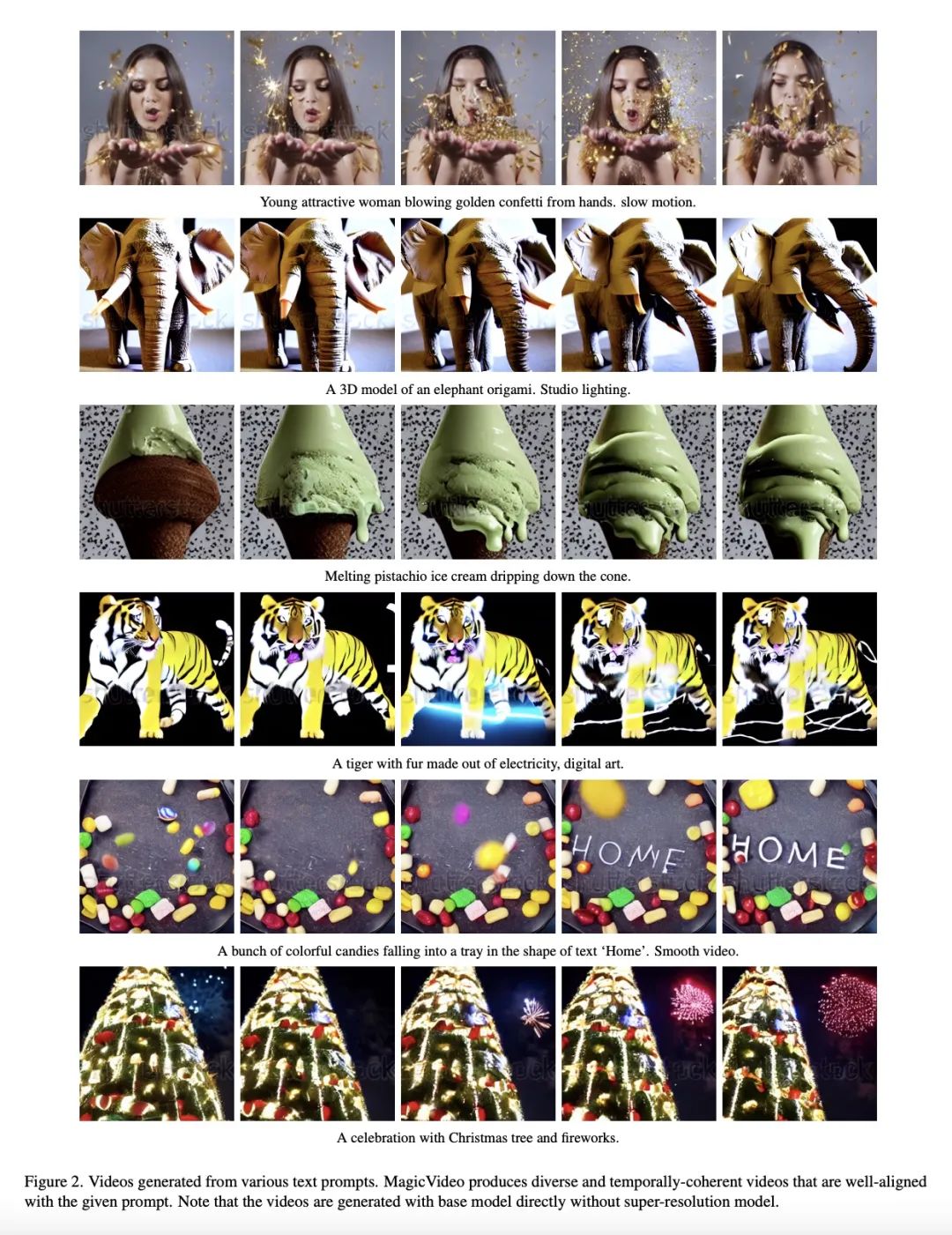
MagicVideo:基于潜扩散模型的高效视频生成。本文提出一种基于潜扩散模型的高效文本到视频生成框架MagicVideo。给定一段文本描述,MagicVideo可生成与文本内容高度相关的照片级逼真的视频片段。利用所提出的高效潜3D U-Net设计,MagicVideo可以在一块GPU卡上生成256x256空间分辨率的视频片段,比最近的视频扩散模型(VDM)快64倍。与以往在RGB空间中从头开始训练视频生成的工作不同,本文提出在低维潜空间中生成视频片段。进一步利用预训练好的文本到图像生成式U-Net模型的所有卷积算子权重,以加快训练速度。为实现这一目标,本文提出两个新的设计,以使U-Net解码器适应视频数据:一个用于图像到视频分布调整的轻量帧适配器和一个用于捕捉帧时间依赖性的定向时间注意力模块。整个生成过程是在一个预训练好的变体自编码器的低维潜空间进行的。实验证明MagicVideo既能生成现实的视频内容,也能生成照片级逼真的想象内容,在质量和计算成本方面有所取舍。
We present an efficient text-to-video generation framework based on latent diffusion models, termed MagicVideo. Given a text description, MagicVideo can generate photo-realistic video clips with high relevance to the text content. With the proposed efficient latent 3D U-Net design, MagicVideo can generate video clips with 256x256 spatial resolution on a single GPU card, which is 64x faster than the recent video diffusion model (VDM). Unlike previous works that train video generation from scratch in the RGB space, we propose to generate video clips in a low-dimensional latent space. We further utilize all the convolution operator weights of pre-trained text-to-image generative U-Net models for faster training. To achieve this, we introduce two new designs to adapt the U-Net decoder to video data: a framewise lightweight adaptor for the image-to-video distribution adjustment and a directed temporal attention module to capture frame temporal dependencies. The whole generation process is within the low-dimension latent space of a pre-trained variation auto-encoder. We demonstrate that MagicVideo can generate both realistic video content and imaginary content in a photo-realistic style with a trade-off in terms of quality and computational cost. Refer to this https URL for more examples.
https://arxiv.org/abs/2211.11018


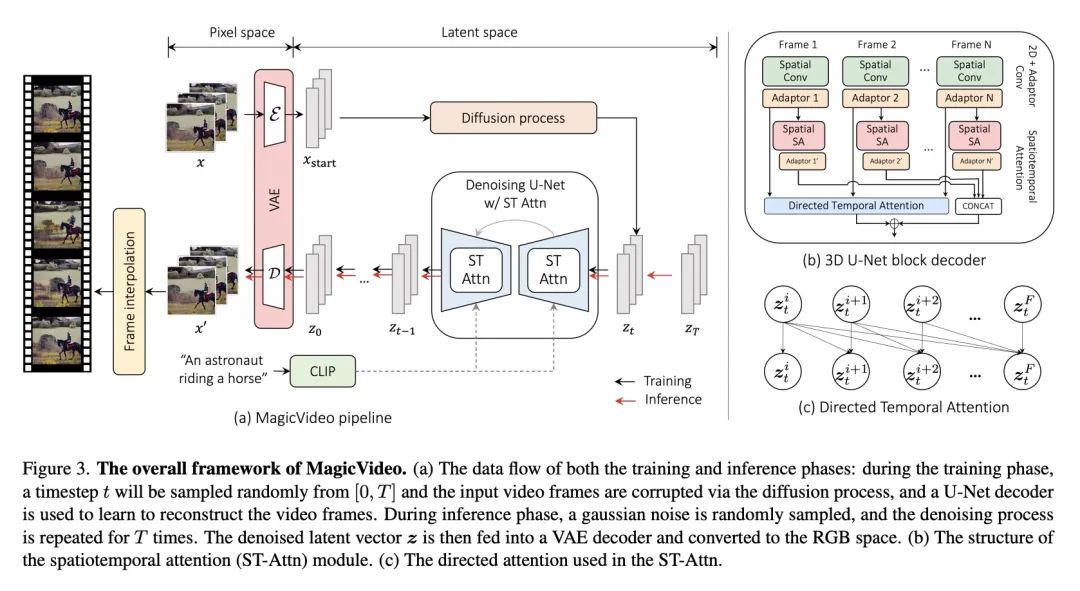
4、[CV] SPIn-NeRF: Multiview Segmentation and Perceptual Inpainting with Neural Radiance Fields
A Mirzaei, T Aumentado-Armstrong, K G. Derpanis...
[Samsung AI Centre Toronto & University of Toronto]
SPIn-NeRF:基于神经辐射场的多视分割和感知补全。神经辐射场(NeRF)已经成为一种流行的新视图合成方法。虽然NeRF正迅速被应用于更广泛的领域,但直观编辑NeRF场景仍然是一个公开的挑战。一个重要的编辑任务是从3D场景中移除不需要的物体,同事保证被替换区域在视觉上是合理的,并与其背景相一致。本文将这一任务称为3D补全(3D inpainting)。在3D中,解决方案必须在多个视图中保持一致,并且在几何上有效。本文提出一种新的3D补全方法,以解决这些挑战。给出一小部分摆放的图像和单幅输入图像中的稀疏标注,所提出的框架首先快速获得目标物体的3D分割蒙版。利用该蒙版,引入一种基于感知优化的方法,利用学到的2D图像着色器,将其信息提炼到3D空间,同时确保视图一致性。本文还通过引入一种由具有挑战性的真实世界场景组成的数据集来解决缺乏评估3D场景涂抹方法多样化基准的问题。该数据集包含了有目标物体和非目标物体的同一场景的视图,使3D补全任务的基准更加原则化。本文首先证明了所提出方法与基于NeRF的方法和2D分割方法相比在多视图分割上的优越性,然后对3D补全涂务进行了评估,达到了相比其他基于NeRF的算法以及强大的2D图像补全基线的最佳性能。
Neural Radiance Fields (NeRFs) have emerged as a popular approach for novel view synthesis. While NeRFs are quickly being adapted for a wider set of applications, intuitively editing NeRF scenes is still an open challenge. One important editing task is the removal of unwanted objects from a 3D scene, such that the replaced region is visually plausible and consistent with its context. We refer to this task as 3D inpainting. In 3D, solutions must be both consistent across multiple views and geometrically valid. In this paper, we propose a novel 3D inpainting method that addresses these challenges. Given a small set of posed images and sparse annotations in a single input image, our framework first rapidly obtains a 3D segmentation mask for a target object. Using the mask, a perceptual optimizationbased approach is then introduced that leverages learned 2D image inpainters, distilling their information into 3D space, while ensuring view consistency. We also address the lack of a diverse benchmark for evaluating 3D scene inpainting methods by introducing a dataset comprised of challenging real-world scenes. In particular, our dataset contains views of the same scene with and without a target object, enabling more principled benchmarking of the 3D inpainting task. We first demonstrate the superiority of our approach on multiview segmentation, comparing to NeRFbased methods and 2D segmentation approaches. We then evaluate on the task of 3D inpainting, establishing state-ofthe-art performance against other NeRF manipulation algorithms, as well as a strong 2D image inpainter baseline
https://arxiv.org/abs/2211.12254


5、[LG] RL with KL penalties is better viewed as Bayesian inference
T Korbak, E Perez, C L Buckley
[University of Sussex & New York University]
带KL惩罚的强化学习看做贝叶斯推理更合适。强化学习(RL)常用于微调大型语言模型(LM),如GPT-3,以惩罚其生成序列的不良特征,如攻击性、社会偏见、有害性或虚假性。强化学习表述涉及将语言模型视为一种策略,并更新它以最大化奖励函数期望值,该函数捕捉了人类的偏好,如非攻击性。本文分析了将语言模型作为强化学习策略的相关挑战,并展示了避免这些挑战需要超越强化学习范式的方法。本文首先观察到,标准的强化学习方法作为微调语言模型的目标是有缺陷的,因为它导致分布坍缩:将语言模型变成一个退化的分布。本文分析了KL正则化强化学习,一种广泛使用的微调语言模型的方法,它额外地限制了微调语言模型在Kullback-Leibler(KL)散度方面接近其原始分布。本文表明,KL正则化强化学习等同于变分推理:近似于贝叶斯后验,指定如何更新先验语言模型以符合奖励函数所提供的证据。本文认为,KL正则化强化学习的这种贝叶斯推理视角比通常采用的强化学习的视角更有洞察力。贝叶斯推理视角解释了KL正则化强化学习是如何避免分布坍缩问题的,并为其目标提供了第一性原理的推导。虽然这个目标恰好等同于强化学习(有一个特定参数奖励选择),但存在其他微调语言模型的目标,这些目标不再等同于强化学习。这一观察引出了一个更普遍的问题。对于微调语言模型这样的问题,强化学习不是一个适当的形式框架。这些问题看作是贝叶斯推理更合适:逼近一个预定义的目标分布。
Reinforcement learning (RL) is frequently employed in fine-tuning large language models (LMs), such as GPT-3, to penalize them for undesirable features of generated sequences, such as offensiveness, social bias, harmfulness or falsehood. The RL formulation involves treating the LM as a policy and updating it to maximise the expected value of a reward function which captures human preferences, such as non-offensiveness. In this paper, we analyze challenges associated with treating a language model as an RL policy and show how avoiding those challenges requires moving beyond the RL paradigm. We start by observing that the standard RL approach is flawed as an objective for fine-tuning LMs because it leads to distribution collapse: turning the LM into a degenerate distribution. Then, we analyze KL-regularised RL, a widely used recipe for fine-tuning LMs, which additionally constrains the fine-tuned LM to stay close to its original distribution in terms of Kullback-Leibler (KL) divergence. We show that KL-regularised RL is equivalent to variational inference: approximating a Bayesian posterior which specifies how to update a prior LM to conform with evidence provided by the reward function. We argue that this Bayesian inference view of KL-regularised RL is more insightful than the typically employed RL perspective. The Bayesian inference view explains how KL-regularised RL avoids the distribution collapse problem and offers a first-principles derivation for its objective. While this objective happens to be equivalent to RL (with a particular choice of parametric reward), there exist other objectives for fine-tuning LMs which are no longer equivalent to RL. That observation leads to a more general point: RL is not an adequate formal framework for problems such as fine-tuning language models. These problems are best viewed as Bayesian inference: approximating a pre-defined target distribution.
https://arxiv.org/abs/2205.11275


另外几篇值得关注的论文:
[CL] SpeechNet: Weakly Supervised, End-to-End Speech Recognition at Industrial Scale
SpeechNet:工业级规模弱监督端到端语音识别
R Tang, K Kumar, G Yang, A Pandey, Y Mao, V Belyaev, M Emmadi, C Murray...
[Comcast Applied AI & University of Waterloo] https://arxiv.org/abs/2211.11740

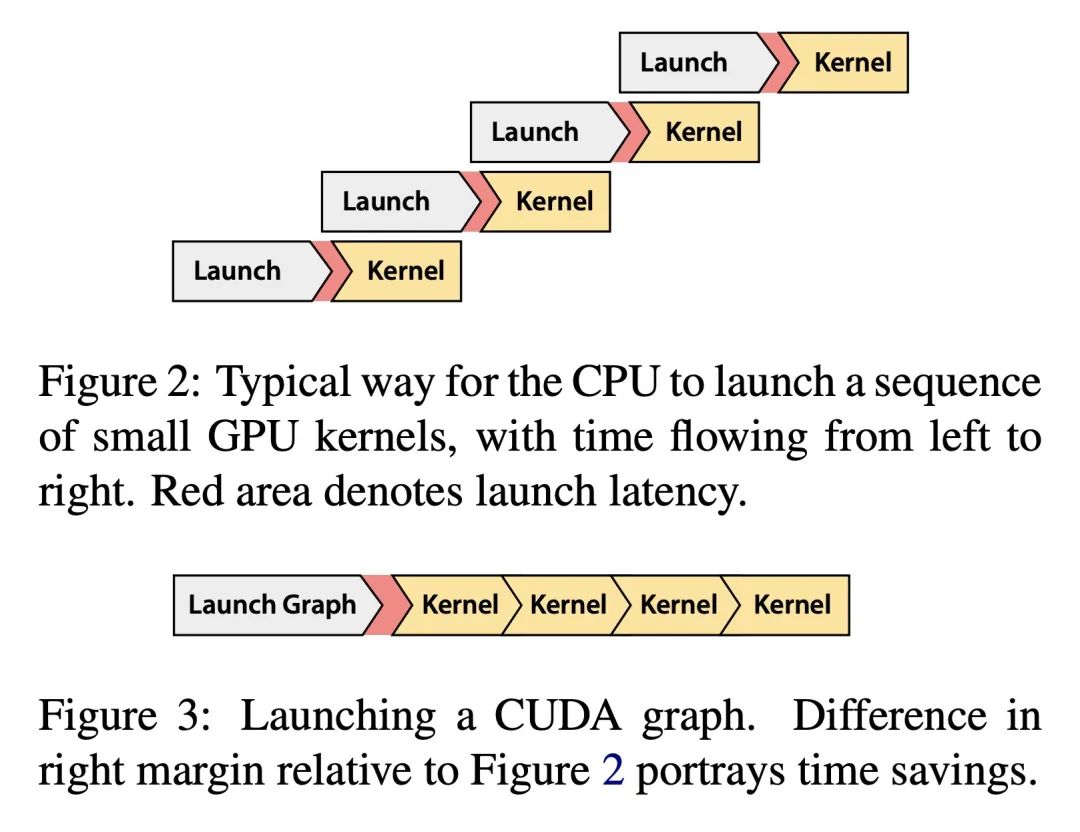
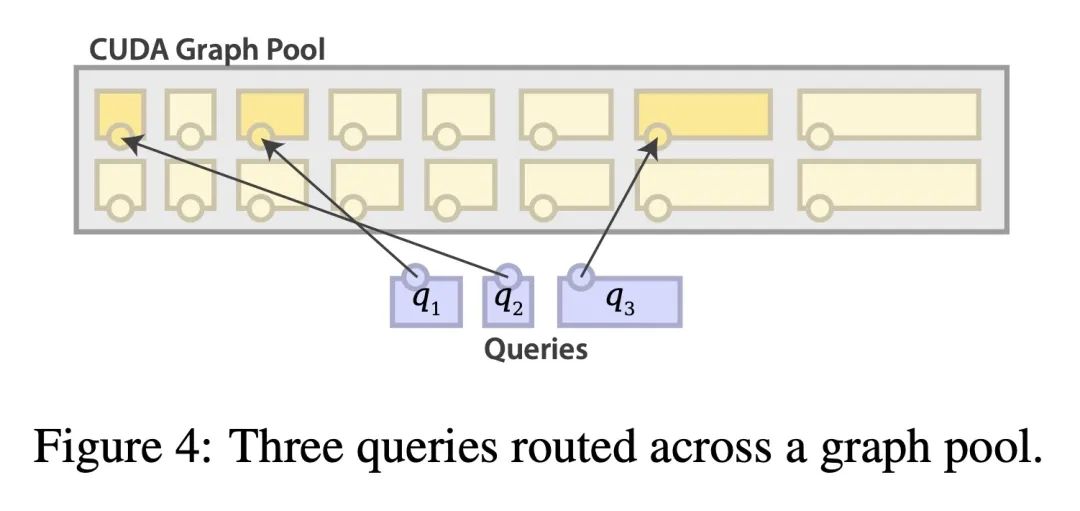
[CV] DynIBaR: Neural Dynamic Image-Based Rendering
DynIBaR:基于神经动态图像的渲染
Z Li, Q Wang, F Cole, R Tucker, N Snavely
[Google Research & Cornell Tech]
https://arxiv.org/abs/2211.11082


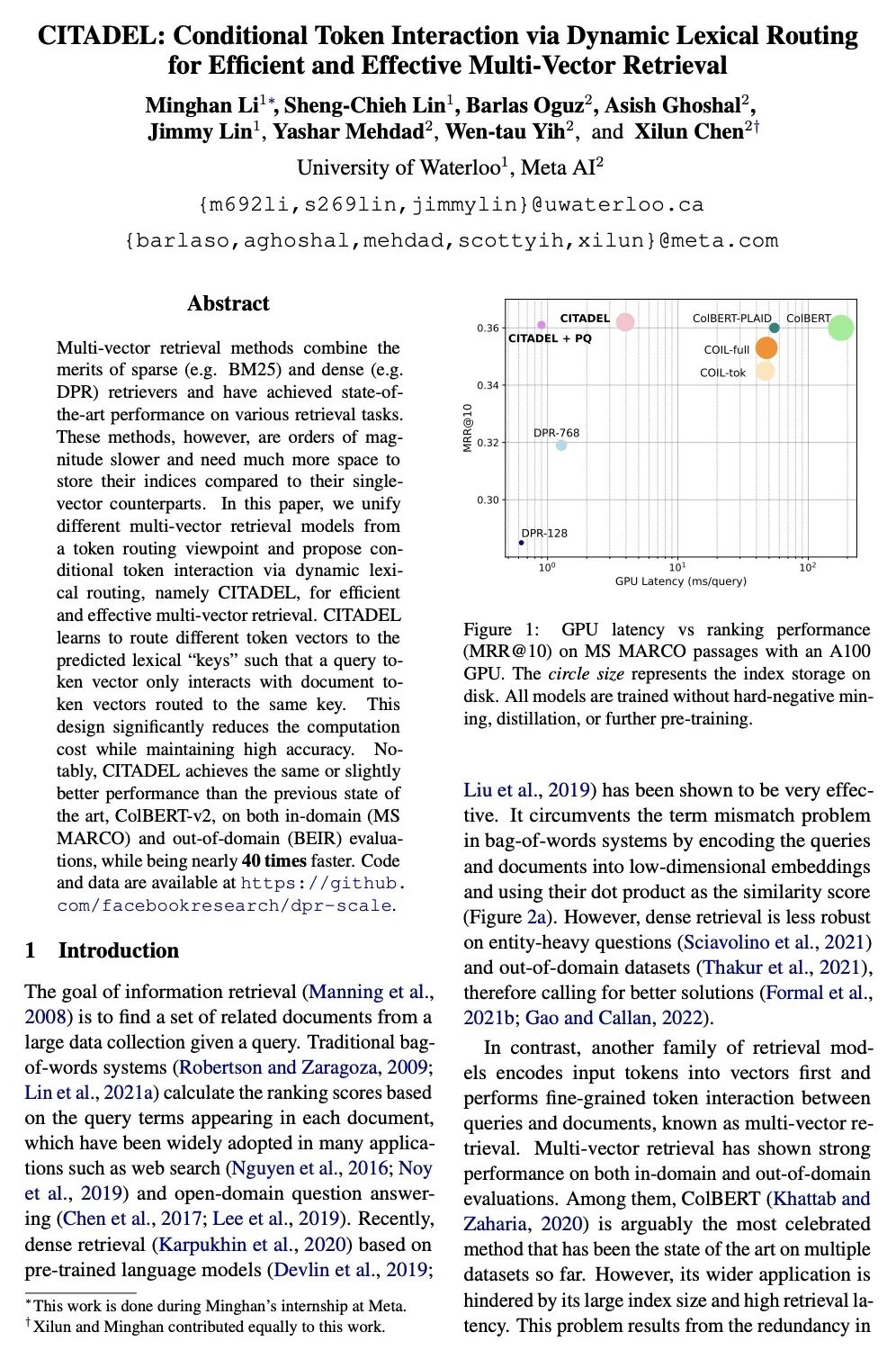
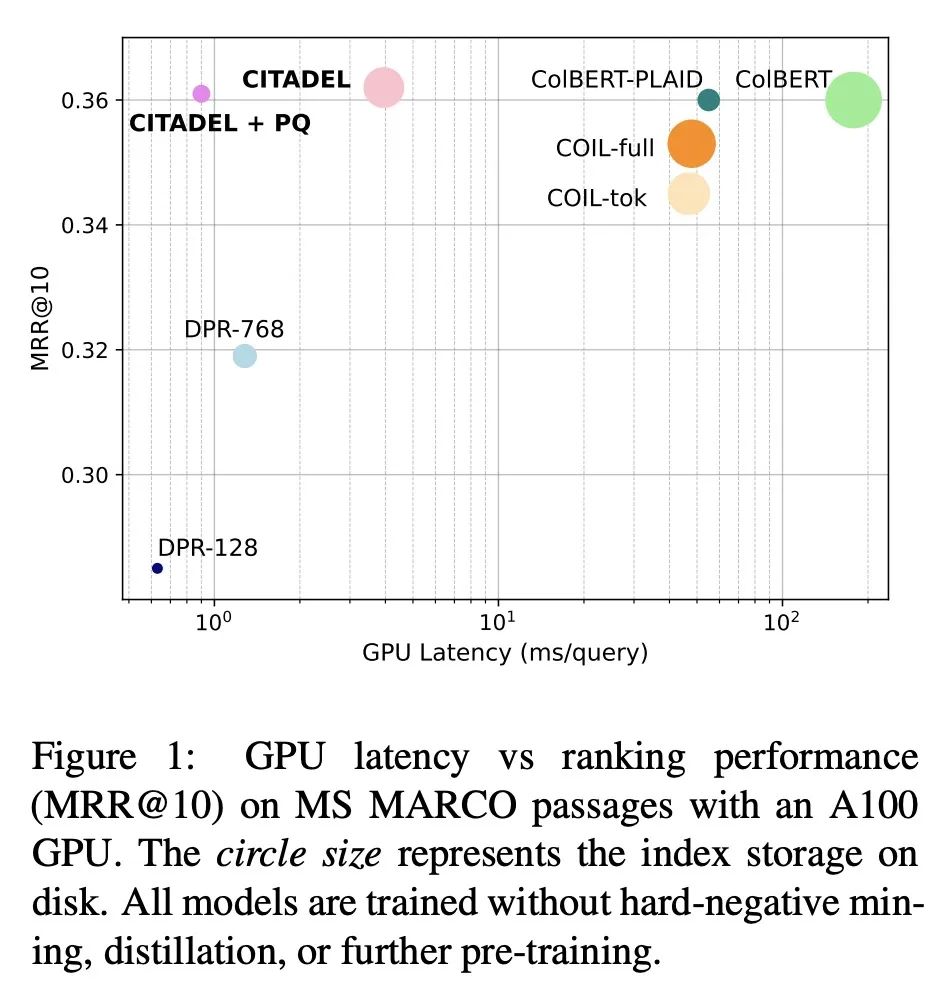
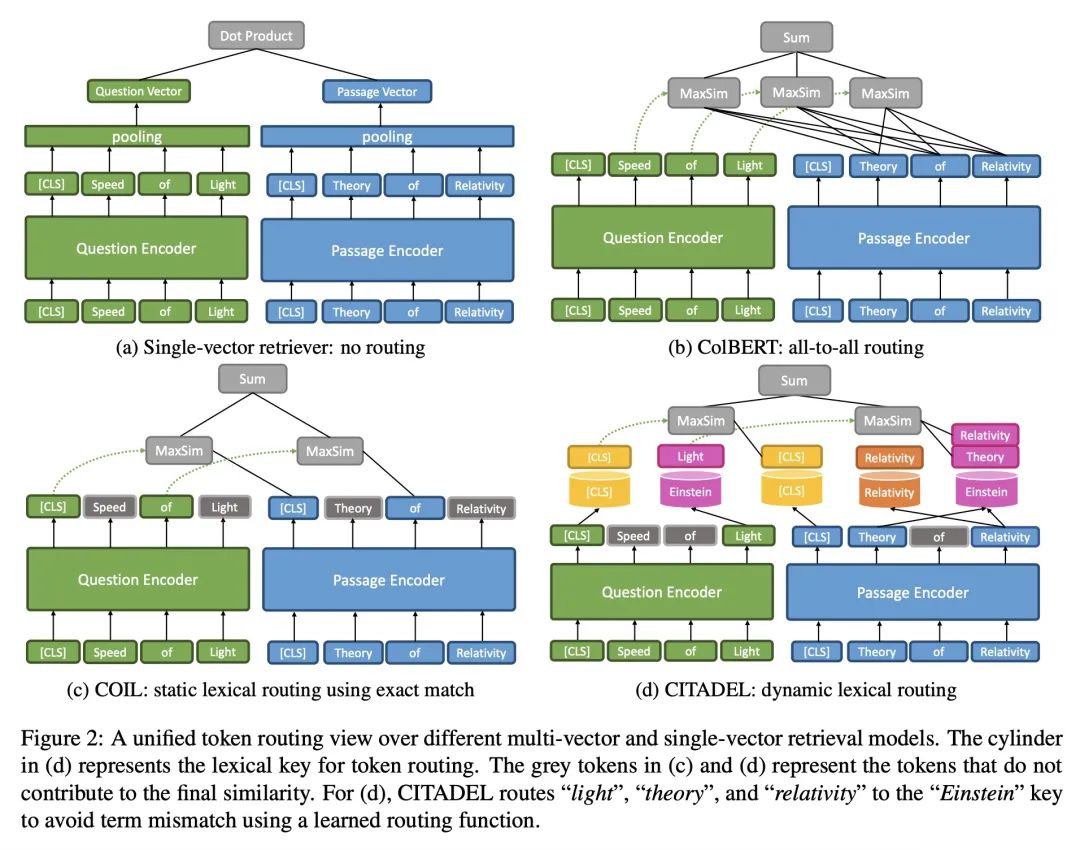
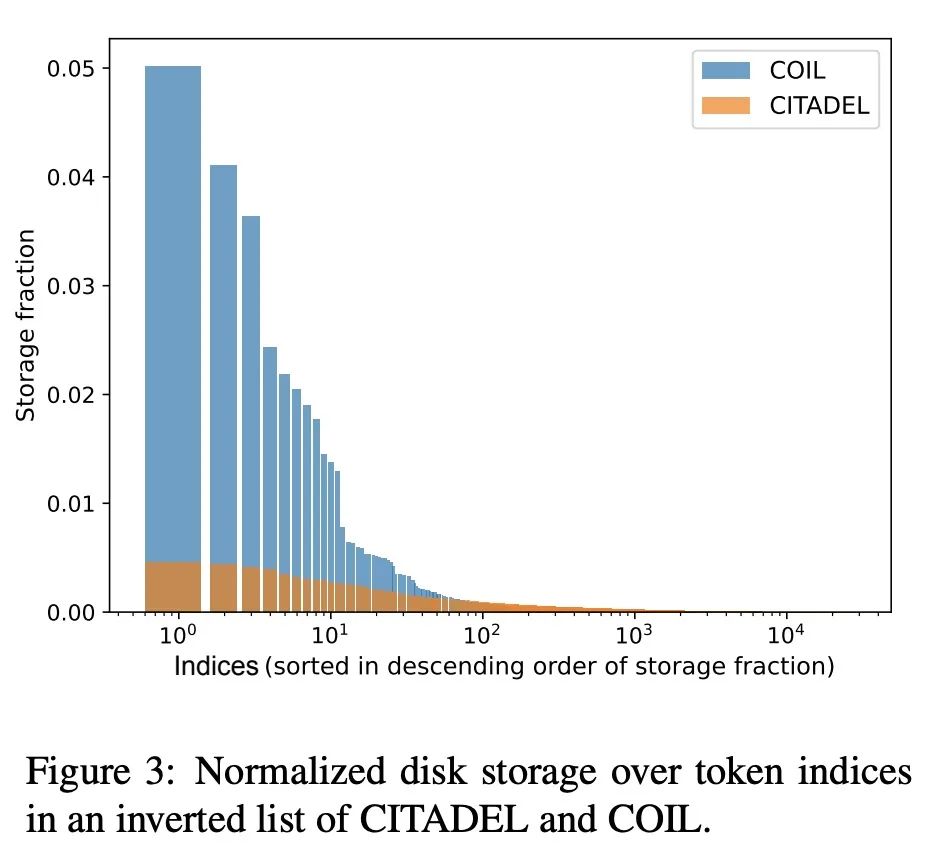
[CL] CITADEL: Conditional Token Interaction via Dynamic Lexical Routing for Efficient and Effective Multi-Vector Retrieval
CITADEL:基于动态词法路由条件Token交互的有效且高效多向量检索
M Li, S Lin, B Oguz, A Ghoshal, J Lin, Y Mehdad, W Yih, X Chen
[Meta AI & University of Waterloo]
https://arxiv.org/abs/2211.10411
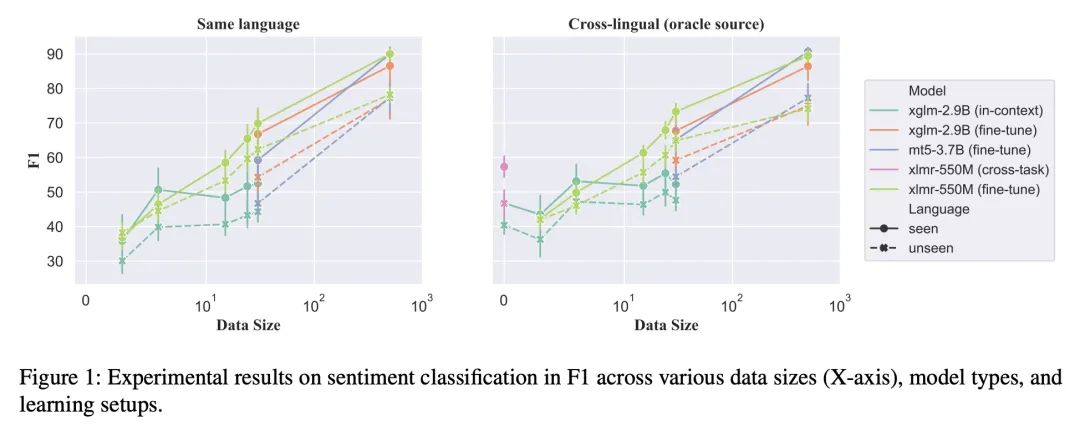
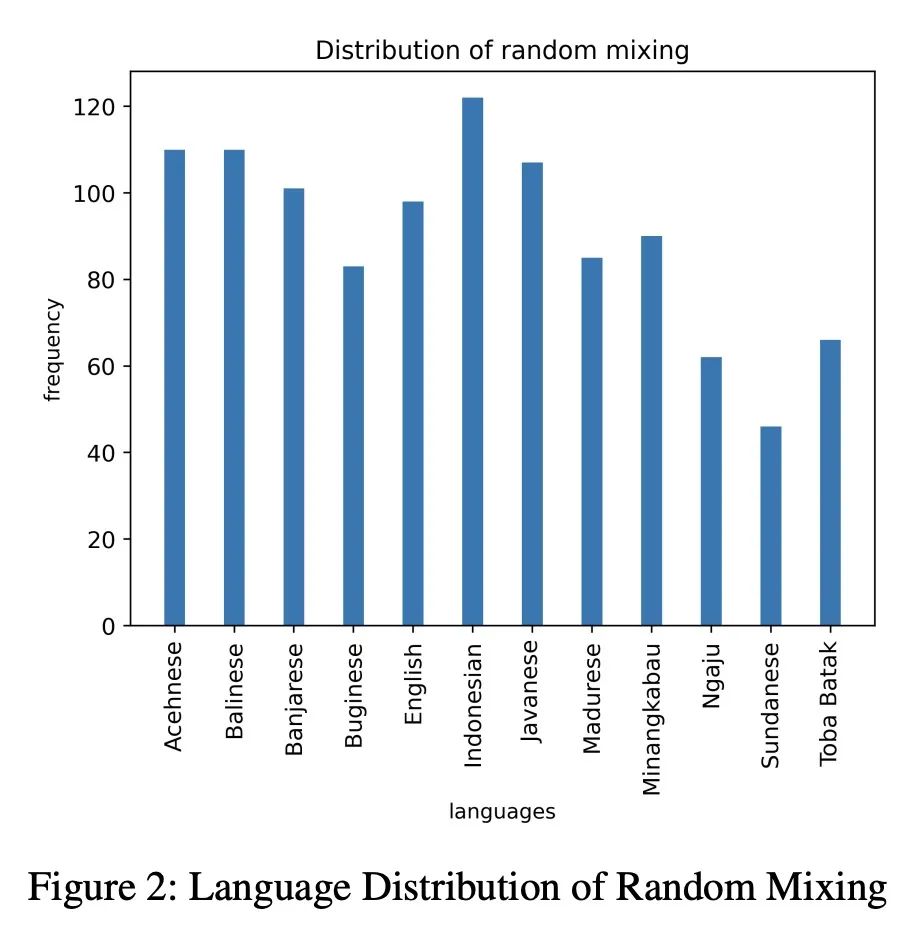
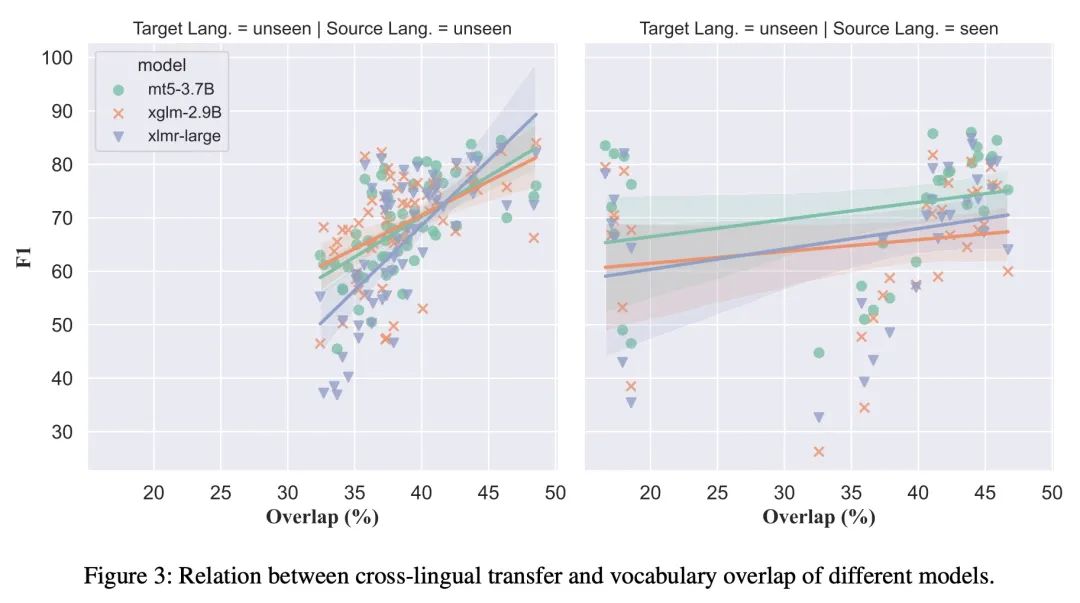
[CL] Cross-lingual Few-Shot Learning on Unseen Languages
未见语言的跨语种少样本学习
G Winata, S Wu, M Kulkarni, T Solorio, D Preotiuc-Pietro
[Bloomberg & Amazon Alexa AI]
https://aclanthology.org/2022.aacl-main.59.pdf

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢