
作者:Chu-Tak Lee,Qipeng Guo,Xipeng Qiu
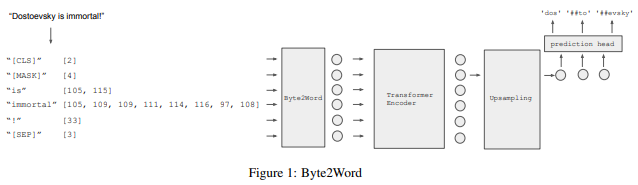
简介:本文研究新的字符感知方法。现代语言模型大多以子词作为输入,这种设计平衡了词汇量、参数数量和性能之间的权衡。然而,子词标记化仍然存在一些缺点,例如对噪声不稳健并且难以推广到新语言。此外,当前扩大模型的趋势表明,更大的模型需要更大的嵌入表示,但这使得并行化变得困难。先前关于图像分类的工作证明,将原始输入拆分为一系列的chuck包:是一种强大的、与模型无关的归纳偏差。基于这一观察,作者重新思考现有的字符感知方法,该方法采用字符级输入、但可以进行词级序列建模和预测。作者通过引入直接从字节构建单词级表示的交叉注意力网络来彻底改造这种方法,以及基于词级隐藏状态的子词级预测,以避免词级预测的时间和空间要求。结合这两项改进,作者提出了一个无标记模型,它具有用于下游任务的精简输入嵌入。作者将该方法命名为: Byte2Word,并对语言建模和文本分类进行评估。实验表明Byte2Word与BERT强子词基线:不相上下、但只占嵌入大小的 10%。作者进一步测试了作者关于合成噪声和跨语言迁移的方法,发现它在这两种设置上比基线方法都更具竞争力!
论文下载:https://arxiv.org/pdf/2211.12677.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢