
【标题】Is Reinforcement Learning (Not) for Natural Language Processing?: Benchmarks, Baselines, and Building Blocks for Natural Language Policy Optimization
【发表日期】2022.9.22
【论文链接】https://openreview.net/pdf?id=8aHzds2uUyB
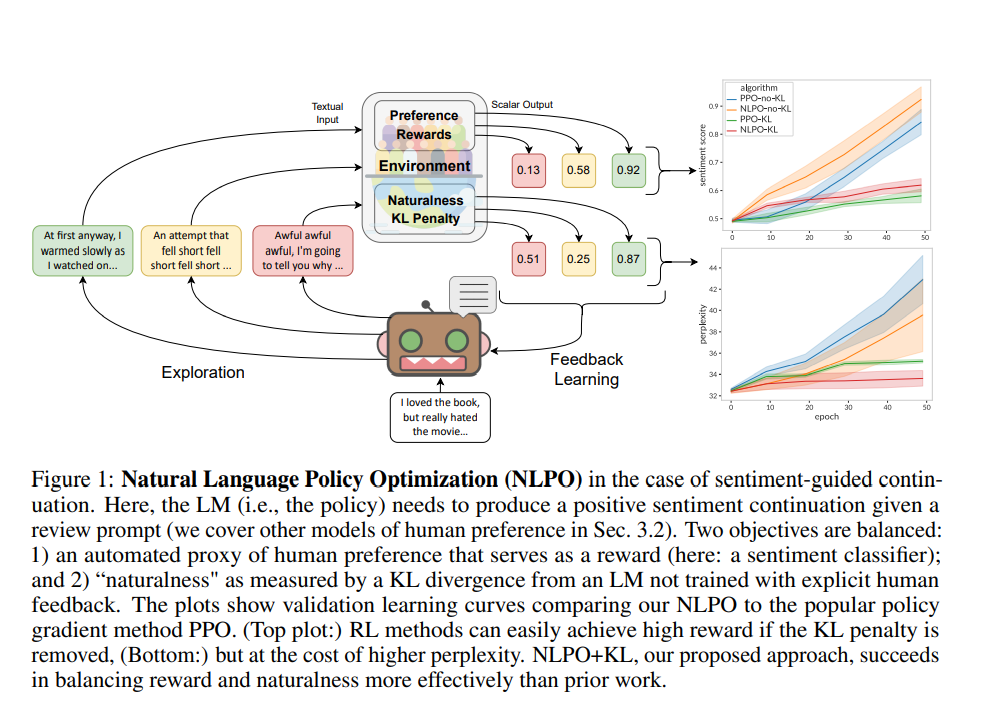
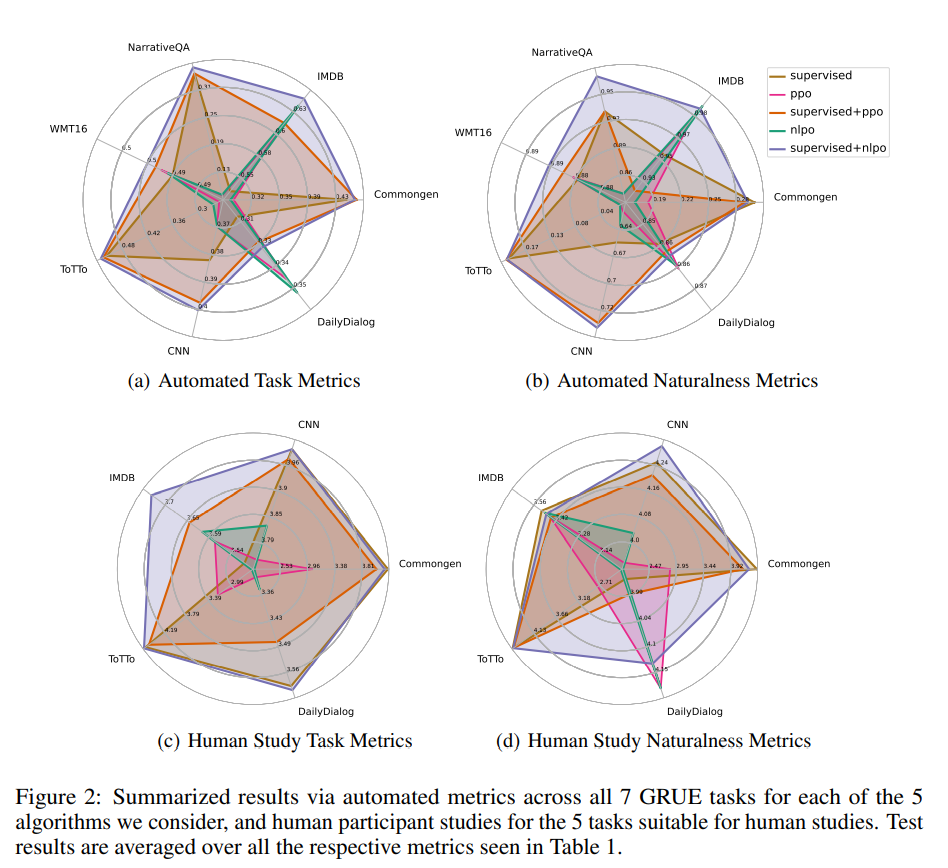
【推荐理由】本文解决了将预先训练的大型语言模型(LMs)与人类偏好相匹配的问题。如果将文本生成视为一个顺序决策问题,强化学习(RL)似乎是一个自然的概念框架。然而,将RL用于基于LM的生成面临着经验挑战,包括由于组合动作空间而导致的训练不稳定性,以及缺少为LM对齐定制的开源库和基准。因此,研究界提出了一个问题:RL是否是NLP的一个实用范式? 为了帮助回答这个问题,作者首先引入了一个开源模块库RL4LMs(语言模型强化学习),用于使用RL优化语言生成器。接下来,作者提出了GRUE(通用强化语言理解评估)基准,这是一组6个语言生成任务,它们不受目标字符串的监督,而是由捕获人类偏好的自动度量的奖励函数来监督。最后,作者介绍了一种RL算法NLPO(自然语言策略优化),该算法学习如何有效地减少语言生成中的组合动作空间。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢