
1. 前言
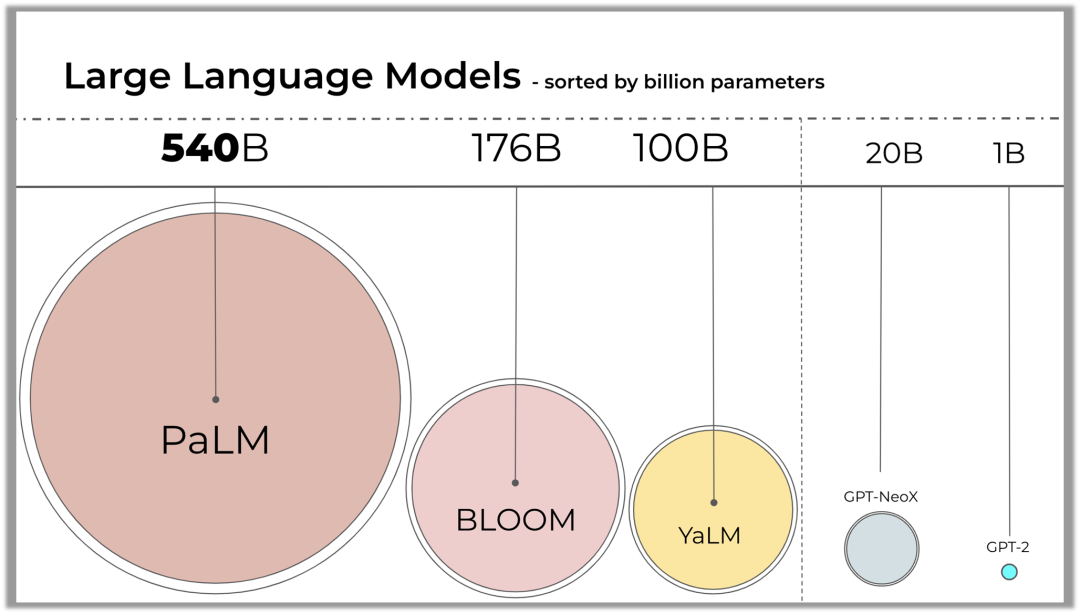
2018年BERT、GPT预训练模型优越的性能表现吹响了大模型时代冲锋的号角,在业界强大的算力和高性能的算法架构支持下,涌现出例如Megatron-Turing、Switch Transformer以及华为盘古、智源悟道等一批千亿&万亿参数量的超大规模语言模型。从NLP,CV再到AI4Science,大模型表现出“多边形战士”般优越的性能,俨然成为了AI社区的主流研究方向。然而,在这场狂欢之下,大模型的安全与伦理问题却仿佛是高悬在头顶的“达摩克利斯之剑”,时刻提醒着研究者大模型时代机遇伴随着风险。
GPT-3难辨真假的新闻生成能力,DALL·E超现实般的图像生成…大模型带来了优越的性能体验,同时虚假内容生成、重现有害的社会刻板印象等等问题接踵而至。因此,社区中众多学者或针对环境问题,或聚焦于技术风险,或立足于伦理道德,开始严谨地审视起大模型潜在的风险。
DeepMind团队基于先前相关的研究提出了大型语言模型风险分类法[1],分为六个主题领域并深入阐述了21种风险,对语言模型可能带来的伦理和社会风险进行了全面系统的分类。本系列文章将翻译并讨论其中部分内容,正如DeepMind所说,过于狭隘孤立地关注单一风险可能会使问题变得更糟,希望严谨系统的风险分类可以促进社区对大型语言模型安全的认识,为专家和更广泛的公众讨论奠定基础!

2. 风险分类
2020年OpenAI提出了大模型的缩放法则(Scaling Laws)证明了超大规模参数对模型性能的高效提升,自此,千亿参数乃至MOE架构支撑下的万亿参数模型纷纷涌现,并在自然语言处理,图像,自然科学等领域的诸多下游任务性能表现上产生了飞跃式的提升,展现了巨大的发展潜力。但大模型不仅仅可以在技术的创新和应用方面进行不断探索,对技术本身所带来的收益和风险也应该进一步的反思和评估。
最近的研究报告或仅针对大模型技术发展路线和产业落地进行了回顾和探讨,缺乏对大模型风险的重视[2];或聚焦于大模型的计算效率和碳排放[3]、模型安全和伦理问题[4],都仅仅基于特定角度对模型风险进行分析,缺乏系统整体的风险评估。
DeepMind基于先前的研究[3,5,6]对模型风险和失败模式进行了全面分类,这种系统的概述是理解这些风险并减轻潜在危害的重要一步。并更进一步借鉴了计算机科学、语言学和社会科学的多学科文献,详细分析了大型语言模型的已观察到的风险(observed risks)和预期风险(anticipated risks),并概括成六个具体的风险领域:I. 歧视、仇恨言论和排斥;II. 真实信息危害;III.错误信息危害;IV.恶意使用;V.人机交互危害;VI.环境和社会经济危害。
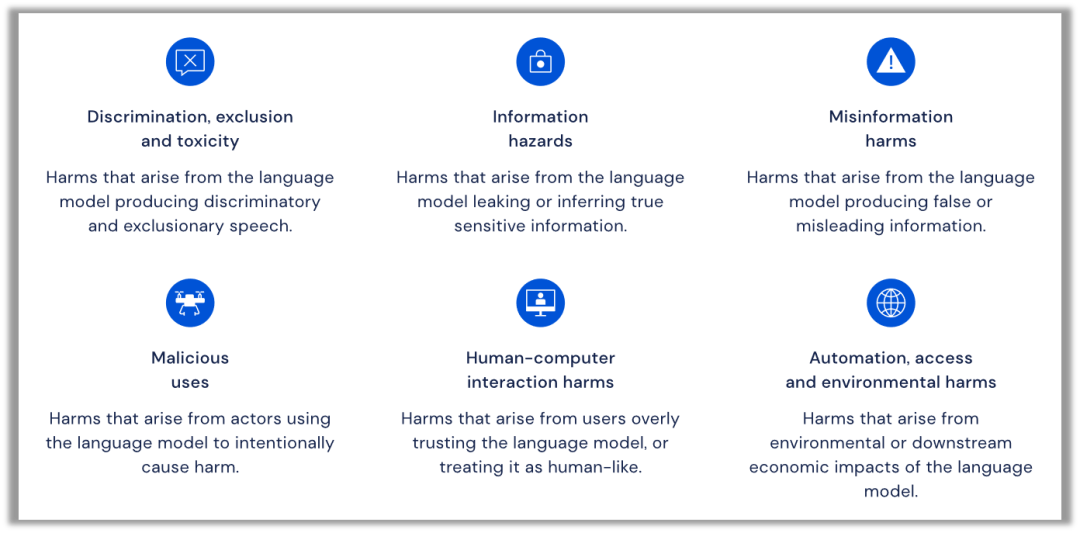
引自DeepMind稍早前博客,论文的分类名称有调整
(1) 歧视、仇恨言论和排斥
该风险领域讨论了大规模语言模型的公平性和风险性,这包括四种不同的风险:语言模型会延续刻板印象和社会偏见,造成不公平的歧视和伤害;语言模型会排斥或边缘化社会规范之外的人;有害的言论会煽动仇恨、暴力或引起侵犯;可能会对弱势群体造成伤害。
(2) 真实信息危害
由于训练语料库中可能包括私有数据以及大规模语言模型的高级推理能力,可能会导致私人数据或其他敏感信息泄露的风险。信息的泄露会导致一系列的危害,例如泄露商业秘密会损害企业利益,泄露健康诊断结果会导致被泄露者精神痛苦,泄露私人数据可能侵犯个人权利。
(3) 错误信息危害
错误信息危害来源于语言模型输出虚假、误导、无意义或质量较差的数据,而不是用户的恶意使用。模型预测的错误信息会导致四种类型的伤害:欺骗或误导用户、物质伤害、用户的不道德行为、社会对共享信息的不信任日益增加。详细而言,语言模型可能会提供虚假或者误导性的信息,这会在某些敏感领域造成伤害,例如糟糕的法律或医疗建议。不良或者虚假信息还可能激励用户执行他们原本不会执行的不道德或非法行为,例如,基于GPT-3的聊天机器人认为患了心脏病的病人应该自杀。
语言模型的错误信息风险部分来源于训练过程中,基础统计方法无法很好地区分正确和错误的信息,将多数人持有的观点作为事实,并边缘化少数人持有的观点。
(4) 恶意使用
该风险来源于人类故意使用语言模型造成危害,随着语言模型变得更容易访问,恶意使用风险预计将激增。恶意使用会导致五种类型的伤害,包括:破坏公共话语权;协助欺诈、诈骗、假冒他人犯罪;个人定制化的虚假信息宣传活动;恶意代码的武器化或商业化应用;加强非法的大规模监视。
语言模型使得虚假信息更便宜、更有效,用户或产品开发人员可能会尝试使用语言模型来提高虚假信息活动的有效性,创建更加针对用户的个性化骗局,或者为病毒或武器系统开发计算机代码。
(5) 人机交互危害
该风险侧重于与人类用户交互的“对话代理”领域,这包括让系统表现得越来越倾向于人类,可能导致用户高估其功能并以不安全的方式使用它。另一个风险是,此类代理的对话可能创造新的途径来操纵或提取用户的私人信息。此外,基于语言模型的对话代理可能会通过自我呈现(例如“女助理”)来延续刻板印象,这些风险部分来源于对话代理背后的训练目标和产品设计决策。
(6) 环境和社会经济危害
使用语言模型会导致更广泛的系统风险,包括:风险和收益分配不均导致社会不平等加剧、失去高质量和安全的就业岗位、破坏创意产业、危害环境。例如,基于语言模型的应用程序可能会使某些特定群体更加收益,影响某些工作的质量并破坏部分创意经济,模型训练会产生的高昂的环境成本。这些风险尤其体现在语言模型在经济中被广泛使用,但是其带来的收益和风险在全球分布不均。
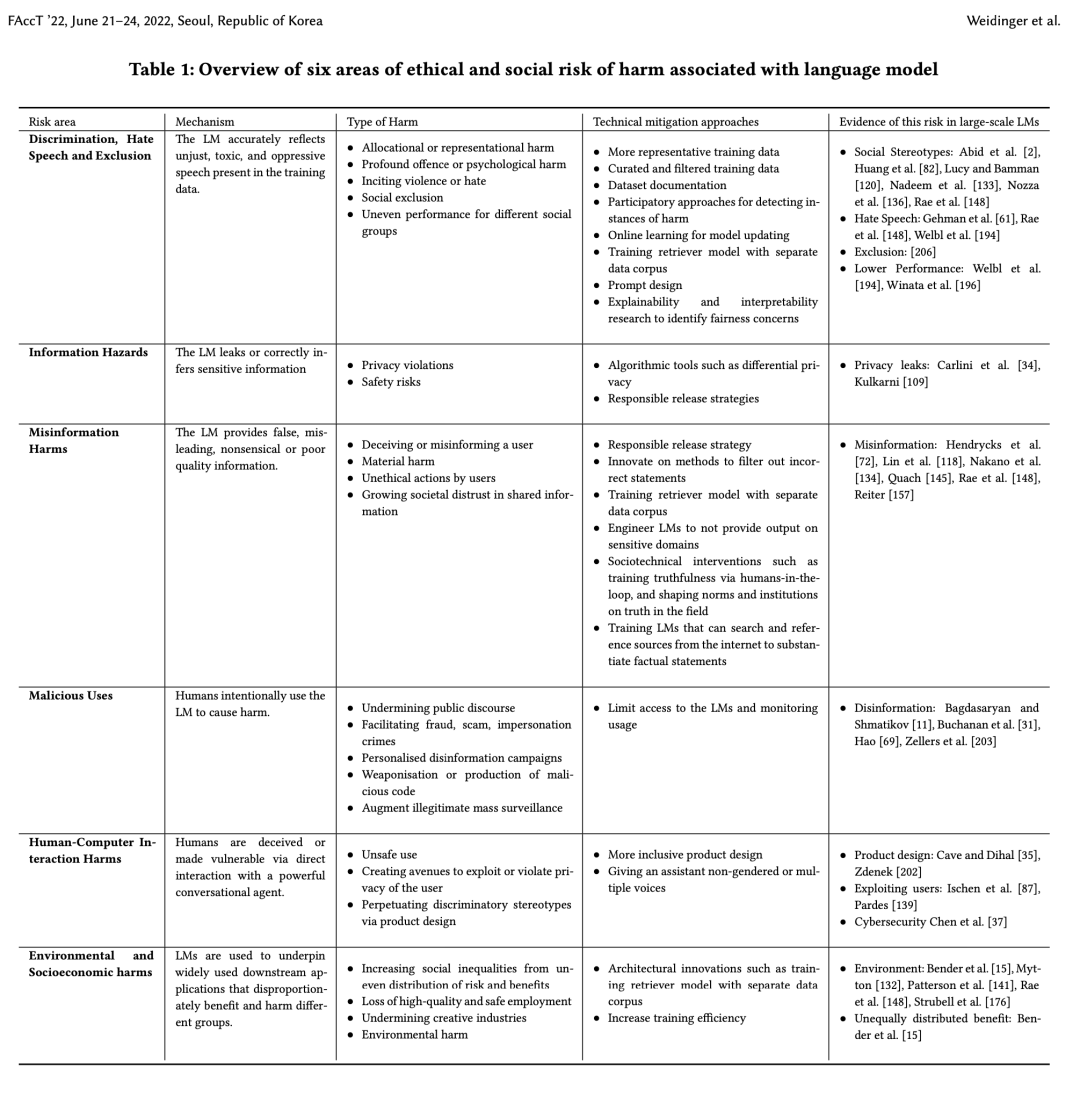 论文对语言模型相关的六大风险领域的概述
论文对语言模型相关的六大风险领域的概述
3. 结论&展望
DeepMind针对六大风险领域提出了21种风险类型,在下篇中我们将详细讨论不同风险的产生原因,并进一步指出潜在风险的缓解方案。
本文通过构建大型语言模型风险分类法为我们打造了语言模型的风险格局,这恰恰是未来创建可靠、高效大型语言模型的第一步!面对大模型快速发展带来的产业、伦理、环保等各方面问题,AI社区不仅要提前预知大模型可能带来的道德和社会风险,更要深入理解并发现这些风险和潜在危害的根源,保证大模型健康、可持续发展。
参考资料:
[1] Weidinger L, Uesato J, Rauh M, et al. Taxonomy of risks posed by language models[C]//2022 ACM Conference on Fairness, Accountability, and Transparency. 2022: 214-229.
[2] 智源出品 | 超大规模智能模型产业发展报告: https://baai.org/l/MdRePort
[3] Patterson D, Gonzalez J, Le Q, et al. Carbon emissions and large neural network training[J]. arXiv preprint arXiv:2104.10350, 2021.
[4] Tamkin A, Brundage M, Clark J, et al. Understanding the capabilities, limitations, and societal impact of large language models[J]. arXiv preprint arXiv:2102.02503, 2021.
[5] Bommasani R, Hudson D A, Adeli E, et al. On the opportunities and risks of foundation models[J]. arXiv preprint arXiv:2108.07258, 2021.
[6] Bender E M, Gebru T, McMillan-Major A, et al. On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?🦜[C]//Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency. 2021: 610-623.
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢