
【论文标题】A Self-Attention Ansatz for Ab-initio Quantum Chemistry
【作者团队】Ingrid von Glehn, James S. Spencer, David Pfau
【发表时间】2022/11/24
【机 构】Deepmind
【论文链接】https://arxiv.org/pdf/2211.13672v1.pdf
本文提出了一种利用自注意力的新型神经网络结构,波函数Transformer(Psiformer),它可以作为解决多电子薛定谔方程的Ansatz。该方程是量子化学和材料科学的基本方程,可以从第一性原理来解决,不需要外部训练数据。近年来,像FermiNet和PauliNet一样的深度神经网络已经被用来显著提高这些第一原理计算的准确性,但它们缺乏类似于注意力的机制来控制电子之间的相互作用。本文展示了Psiformer可以作为这些神经网络的替代方案,在进行了预训练方面的多种优化比如提升训练时间、改进采样等后,可以极大地提高计算的准确性,特别是在较大的分子上,比以前的方法有了质的飞跃。这表明,自注意力网络可以学习电子之间复杂的量子力学关联,是在更大的系统上达到更高化学计算精度的潜在途径。
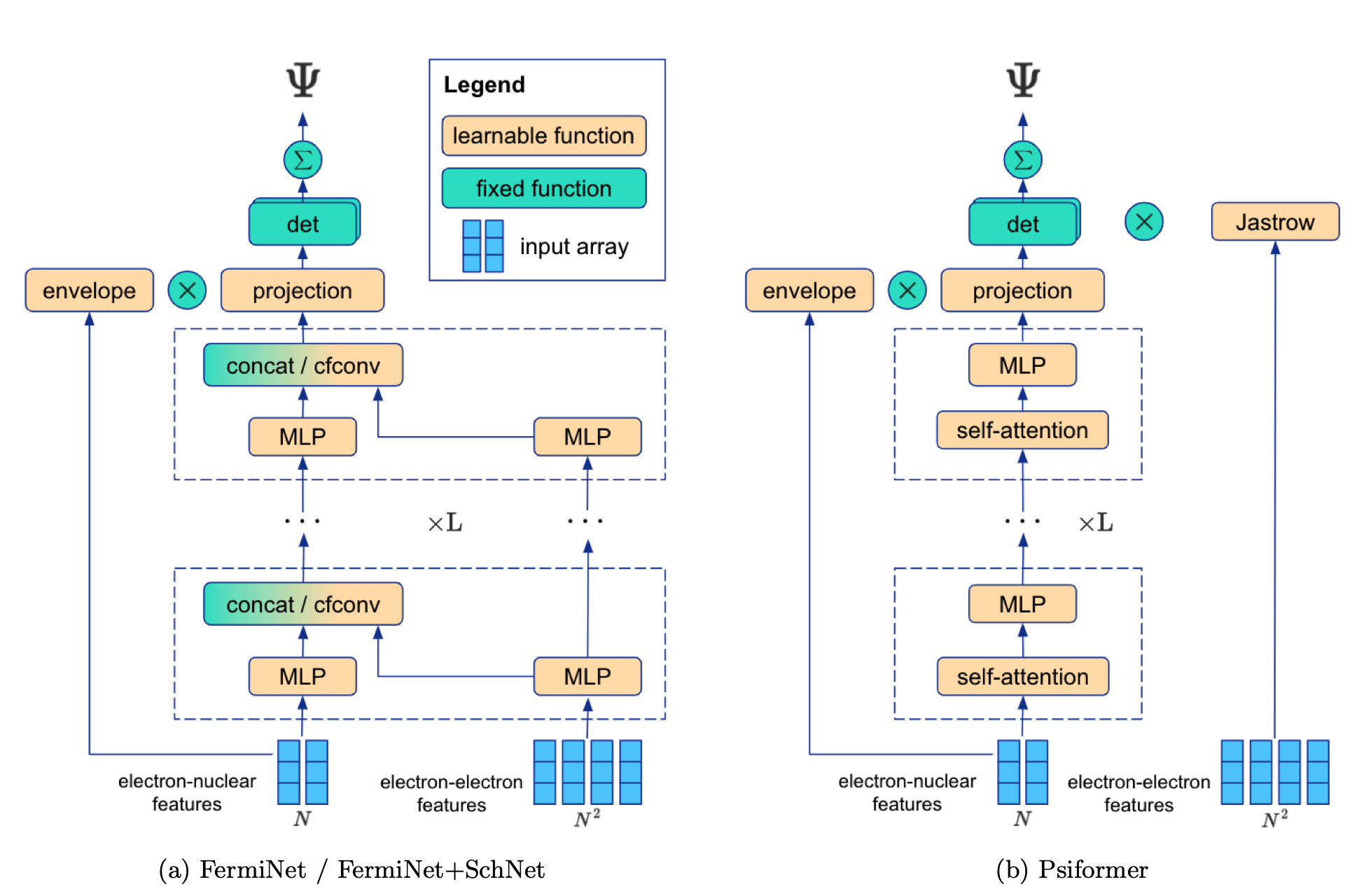
上图展示了FermiNet和FermiNet+SchNet以及本文提出的Psiformer的比较。FermiNet有两个数据流,分别作用于电子-核和电子-电子特征,通过连接或连续卷积操作合并。FermiNet+SchNet还包括一个核嵌入流和独立的自旋相关的电子-电子流。Psiformer使用单一的自注意力层流,只作用于电子-核特征,电子-电子特征只通过Jastrow因子出现。这样做的主要动机是,哈密顿中的电子-电子依赖性在波函数中产生微妙而复杂的依赖性,而自注意力是在没有固定函数形式的情况下引入这种依赖的一种方式。
模型架构方面,自注意力层将一连串的电子特征向量作为输入,类似于FermiNet的单电子流,它使用电子核差异和距离的串联,但有两个关键区别。首先,本文发现,对于原子相距特别远的系统,使用FermiNet的单电子特征会导致自注意力的Ansatz变得不稳定,因此本文对Psiformer中的输入进行了重新缩放,输入向量随着与原子核的距离呈对数增长。其次,本文将自旋σi串联到输入特征向量本身,将↑映射为1,↓映射为-1。虽然这个自旋项在训练过程中保持固定,但它打破了自旋向上和自旋向下的电子之间的对称性。这与FermiNet和PauliNet有明显的不同,在FermiNet中,自旋向上和自旋向下的电子之间的差异是建立在结构上的。
输入特征通过线性映射被投影到与注意力输入相同的维度,然后被传递到多头自注意力层中,紧接线性-非线性层伴随残差连接,最后线性投影到一个NN_det维的空间。Psiformer只对电子-电子尖峰使用传统的Jastrow因子.
模型训练方面,和FermiNet实现一样,本文使用的超参数和Metropolis-Hastings MCMC算法与原FermiNet论文类似,但使用LAMB优化器作为预训练优化器,预训练的时间更长,本文从目标波函数中生成预训练的样本,本文在参数更新之间采取更多的MCMC步骤,本文建议更新电子子集而不是同时更新所有的电子,本文稍微改变梯度计算,使其对异常值更加稳健。此外,在预训练期间,本文只从高频轨道中提取样本,而不是神经网络波函数。对小分子使用了较少的预训练迭代次数(20,000次),而对第三排原子和大分子则使用了100,000次迭代。
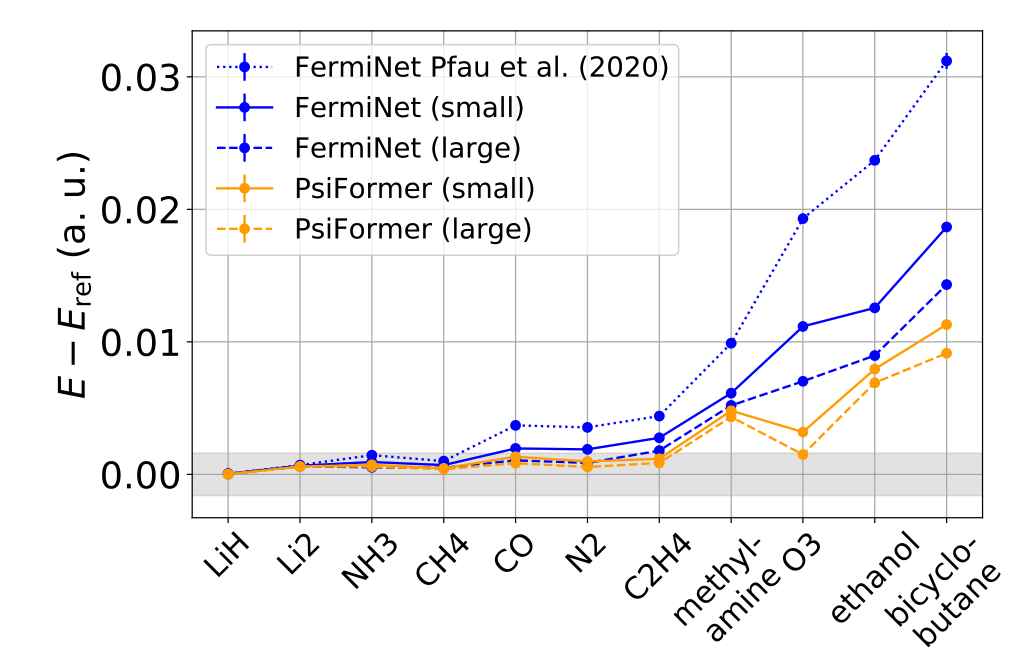
上图展示了在小分子上的FermiNet和Psiformer精度。灰色区域表示相对于参考能量的化学精度(1 kcal/mol或1.6 mHa)。虽然增加FermiNet的尺寸可以在一定程度上提高准确度,但小的Psiformer比大的费米网更准确,而大的Psiformer是所有系统中最准确的。这对所有被调查的系统都是如此,在臭氧和双环丁烷上,Psiformer的改进尤为显著,在臭氧上,大型Psiformer与CCSD(T)/CBS的误差在1千卡/摩尔以内,而即使是最大的FermiNet的误差也比这大4倍多。在所有的分子上,大型Psiformer捕获了相对于参考能量的99%以上的相关能量。
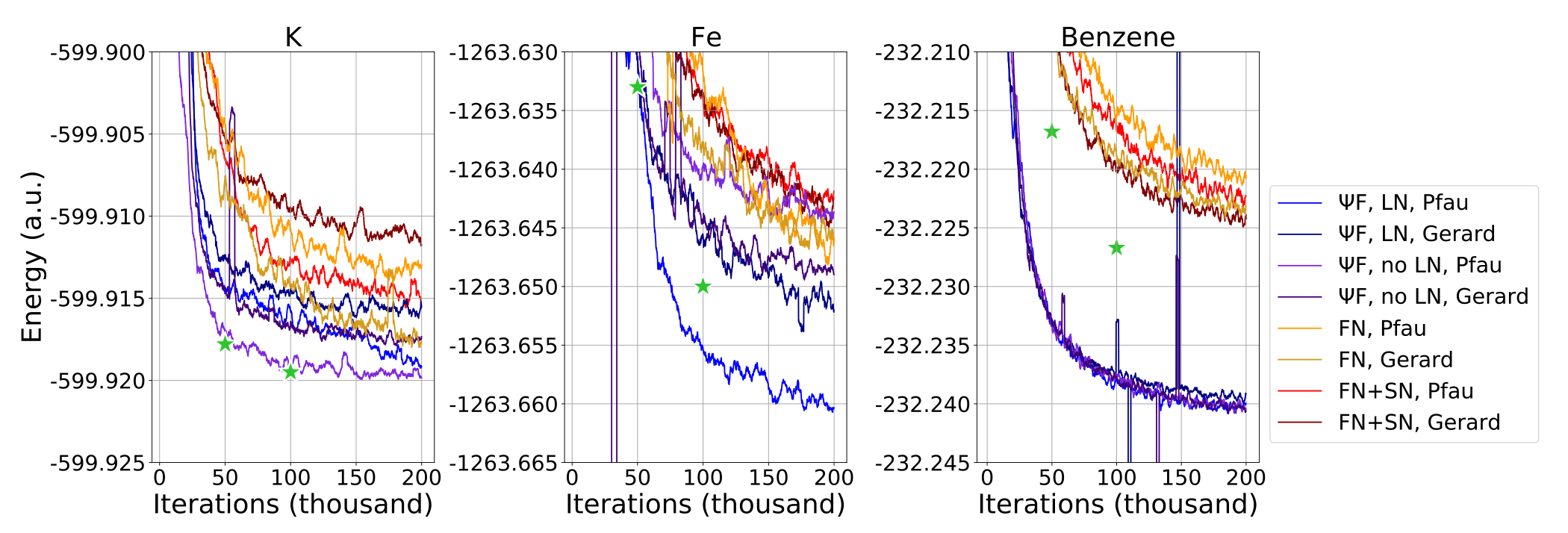
上图展示了FermiNet+SchNet的结果,首先,用于FermiNet的训练的变化似乎足以缩小与已发表的FermiNet+SchNet在重原子上的结果的差距。例如,消融研究表明,修改超参数加上类似SchNet的卷积,在105次迭代时,钾原子的精度提高了38.9mHa,但在本文的实验中,使用默认超参数的FermiNet与公布的结果相差不大。在苯上,类似SchNet的卷积和修改后的超参数都将最终能量提高了几mHa,尽管仍与公布的再结果有一点差距。最重要的是,Psiformer显然或者与已发表的最好的FermiNet+SchNet结果相当,如在钾上的结果,或者以很大的幅度更好,如在苯上。
创新点
自注意力网络能够比同类方法更有效地学习电子的量子力学特性。自注意力网络的优势在大型系统上似乎变得最为明显,这表明这些模型应该是未来扩展到更大系统的工作重点。这为以更高的精度研究最具挑战性的分子和材料提供了一条有希望的道路。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢