
模式匹配是自然语言处理信息抽取领域十分重要的一个基础性工作,也是我们常说的策略方法(与深度学习模型相对)。
如何使用规则的方式完成相关数据处理、信息抽取、分类等任务,是作为一个自然语言处理工程师必备的一项素质。
本文主要围绕NLP中的模式匹配落地场景及高效开源工具总结与分析这一主题,对模式匹配在自然语言处理落地中的使用场景以及开源的模式匹配工具进行介绍,供大家参考。
一、模式匹配概述
模式匹配,从概念上来说,指给定某种模式,检查给定的序列或字符串中是否有符合某种模式的片段。例如,给定句子“苹果是一种水果”,如果我们将 “是一种 ” 作为一种模式,则可以得到苹果和水果的匹配结果。而与模式匹配关系最为密切的,是正则表达式。
实际上,python语言中内置的re正则表达式已经可以完成此类的任务,但效率不高,有相关实践经验表明,随着需要处理的字符越来越多,正则表达式的处理速度几乎都是线性增加的,正则表达式在一个10k的词库中查找15k个关键词的时间差不多是0.165秒。
因此,如何解决在大规模文本的运行效率,目前先后出现了以AC自动机,时间复杂度为O(n)为典型代表的高性能模式匹配工具,本文就实际工作中所遇到的一些工具进行总结。
二、模式匹配在自然语言处理落地中的使用场景
1、知识图谱应用中的实体发现与链接
在基于知识图谱的应用,例如KBQA、实体识别系统中,第一步往往就是实体的提取和链接,所以在一个query中就要求提取出KB中包含的实体的名称,但是由于实体的数量动辄百万而普通的匹配方式由于每次匹配失败都需要回溯其耗时较久,而AC自动机的时间复杂度理想状态下为O(n),n为query串的长度。
一般采取的技术路线就是使用AC自动机提取出包含知识库中实体的所有子串(或者最长子串)+ NER实体识别的方式对query中的实体进行提取,再综合两个结果召回评分最高的Topn实体进行后续的链接操作。
2、搜广推中的敏感词过滤与召回
做敏感词过滤的时候要用到字符串匹配,从一个文件中读入需要匹配的敏感词,和一段文本去匹配,用string的find方法是不太合适。当你需要从一大堆数据中找寻自己想要的数据时可以使用AC自动机算法使用AC自动机算法。
另外,在广推场景中,对query进行匹配,尽可能多的找出里面的可能的关键词,然后提高召回。如果是最简单的想法可能就是一个for循环遍历词表,判断在不在文本里面。词表小的时候其实还好,但是如果词表大了,那么这个效率是很低的。
又如,在信息检索中的关键字搜索与替代场景中,另一个常用的用例是当我们有一个同义词的语料库(不同的拼写表示的是同一个单词),比如 corpus = {javascript: [‘javascript’, ‘javascripting’, ‘java script’], …} ,在软件工程师的简历中需要使用标准化的词,就需要用一个标准化的词来替换不同简历中的同义词。
三、AC自动机原理与应用流程
Aho-Corasick automaton,著名的多模匹配算法,简称AC算法,于1975年产生于贝尔实验室,主要用于多模式串匹配问题,即给几个关键词(模式串),再给一篇文章,判断关键词是否在文章中出现,或出现的次数。
Aho-Corasick算法,通过将模式串预处理为确定有限状态自动机,扫描文本一遍就能结束。其复杂度为O(n),即与模式串的数量和长度无关。其实现思想在于:按照文本字符顺序,接受字符,并发生状态转移。这些状态缓存了“按照字符转移成功(但不是模式串的结尾)”、“按照字符转移成功(是模式串的结尾)”、“按照字符转移失败”三种情况下的跳转与输出情况,因而降低了复杂度。
AC自动机执行包括三个过程,即插入模式串构建Trie树、设置失败节点、对目标串进行匹配。
1、Trie字典树
Trie是一个字符串索引的词典,检索相关项时时间和字符串长度成正比。在自然语言处理中,字符串集合常用字典树存储,这是一种字符串上的树形数据结构。字典树中每条边都对应一个字,从根节点往下的路径构成一个个字符串。
字典树并不直接在节点上存储字符串,而是将词语视作根节点到某节点之间的一条路径,并在终点节点上做个标记(表明到该节点就结束了)。要查询一个单词,指需要顺着这条路径从根节点往下走。如果能走到标记的节点,则说明该字符串在集合中,否则说明不在。
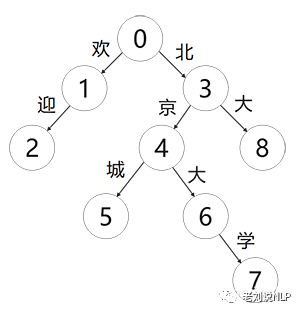
每条路径都是一个词汇,且没有子节点就可以判定该条路径结尾了,例如:欢迎、北大、北京城、北京大学的路径分别为:0-1-2、0-3-8、0-3-4-5、0-3-4-6-7
2、AC自动机的实现
在多模式环境中,AC自动是使用前缀树来存放所有模式串的前缀,然后通过失配指针来处理失配的情况。分为三个步骤:构建前缀树(生成goto表),添加失配指针(生成fail表),模式匹配(构造output表)。
1)构造前缀树
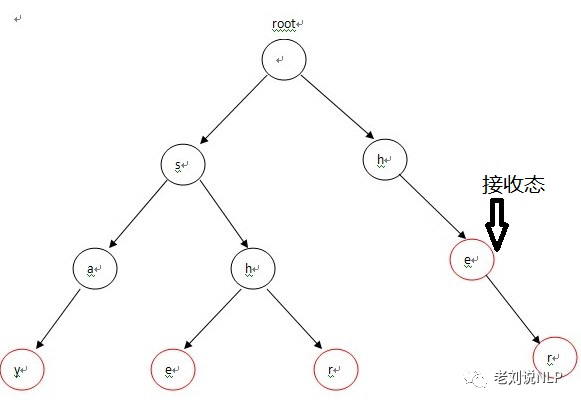
对于多模式集合{“say”,“she”,“shr”,“he”,“her”},对应的Trie树如下,其中红色标记的圈是表示为接收态:
2)添加失配指针
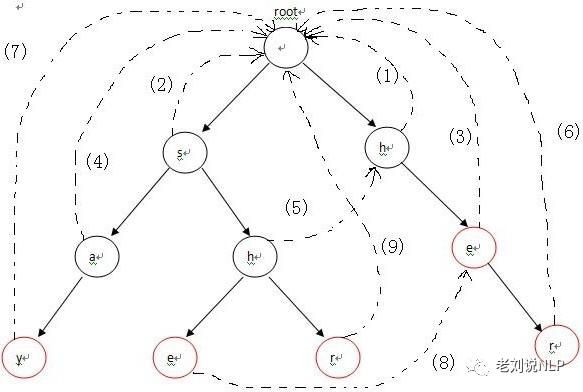
构造失败指针的过程如下:设这个节点上的字母为C,沿着他父亲的失败指针走,直到走到一个节点,他的儿子中也有字母为C的节点。然后把当前节点的失败指针指向那个字母也为C的儿子。
如果一直走到了root都没找到,那就把失败指针指向root。使用广度优先搜索BFS,层次遍历节点来处理每一个节点的失败路径。
3)模式匹配
模式匹配环节,从root节点开始,每次根据读入的字符沿着自动机向下移动。当读入的字符,在分支中不存在时,递归走失败路径。如果走失败路径走到了root节点,则跳过该字符,处理下一个字符。
因为AC自动机是沿着输入文本的最长后缀移动的,所以在读取完所有输入文本后,最后递归走失败路径,直到到达根节点,这样可以检测出所有的模式。
四、当前开源高效的模式匹配工具
当前,已经陆续开源出了一些优秀的模式匹配工具,例如python内置的re模块、经过优化的regex模块、基于AC自动机的pyahocorasick、Acora、esmre等。
1、re
re模块是Python的一个内置模块,主要定义了9个常量、12个函数、1个异常, Python 自1.5版本起增加了re模块,提供了Perl风格的正则表达式模式。
re模块提供了match、search、findall、sub、split等借口,对应实现匹配、搜索、替换以及分割功能。
其中:
-
匹配功能。 Python没有返回true和false的方法,但可以通过对match或者search方法的返回值是否是None来判断
-
搜索功能。 如果只搜索一次可以使用search或者match方法返回的匹配对象得到,对于搜索多次可以使用finditer方法返回的可迭代对象来迭代访问
-
替换功能。 可以使用正则表达式对象的sub或者subn方法来实现,也可以通过re模块方法sub或者subn来实现,区别在于模块的sub方法的替换文本可以使用一个函数来生成
-
分割功能。 可以使用正则表达式对象的split方法,需要注意如果正则表达式对象有分组的话,分组捕获的内容也会放到返回的列表中。
2、regex
regex是Matthew Barnett在2009年写了一个更强大正则表达式引擎,与有4270行C语言代码的re模块相比,regex模块有24513行C语言代码。
regex提供了模糊匹配(fuzzy matching)功能,能针对字符进行模糊匹配,提供了模糊插入、模糊删除、模糊替换等3种模糊匹配。例如:
regex.findall('(?:hello){s<=2}', 'hallo'),
其中最多容许有两个字符的错误,可以匹配出hallo。
3、Pyahocorasick
pyahocorasick是个python模块,由两种数据结构实现:trie和Aho-Corasick自动机,根据一组关键词进行匹配,返回关键词出现的位置,底层用C实现,python包装。
使用例子:
import ahocorasick
def make_AC(AC, word_set):
for word in word_set:
print(word)
AC.add_word(word,word)
return AC
def demo():
key_list = ["苹果", "香蕉", "梨", "橙子", "柚子", "火龙果", "柿子", "猕猴挑"]
AC_KEY = ahocorasick.Automaton()
AC_KEY = make_AC(AC_KEY, set(key_list))
AC_KEY.make_automaton()
test_str_list = ["我最喜欢吃的水果有:苹果、梨和香蕉", "我也喜欢吃香蕉,但是我不喜欢吃梨"]
for content in test_str_list:
name_list = set()
for item in AC_KEY.iter(content):#将AC_KEY中的每一项与content内容作对比,若匹配则返回
name_list.add(item[1])
name_list = list(name_list)
if len(name_list) > 0:
print(content, "命中:", "\t".join(name_list))
output:
"我最喜欢吃的水果,苹果、梨和香蕉",命中:["苹果","香蕉","梨"]
"我也喜欢吃香蕉,但是我不喜欢吃梨",命中:[香蕉","梨"]使用经验表明,pyahocorasick存在两个问题:
-
一个是关键词匹配不完整,如果目标关键词里面有宝马和马,那么用python的ahocorasick库只会得到宝马,而不会得到马,问题是处在马这个字节是在宝马的链条里面的。
-
另一个是内存泄漏问题,这个问题在esmre中得到了解决。
4、Acora
acora是python的“fgrep”,是一个基于Aho-Corasick以及NFA-to-DFA自动机的方式快速的多关键字文本搜索引擎。
acora具备一些特性,包括在输入端适用于Unicode字符串和字节字符串。在对于大多数输入时,大约是python正则表达式引擎的2-3倍,并且能够查找重叠匹配项,即所有关键字的所有匹配项,还支持不区分大小写的搜索(~10倍于’re’,python内置的正则表达模块)。
from acora import AcoraBuilder
>>> builder = AcoraBuilder('ab', 'bc', 'de')
>>> builder.add('a', 'b')
>>> ac = builder.build()
>>> ac.findall('abc')
[('a', 0), ('ab', 0), ('b', 1), ('bc', 1)]
>>> ac.findall('abde')
[('a', 0), ('ab', 0), ('b', 1), ('de', 2)]5、esmre
esmre同样使用的AhoCorasick自动机的方式,做了一些细微的修改,也是用C实现,python包装。与pyhrocorasick相比,esmre库不存在内存异常泄露等问题。
import esm
index = esm.Index()
index.enter('保罗')
index.enter('小卡')
index.enter('贝弗利')
index.fix()
index.query("""NBA季后赛西部决赛,快船与太阳移师洛杉矶展开了他们系列赛第三场较量,上一场太阳凭借艾顿的空接绝杀惊险胜出,此役保罗火线复出,而小卡则继续缺阵。首节开局两队势均力敌,但保罗和布克单节一分未得的拉胯表现让太阳陷入困境,快船趁机在节末打出一波9-2稍稍拉开比分,次节快船替补球员得分乏术,太阳抓住机会打出14-4的攻击波反超比分,布克和保罗先后找回手感,纵使乔治重新登场后状态火热,太阳也依旧带着2分的优势结束上半场。下半场太阳的进攻突然断电,快船则在曼恩和乔治的引领下打出一波21-3的攻击狂潮彻底掌控场上局势,末节快船在领先到18分后略有放松,太阳一波12-0看到了翻盘的希望,关键时刻雷吉和贝弗利接管比赛,正是他们出色的发挥为球队锁定胜局,最终快船主场106-92击败太阳,将总比分扳成1-2。""")
[((162, 168), '保罗'), ((186, 192), '小卡'), ((246, 252), '保罗'), ((478, 484), '保罗'), ((846, 855), '贝弗利')]6、pampy
Pampy是一个只有150行的Python模式匹配类库,可支持单个字符匹配、匹配开头和结尾、匹配字典的key等功能。
Pampy匹配模式Pattern,可以是Python的任何类型,类或Python值,operator _和内置的类型(如int或str)提取传递给函数的变量。类型和类通过instanceof(value,pattern)来匹配,可迭代模式以递归方式匹配其所有元素。
Pampy匹配支持正则表达式,可以直接将已编译的正则表达式作为模式进行传递,通过Pampy支持多模式匹配,多个模式按照顺序进行匹配。
使用实例:
import re
from pampy import match, HEAD, TAIL, _
def what_is(pet):
return match(pet,
re.compile('(\\w+),(\\w)\\w+鳕鱼$'), lambda mygod, you: you + "像鳕鱼",
)
print(what_is('我的天,你长得真像鳕鱼')) # => '你像鳕鱼' 7、flashtext
Flashtext是一个高效的字符搜索和替换算法,基于Trie字典数据结构和AhoCorasick 的算法时间复杂度不依赖于搜索或替换的字符的数量。与AhoCorasick算法不同,Flashtext算法不匹配子字符串,只匹配最长字符(完整的单词),首先匹配最长字符串。
比如,输入一个单词 {Apple},算法就不会匹配 “I like Pineapple” 中的 apple,输入单词集合 {Machine, Learning,Machine Learning}和文档“I like Machine Learning”,算法只会去匹配 “Machine Learning” 。
实例:
1)关键字搜索
>>> from flashtext import KeywordProcessor
>>> keyword_processor = KeywordProcessor()
>>> # keyword_processor.add_keyword(<unclean name>, <standardised name>)
>>> keyword_processor.add_keyword('Big Apple', 'New York')
>>> keyword_processor.add_keyword('Bay Area')
>>> keywords_found = keyword_processor.extract_keywords('I love Big Apple and Bay Area.')
>>> keywords_found
>>> ['New York', 'Bay Area']
2)关键字替换
>>> keyword_processor.add_keyword('New Delhi', 'NCR region')
>>> new_sentence = keyword_processor.replace_keywords('I love Big Apple and new delhi.')
>>> new_sentence
>>> 'I love New York and NCR region.'五、总结
本文围绕着NLP中的模式匹配落地场景及高效开源工具调研与分析,对模式匹配在自然语言处理落地中的使用场景、AC自动机原理与应用流程以及当前开源模式匹配工具等几个方面进行了介绍。
以正则表达式为核心的模式匹配能力,是作为一位算法工程师的重要基础性的能力,也是作为补充深度学习方法解决业务落地问题的重要手段之一。一味的关注深度学习模型,而轻视基础数据处理、规则策略的能力,是本末倒置的。
参考文献
1、https://zhuanlan.zhihu.com/p/158767004
2、http://xiaorui.cc/archives/1649
3、https://blog.51cto.com/daoxin/1585119
4、http://www.cppcns.com/jiaoben/python/387695.html
5、https://zhuanlan.zhihu.com/p/80325757
6、https://blog.csdn.net/xc_zhou/article/details/110495762
7、https://www.jianshu.com/p/5295c5988b7f
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢