
转自爱可可爱生活
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 GR - 图形学
摘要:面向分类数据的连续扩散模型、基于Transformer的长程时序预测、基于扩散模型的顺序决策、基于SGD的高性能视觉模型微调、多样化多任务数据上可扩展可泛化的离线Q-Learning、基于线性模型的上下文学习算法调查、多任务学习视角看解耦和稀疏性的协同效应、用自毁模型提高基础模型不良双重使用成本、对比学习归纳偏差理论研究
1、[CL] Continuous diffusion for categorical data
S Dieleman, L Sartran, A Roshannai, N Savinov...
[DeepMind & University of Southern California & INRIA & Google Research]
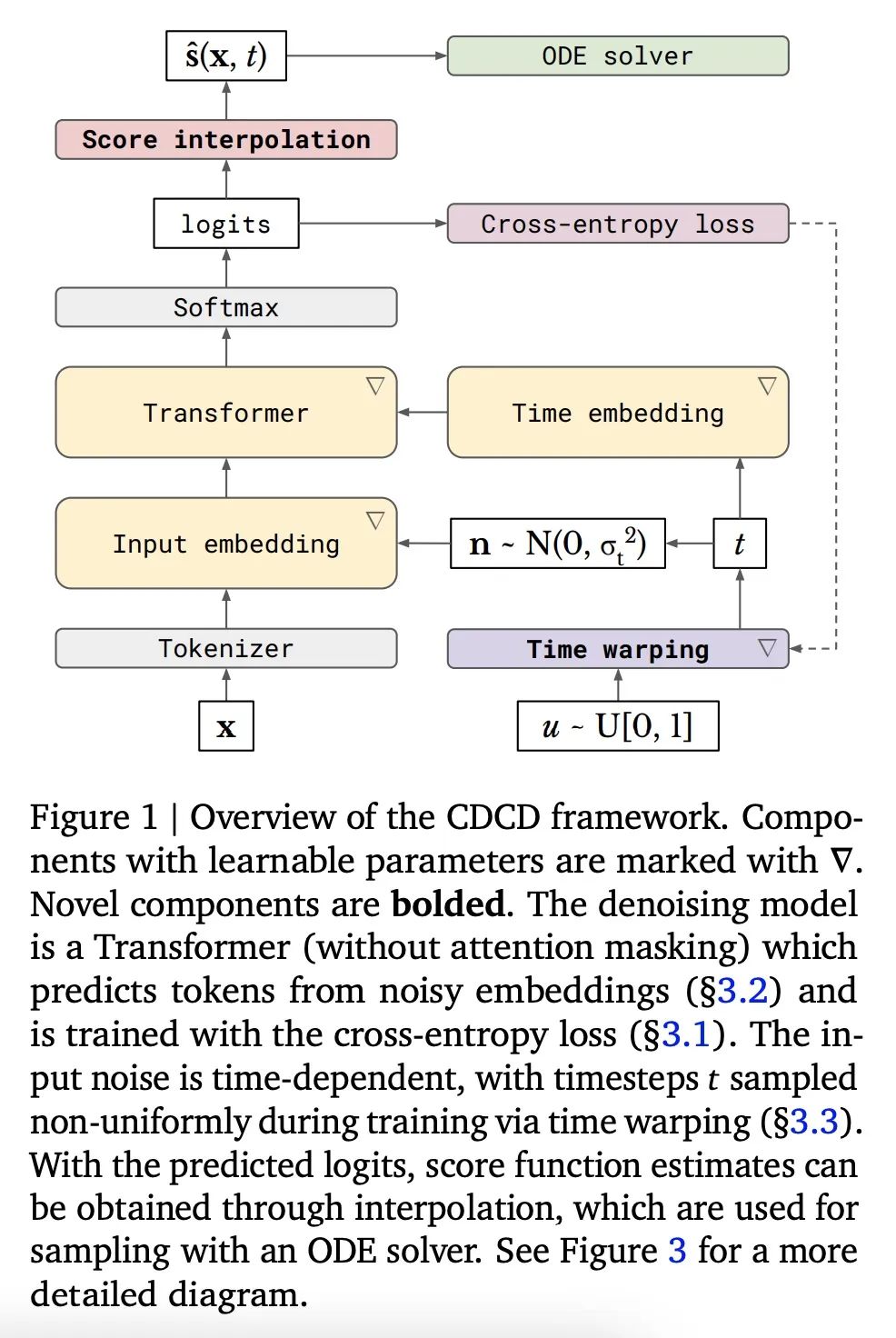
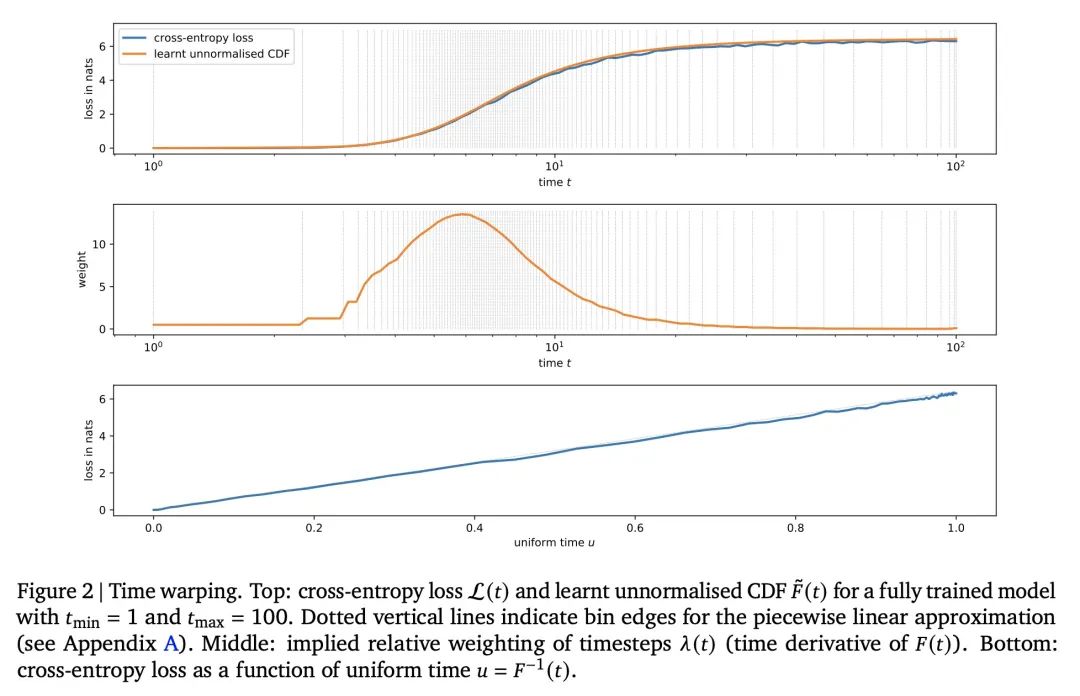
面向分类数据的连续扩散模型。扩散模型已迅速成为通过迭代细化对感知信号(如图像和声音)进行生成式建模的首选范式,其成功取决于底层物理现象是连续的这一事实。对于语言等固有的离散和分类数据,已经提出了各种受扩散启发的替代方案。然而,扩散模型的连续性质有许多好处,本文力图保留这种特性,提出了CDCD,一种用扩散模型对分类数据进行建模的框架,该模型在时间和输入空间上都是连续的。在几个语言建模任务中证明了它的功效。然而,扩散模型的连续性质带来了许多好处,在这项工作中,我们努力保留它。我们提出了CDCD,一个用扩散模型对分类数据进行建模的框架,该模型在时间和输入空间上都是连续的。我们在几个语言建模任务中证明了它的功效。
Diffusion models have quickly become the go-to paradigm for generative modelling of perceptual signals (such as images and sound) through iterative refinement. Their success hinges on the fact that the underlying physical phenomena are continuous. For inherently discrete and categorical data such as language, various diffusion-inspired alternatives have been proposed. However, the continuous nature of diffusion models conveys many benefits, and in this work we endeavour to preserve it. We propose CDCD, a framework for modelling categorical data with diffusion models that are continuous both in time and input space. We demonstrate its efficacy on several language modelling tasks.
https://arxiv.org/abs/2211.15089


2、[LG] A Time Series is Worth 64 Words: Long-term Forecasting with Transformers
Y Nie, N H. Nguyen, P Sinthong, J Kalagnanam
[Princeton University & IBM Research]
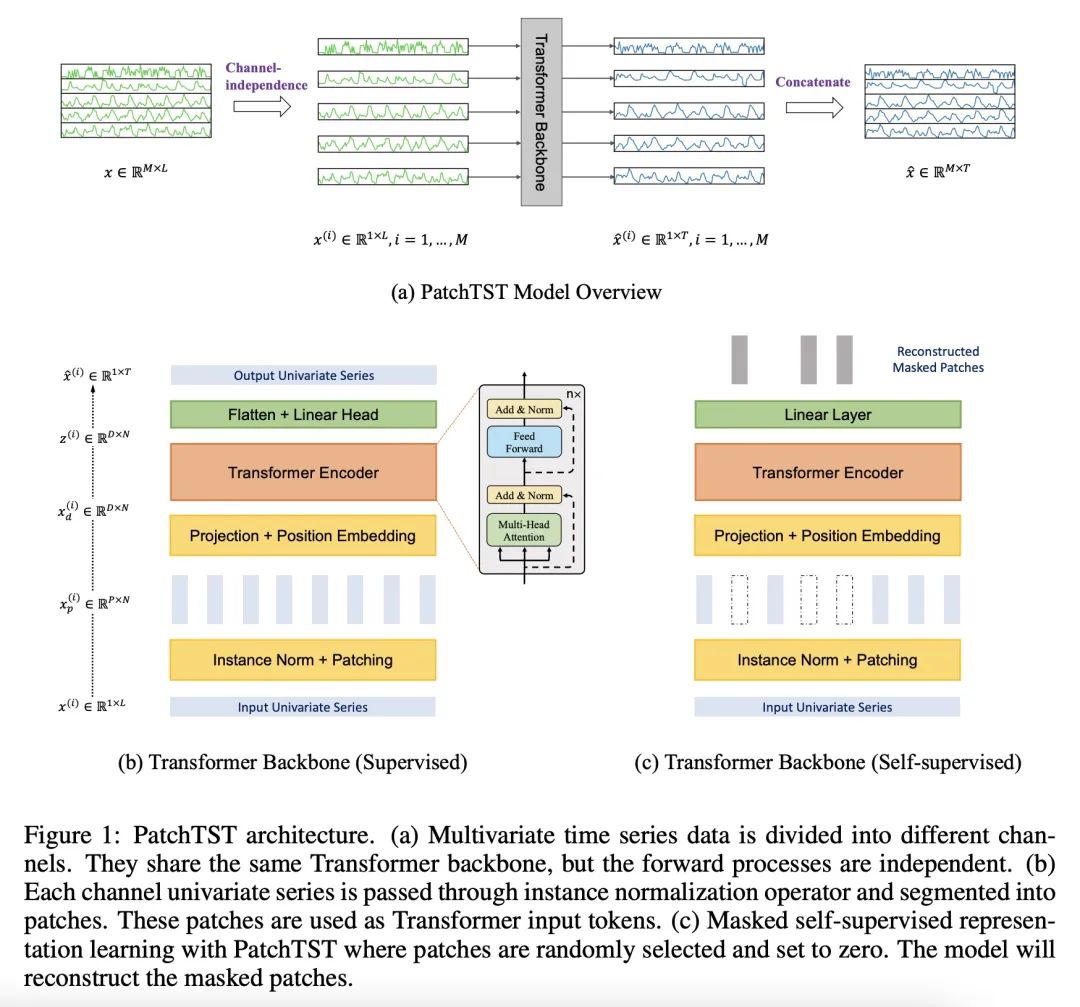
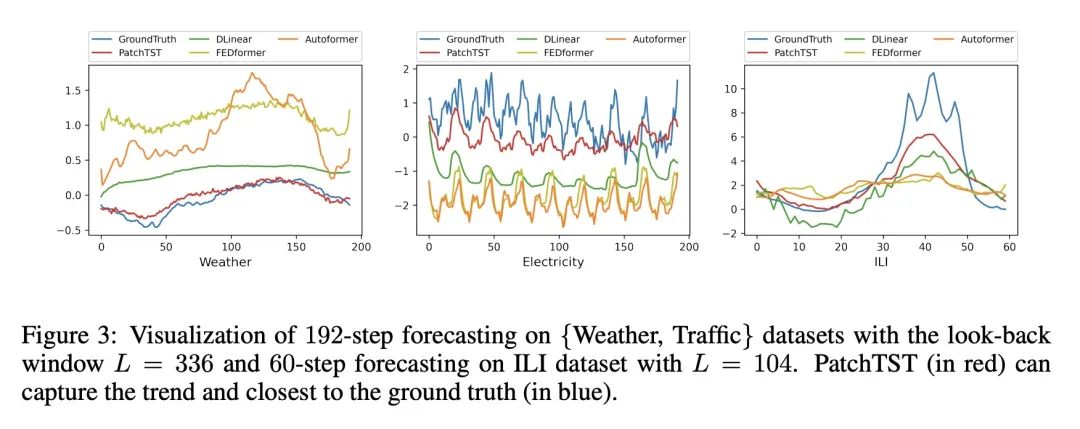
基于Transformer的长程时序预测。本文提出一种高效的基于Transformer的模型设计,用于多变量时间序列的预测和自监督表示学习,其基于两个关键部分:(i) 将时间序列分割成子序列级的块,作为Transformer的输入Token;(ii) 通道独立,每个通道包含一个单一的单变量时间序列,在所有序列中共享相同的嵌入和Transformer权重。块设计自然有三方面的好处:局部语义信息被保留在嵌入中;在相同的回看窗口下,注意力图的计算和内存使用成四倍地减少;模型可以参与更长的历史。与基于最先进Transformer的模型相比,所提出的通道无关块时间序列Transformer(PatchTST)可以显著提高长程预测精度。将该模型应用于自监督预训练任务,获得了出色的微调性能,在大型数据集上的表现优于监督训练。将一个数据集上的掩码预训练表示迁移到其他数据集上也能产生SOTA的预测精度。
We propose an efficient design of Transformer-based models for multivariate time series forecasting and self-supervised representation learning. It is based on two key components: (i) segmentation of time series into subseries-level patches which are served as input tokens to Transformer; (ii) channel-independence where each channel contains a single univariate time series that shares the same embedding and Transformer weights across all the series. Patching design naturally has three-fold benefit: local semantic information is retained in the embedding; computation and memory usage of the attention maps are quadratically reduced given the same look-back window; and the model can attend longer history. Our channel-independent patch time series Transformer (PatchTST) can improve the long-term forecasting accuracy significantly when compared with that of SOTA Transformer-based models. We also apply our model to self-supervised pre-training tasks and attain excellent fine-tuning performance, which outperforms supervised training on large datasets. Transferring of masked pre-trained representation on one dataset to others also produces SOTA forecasting accuracy. Code is available at: this https URL.
https://arxiv.org/abs/2211.14730


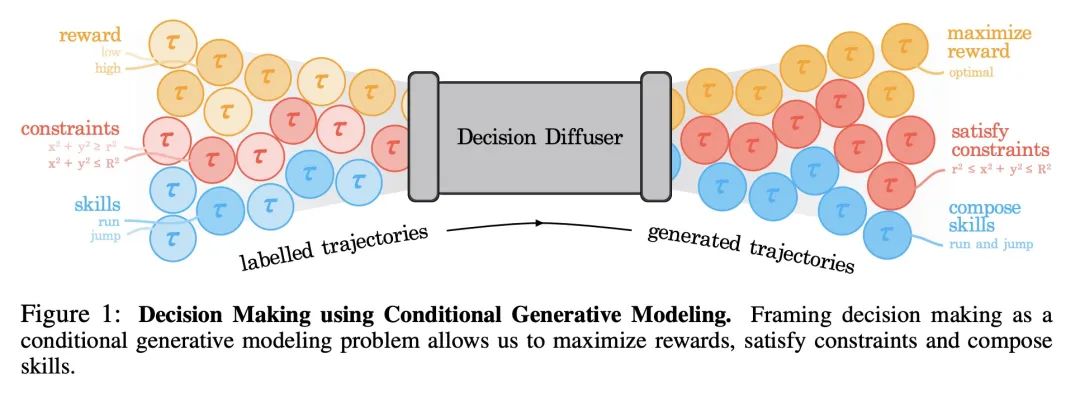
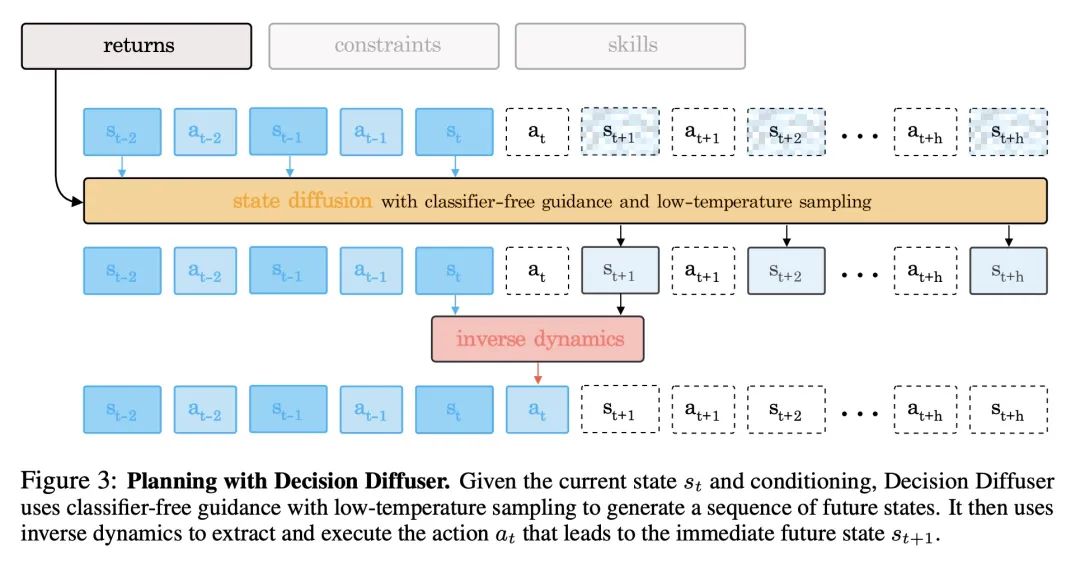
3、[LG] Is Conditional Generative Modeling all you need for Decision-Making?
A Ajay, Y Du, A Gupta, J Tenenbaum, T Jaakkola, P Agrawal
[Improbable AI Lab & MIT]
基于扩散模型的顺序决策。最近在条件生成式建模方面的改进,使得有可能仅从语言描述中生成高质量的图像。本文研究这些方法是否能直接解决顺序决策问题,不是从强化学习(RL)的角度来看待决策,而是从条件生成式建模的角度来看待决策。令人惊讶的是,这种表述得到的策略在标准基准上可以超过现有的离线强化学习方法。通过将策略建模为回报条件扩散模型,本文说明了如何规避动态规划的需要,从而消除了传统离线强化学习的各种复杂性。通过考虑另外两个条件变量:约束和技能,进一步证明了将策略建模为条件扩散模型的优势。在训练过程中对单一约束条件或技能的调节导致了在测试时间的行为,这些行为可以同时满足几个约束条件或展示一个技能的组合。本文结果说明,条件生成模型是一种强大的决策工具。
Recent improvements in conditional generative modeling have made it possible to generate high-quality images from language descriptions alone. We investigate whether these methods can directly address the problem of sequential decision-making. We view decision-making not through the lens of reinforcement learning (RL), but rather through conditional generative modeling. To our surprise, we find that our formulation leads to policies that can outperform existing offline RL approaches across standard benchmarks. By modeling a policy as a return-conditional diffusion model, we illustrate how we may circumvent the need for dynamic programming and subsequently eliminate many of the complexities that come with traditional offline RL. We further demonstrate the advantages of modeling policies as conditional diffusion models by considering two other conditioning variables: constraints and skills. Conditioning on a single constraint or skill during training leads to behaviors at test-time that can satisfy several constraints together or demonstrate a composition of skills. Our results illustrate that conditional generative modeling is a powerful tool for decision-making.
https://arxiv.org/abs/2211.15657


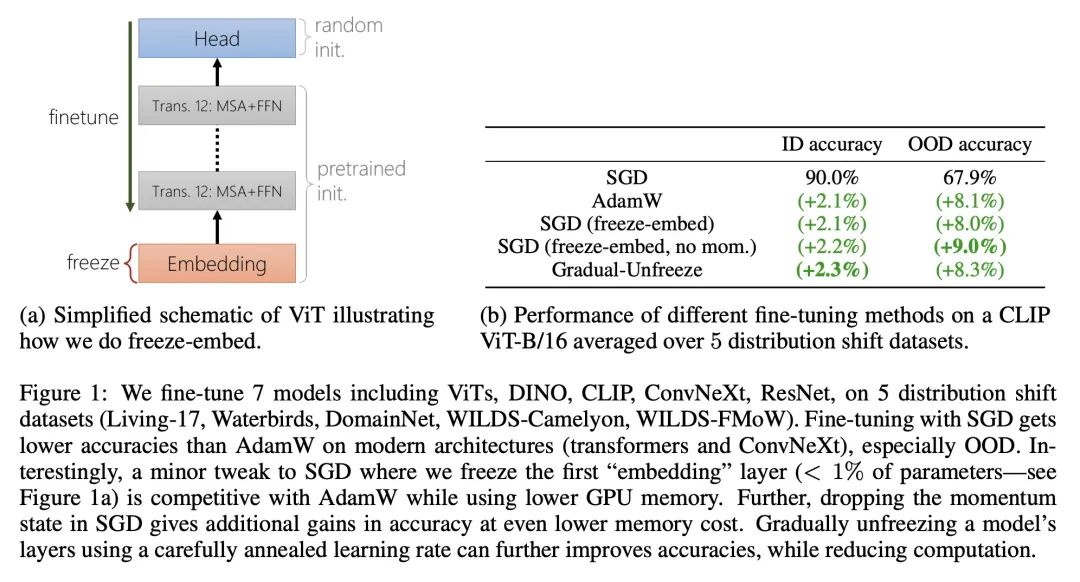
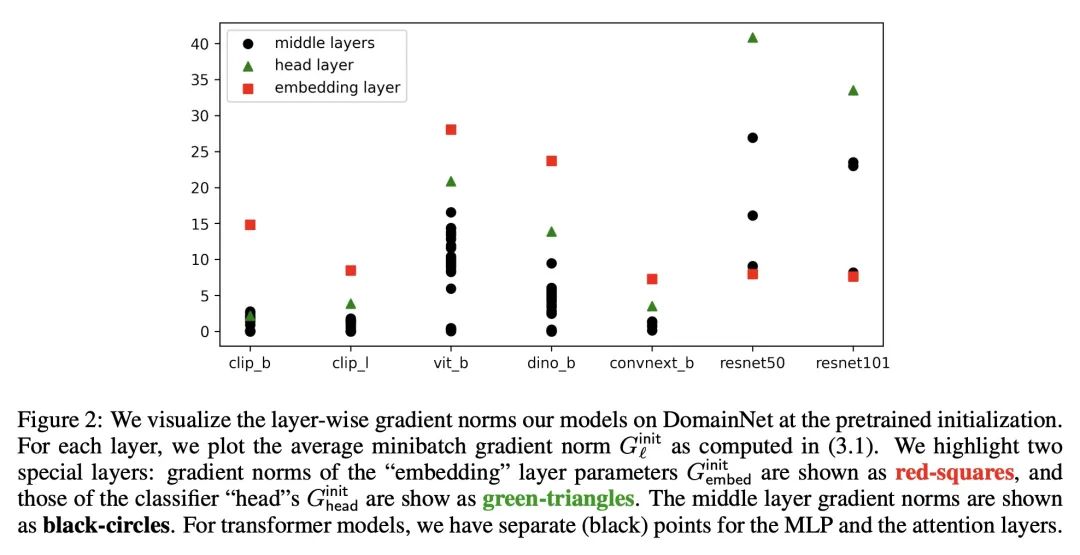
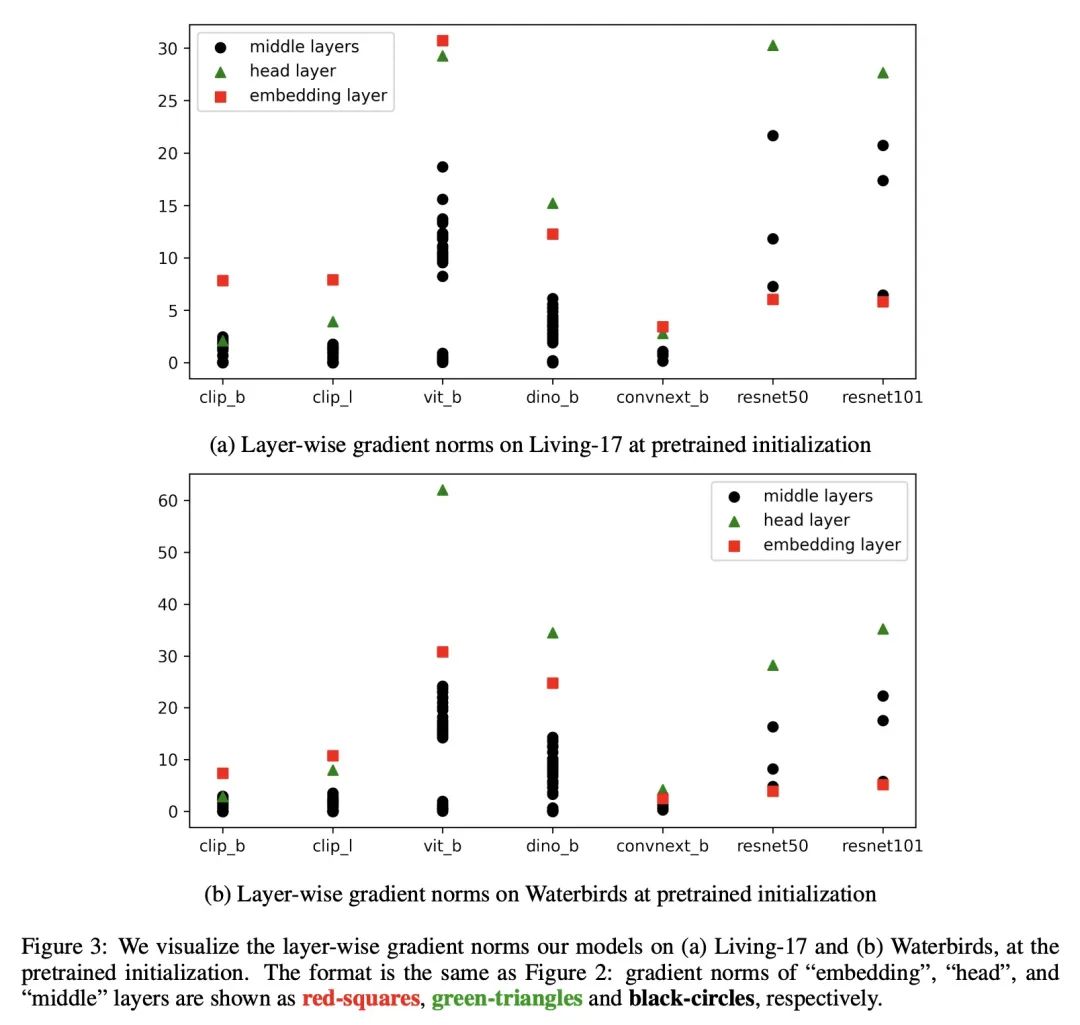
4、[CV] How to Fine-Tune Vision Models with SGD
A Kumar, R Shen, S Bubeck, S Gunasekar
[Stanford University & University of Washington & Microsoft]
基于SGD的高性能视觉模型微调。SGD(基于动量)和AdamW是计算机视觉中用于微调大型神经网络的两种最常用的优化器。当这两种方法性能相同时,SGD更受欢迎,因为其比AdamW(16字节/参数)使用内存更少(12字节/参数)。然而,在一套下游任务上,特别是那些有分布漂移的任务上,本文表明,在现代视觉Transformer和ConvNeXt模型上,用AdamW进行微调的表现大大优于SGD。当第一个"嵌入"层的微调梯度远大于模型的其他部分时,SGD和AdamW间的性能差距很大。本文的分析提出一种简单的解决方案,在不同的数据集和模型中都能发挥作用:仅冻结嵌入层(少于1/%的参数)就能使SGD的性能与AdamW相竞争,同时使用更少的内存。该见解使得在五个流行的分布漂移基准上获得了最先进的准确性:WILDS-MoW、WILDS-Camelyon、Living-17、Waterbirds和DomainNet。
SGD (with momentum) and AdamW are the two most used optimizers for fine-tuning large neural networks in computer vision. When the two methods perform the same, SGD is preferable because it uses less memory (12 bytes/parameter) than AdamW (16 bytes/parameter). However, on a suite of downstream tasks, especially those with distribution shifts, we show that fine-tuning with AdamW performs substantially better than SGD on modern Vision Transformer and ConvNeXt models. We find that large gaps in performance between SGD and AdamW occur when the fine-tuning gradients in the first "embedding" layer are much larger than in the rest of the model. Our analysis suggests an easy fix that works consistently across datasets and models: merely freezing the embedding layer (less than 1\% of the parameters) leads to SGD performing competitively with AdamW while using less memory. Our insights result in state-of-the-art accuracies on five popular distribution shift benchmarks: WILDS-FMoW, WILDS-Camelyon, Living-17, Waterbirds, and DomainNet.
https://arxiv.org/abs/2211.09359

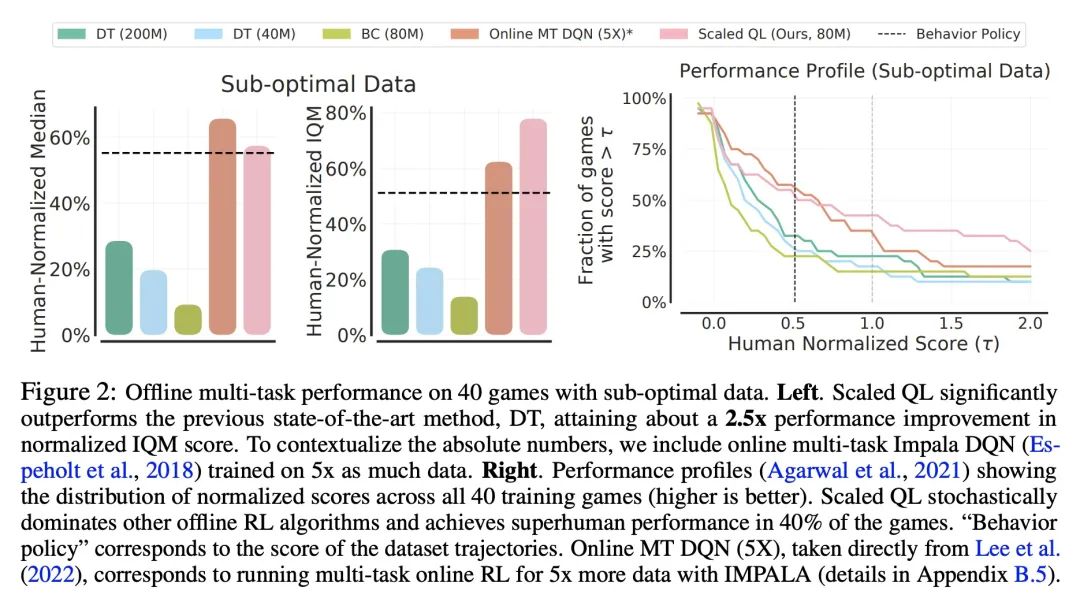
5、[LG] Offline Q-Learning on Diverse Multi-Task Data Both Scales And Generalizes
A Kumar, R Agarwal, X Geng, G Tucker, S Levine
[Google Research & UC Berkeley]
多样化多任务数据上可扩展可泛化的离线Q-Learning。离线强化学习(RL)的潜力在于,在大型异质数据集上训练的高容量模型可以导致智能体广泛地泛化,类同于视觉和NLP的类似进展。然而,最近的工作认为,离线强化学习方法在扩大模型容量方面遇到了独特的挑战。借鉴这些工作的经验,本文重新审视了之前的设计选择,发现有了适当的选择:ResNets、基于交叉熵的分布式备份和特征归一化,离线Q-learning算法表现出强大的性能,并随着模型容量的扩大而扩大。用多任务Atari作为扩展和泛化的测试平台,用高达8000万个参数网络对40个游戏进行单一策略训练,其性能接近人类,发现模型性能随着容量的增加而良好地扩展。与之前的工作不同,即使完全在一个大型(4亿项事务)但高度次优的数据集(51%的人类水平性能)上训练,也能推断出超越数据集的性能。与返回条件的监督方法相比,离线Q-learning与模型容量的扩展相似,并且具有更好的性能,特别是当数据集是次优的时候。具有多样化数据集的离线Q-learning足以学习强大的表示,促进快速迁移到新的游戏,并在训练游戏的新变体上快速在线学习,比现有的最先进的表示学习方法有所改进。
The potential of offline reinforcement learning (RL) is that high-capacity models trained on large, heterogeneous datasets can lead to agents that generalize broadly, analogously to similar advances in vision and NLP. However, recent works argue that offline RL methods encounter unique challenges to scaling up model capacity. Drawing on the learnings from these works, we re-examine previous design choices and find that with appropriate choices: ResNets, cross-entropy based distributional backups, and feature normalization, offline Q-learning algorithms exhibit strong performance that scales with model capacity. Using multi-task Atari as a testbed for scaling and generalization, we train a single policy on 40 games with near-human performance using up-to 80 million parameter networks, finding that model performance scales favorably with capacity. In contrast to prior work, we extrapolate beyond dataset performance even when trained entirely on a large (400M transitions) but highly suboptimal dataset (51% human-level performance). Compared to return-conditioned supervised approaches, offline Q-learning scales similarly with model capacity and has better performance, especially when the dataset is suboptimal. Finally, we show that offline Q-learning with a diverse dataset is sufficient to learn powerful representations that facilitate rapid transfer to novel games and fast online learning on new variations of a training game, improving over existing state-of-the-art representation learning approaches.
https://arxiv.org/abs/2211.15144



另外几篇值得关注的论文:
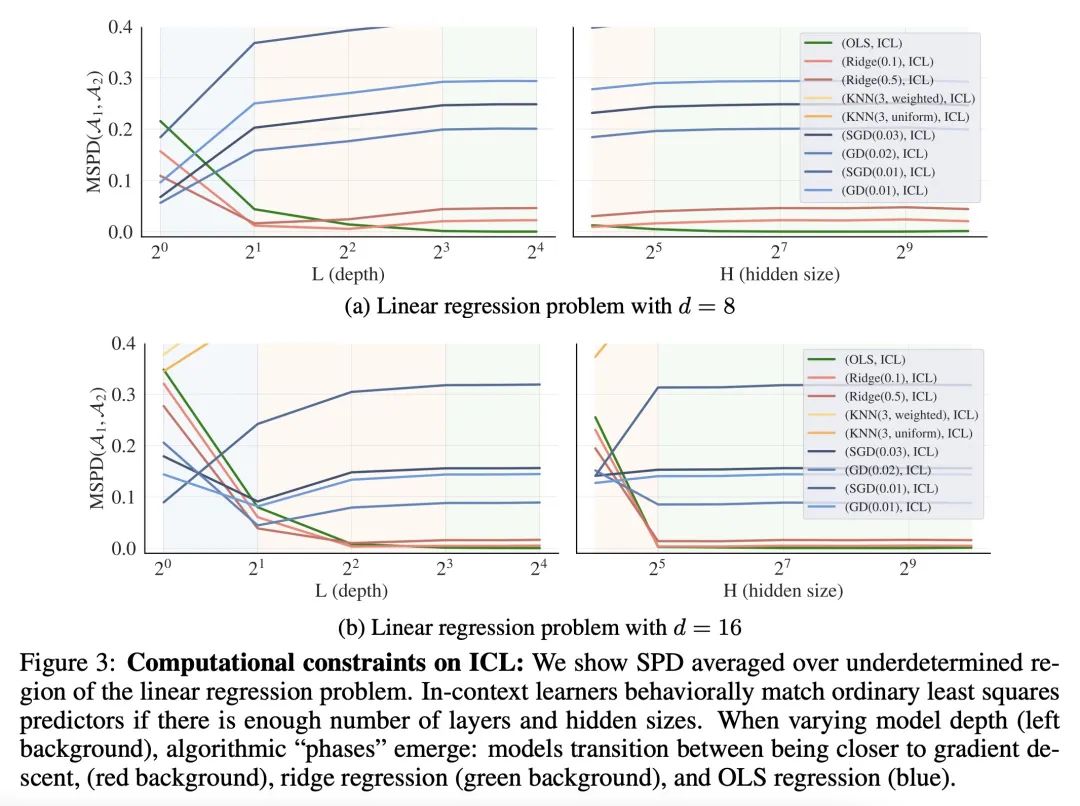
[LG] What learning algorithm is in-context learning? Investigations with linear models
上下文学习是什么学习算法?基于线性模型的调查
E Akyürek, D Schuurmans, J Andreas, T Ma, D Zhou
[Google Research & MIT CSAIL]
https://arxiv.org/abs/2211.15661



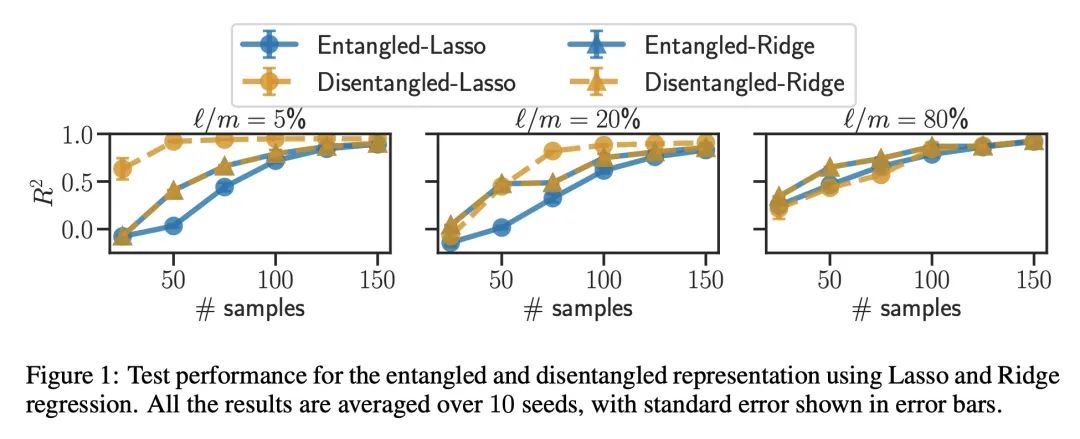
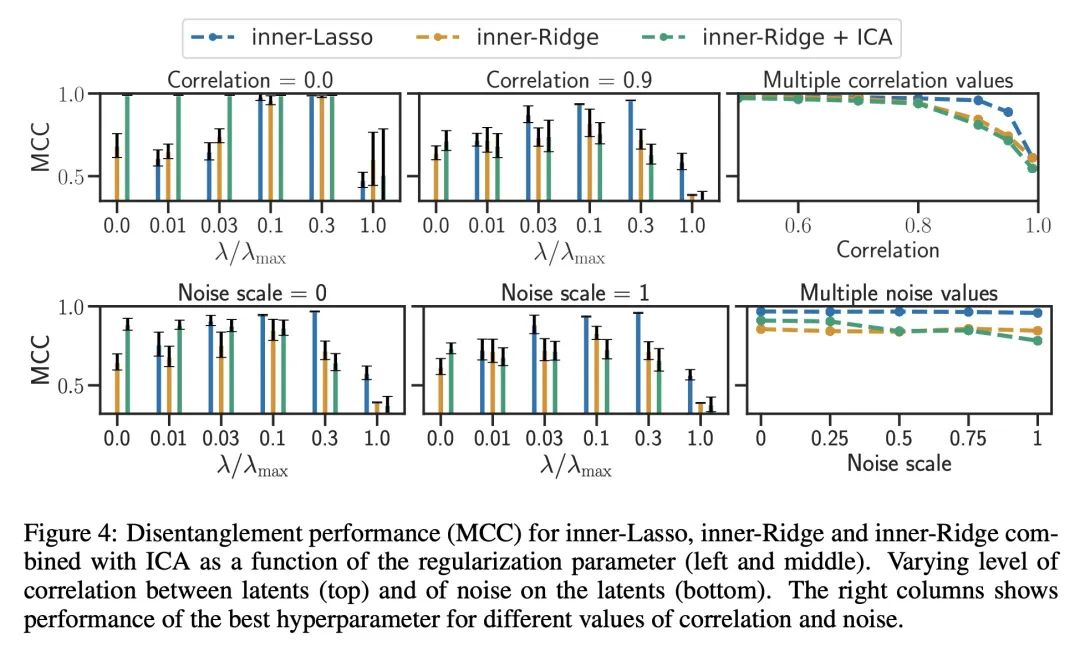
[LG] Synergies Between Disentanglement and Sparsity: a Multi-Task Learning Perspective
多任务学习视角看解耦和稀疏性的协同效应
S Lachapelle, T Deleu, D Mahajan, I Mitliagkas, Y Bengio, S Lacoste-Julien, Q Bertrand
[Université de Montréal]
https://arxiv.org/abs/2211.14666


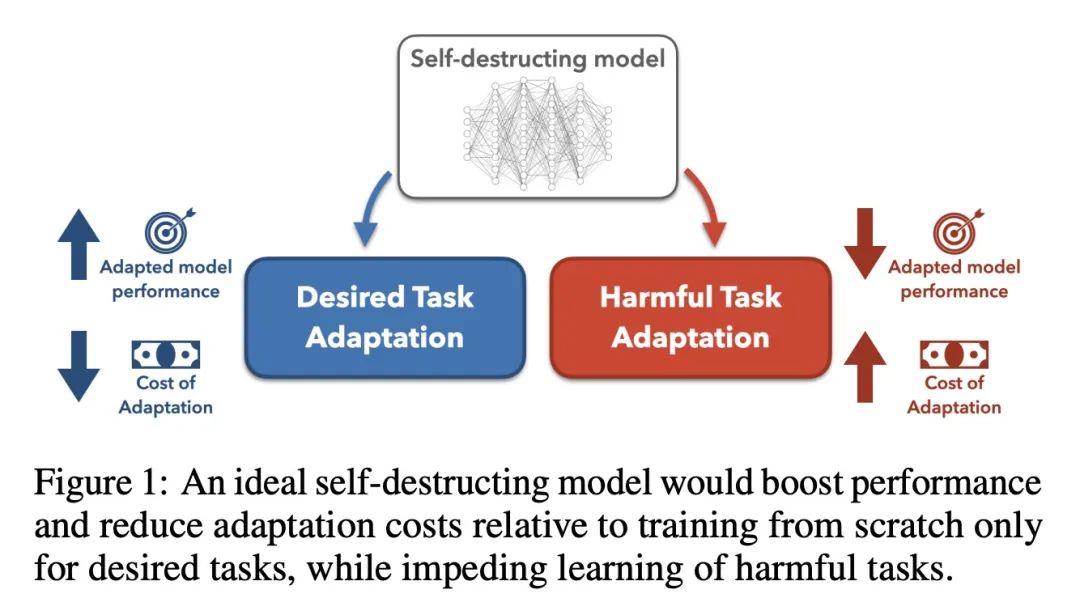
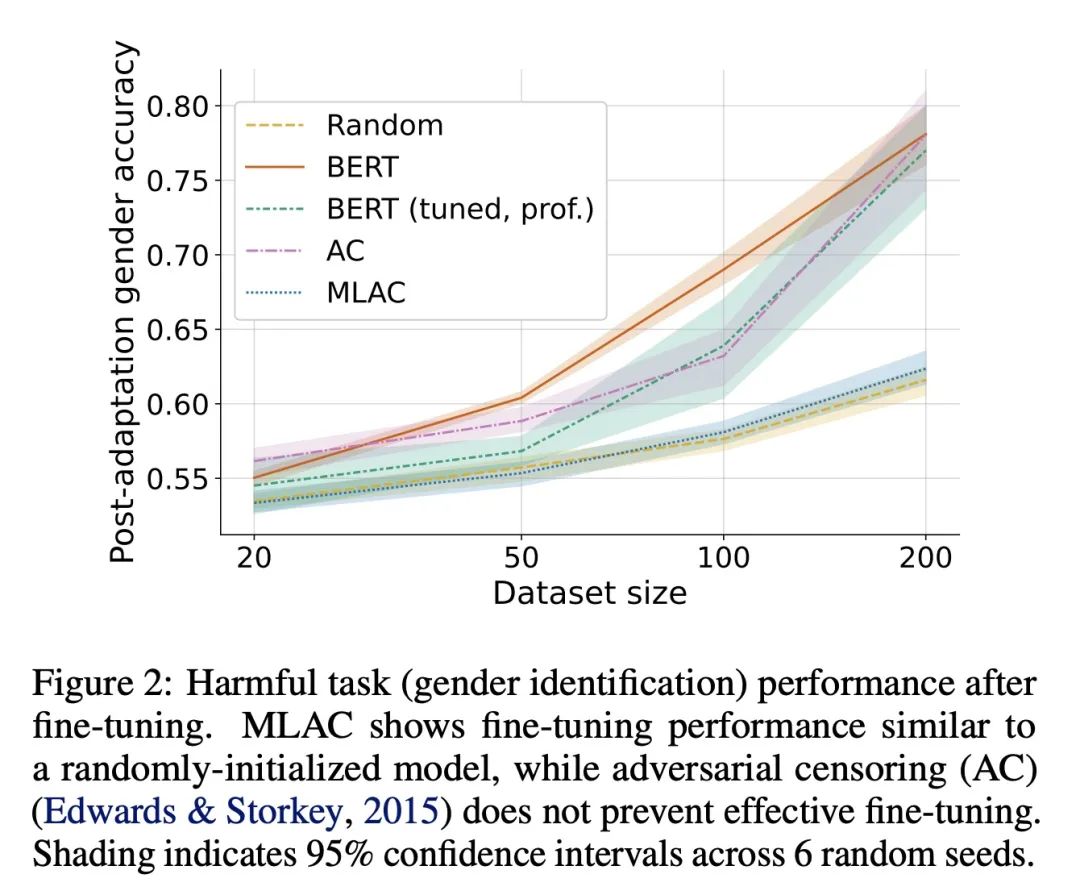
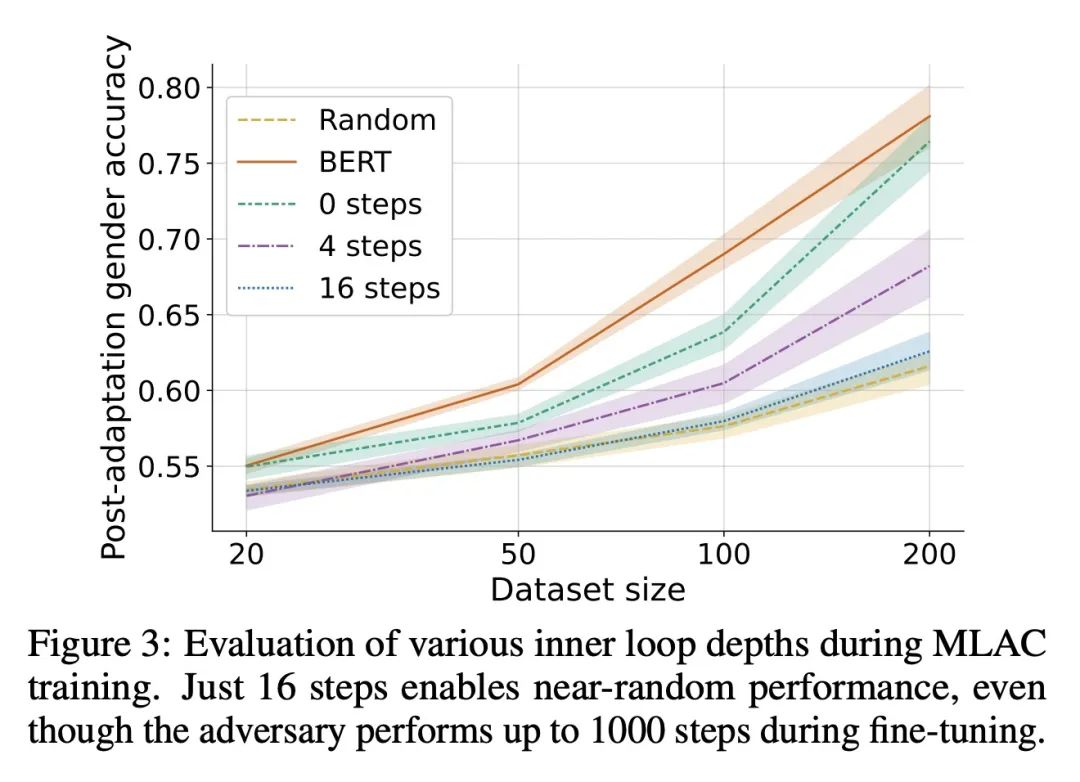
[LG] Self-Destructing Models: Increasing the Costs of Harmful Dual Uses in Foundation Models
用自毁模型提高基础模型不良双重使用成本
E Mitchell, P Henderson, C D. Manning, D Jurafsky, C Finn
[Stanford University]
https://arxiv.org/abs/2211.14946

[LG] A Theoretical Study of Inductive Biases in Contrastive Learning
对比学习归纳偏差理论研究
J Z. HaoChen, T Ma
[Stanford University]
https://arxiv.org/abs/2211.14699



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢