
本文转自公众号“阿里技术”
在近期的多个顶会上,阿里巴巴多篇该方向的研究论文入选。11月30日14点阿里带来包括安全隐私计算、对抗学习、贝叶斯深度学习、异常检测、鲁棒评估、噪声学习、 鲁棒动态图学习、偏微分方程求解等多方向技术趋势的最新顶会论文和专业直播解读https://mp.weixin.qq.com/s/dNCJcRL-z5-vpTspHaOycw

论文链接:https://arxiv.org/pdf/2209.07735.pdf
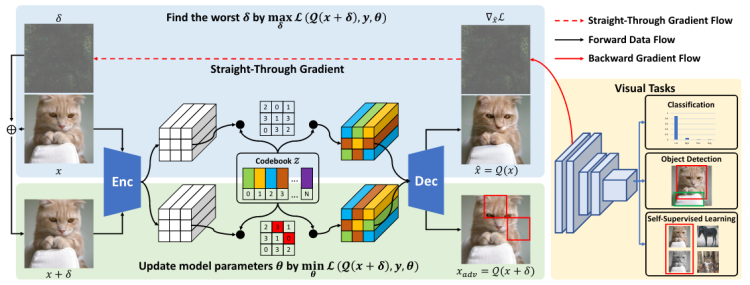
对抗训练目前是最有效的获得鲁棒模型的方法之一,但是对抗训练最大的缺点就是会影响正常样本的识别性能,这导致了对抗训练在工业界无法广泛使用。令人惊讶的是,这种现象在自然语言处理领域中没有出现,对抗训练甚至可以提升NLP模型的泛化性。我们注意到对抗训练在NLP领域和图像领域上的不同点在于NLP领域的输入空间是离散的符号空间。
通过借鉴NLP上对抗训练的优势,我们提出了离散对抗训练 (DAT)。DAT利用 VQGAN将图像连续空间的输入编码到类似文本的离散输入,即视觉词。然后,通过对离散空间进行对抗扰动,最终形成离散化的对抗训练。我们进一步从数据分布的角度进行解释DAT的有效性。此外,作为一种增强视觉表示的即插即用技术,DAT在包括图像分类、目标检测和自监督学习等多个任务上都进行了验证,并且都有显著提升。特别地,当DAT与Masked Auto-Encoding (MAE) 预训练模型结合进行微调,在无需额外数据等情况下,在ImageNet-C上获得31.40mCE,在Stylized-ImageNet上获得32.77%的top-1准确率,构建了新的SOTA。

论文链接:https://thudzj.github.io/ella/paper.pdf
拉普拉斯近似 (Laplace approximation, LA) 及其线性化变体 (linearized LA, LLA) 可以轻松地将预训练的深度神经网络转化为贝叶斯神经网络。现有方法通常引入广义高斯-牛顿 (generalized Gauss-Newton, GGN) 近似来提高可行性。然而,LA和LLA仍然面临着非平凡的低效问题,在实际使用中常依赖对于GGN矩阵的Kronecker-factored、对角的、甚至last-layer近似。这些近似很可能损害学习结果的保真度。
为了解决这个问题,受LLA和神经内切内核(neural tangent kernels, NTKs)之间联系所启发,我们开发了可以加速LLA的Nyström近似方法。我们的方法受益于主流深度学习库中所实现的前向模式自动微分功能,并享有对于近似误差的理论保证。广泛的实验反映了所提方法在可扩展性和性能方面的优势。我们的方法甚至可以处理像vision transformer这样的模型。代码见 https://github.com/thudzj/ELLA 。

论文链接:https://arxiv.org/pdf/2210.04200.pdf
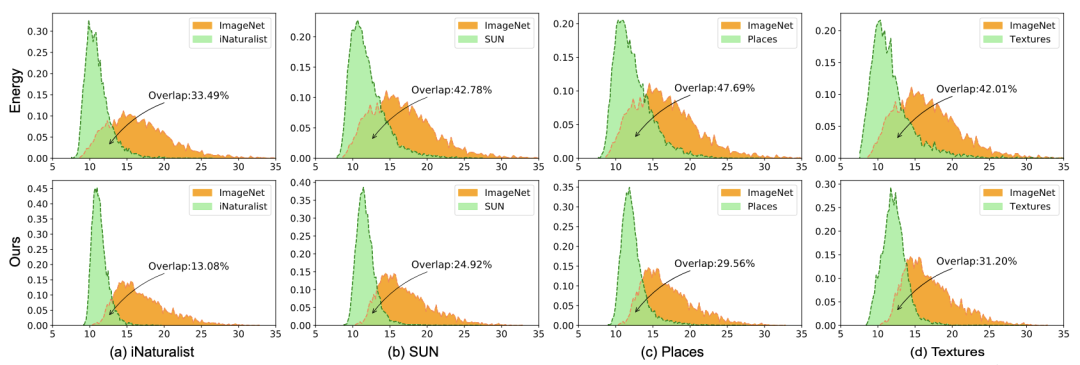
分布外 (OOD) 检测是确保深度神经网络在实际场景中的可靠性和安全性的关键任务。不同于以往大多数OOD检测方法侧重于设计OOD score或引入各种异常值样本进行重新训练模型,我们从典型性的角度深入研究OOD检测中的关键因素,并将深度模型的高概率区域的特征视为该特征的典型集。我们提出了将原始特征校正为典型特征,并用典型特征计算 OOD 分数,以实现可靠的不确定性估计。特征校正可以作为一个即插即用的模块,应用到各种OOD score方法中。
我们评估了我们的方法在常用基准(CIFAR)和更具挑战性的基准(ImageNet)上的优越性。值得注意的是,我们的方法在 ImageNet 基准测试的平均 FPR95 中优于最先进的方法高达 5.11%。

论文链接:https://arxiv.org/pdf/2210.03895.pdf
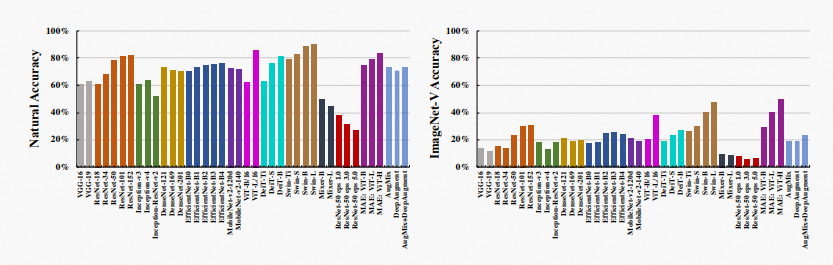
计算机视觉模型在数据分布发生偏移时鲁棒性较差。已有工作主要研究模型对2D图像变换的鲁棒性,而较少探索3D世界中的视角变化,然而其在自动驾驶等应用中十分普遍。本文提出了ViewFool方法寻找误导视觉识别模型的对抗视角。通过将现实世界中的物体编码为神经辐射场 (NeRF),ViewFool可以在熵正则项的约束下学习对抗视角的分布,有助于处理真实相机姿态的波动并减轻真实物体与其神经表示之间的差异。
基于ViewFool,本文构建了视角OOD数据集ImageNet-V,用于对图像分类器的视角鲁棒性进行基准测试。实验结果表明,40余种具有不同架构、目标函数和数据增强的分类器在ImageNet-V上的性能出现显著下降。

论文链接:https://thudzj.github.io/dualn/paper.pdf
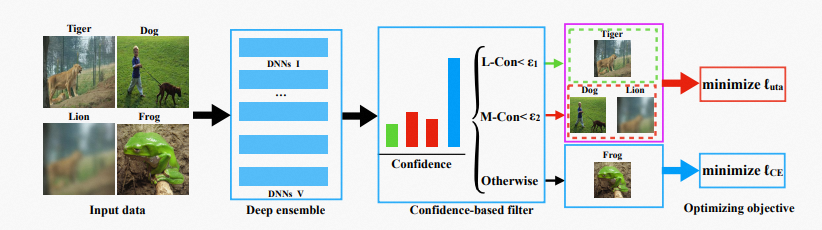
尽管深度神经网络 (DNN) 已经在各种计算机视觉任务中取得了显著成功,但是对于模型优化通常需要大量良好标记的图像。然而,在现实世界中收集的数据不可避免地会受到各种噪声的影响,这样的数据往往会严重损害模型的性能。以前,已经有许多工作尝试如何在带躁数据的背景下可靠地训练神经网络,但是之前的工作一般只考虑标签噪声(noisy label)。我们在这项工作中研究了如何在图像、标签的联合噪声下的训练一个可靠的神经网络。
具体而言,我们提出了基于置信度的样本过滤器来逐步检测噪声数据。接着,我们提出了基于神经网络不确定性的学习机制,即惩罚检测到的噪声数据的模型不确定性(model uncertainty),通过这种训练方式使得神经网络不会过拟合到噪声数据而损害模型性能。一系列实验表明,我们提出的方法在各种具有挑战性的噪声数据集上表现良好,所提出的方法在图像分类性能上优于以前的基线模型。

论文链接:https://arxiv.org/pdf/2210.03526.pdf
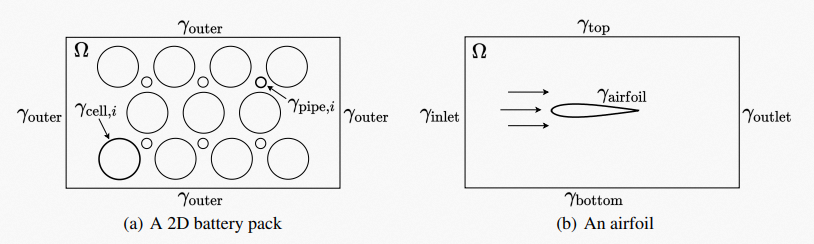
我们提出了一个统一的硬约束框架,用于通过神经网络求解几何复杂的PDE。在前人工作的基础上,我们将硬约束框架拓展到了最常用的三类边界条件:Dirichlet、Neumann 和 Robin 边界条件。
具体来说,我们首先从混合有限元方法中引入“额外场”技术重写偏微分方程,从而将三种类型的边界条件统一等价转换为线性形式。在此基础上,我们解析地导出了边界条件的通解,用于构建能自动满足边界条件的假设集。训练这样的假设集时,我们不必将边界条件对应的残差加入损失函数,从而更高效地求解几何复杂的PDE,减轻PDE和边界条件对应的损失函数项之间的不平衡竞争。此外,我们从理论上说明“额外场”技术可以稳定训练过程。我们选取了燃料电池组、飞机机翼等具有现实意义的几何复杂PDE的例子测试我们的方法。实验结果表明我们的方法取得了SOTA效果。

论文链接:
https://openreview.net/pdf/9ae6d4aa42e3a216e5725a1d84c926b53c7d4484.pdf
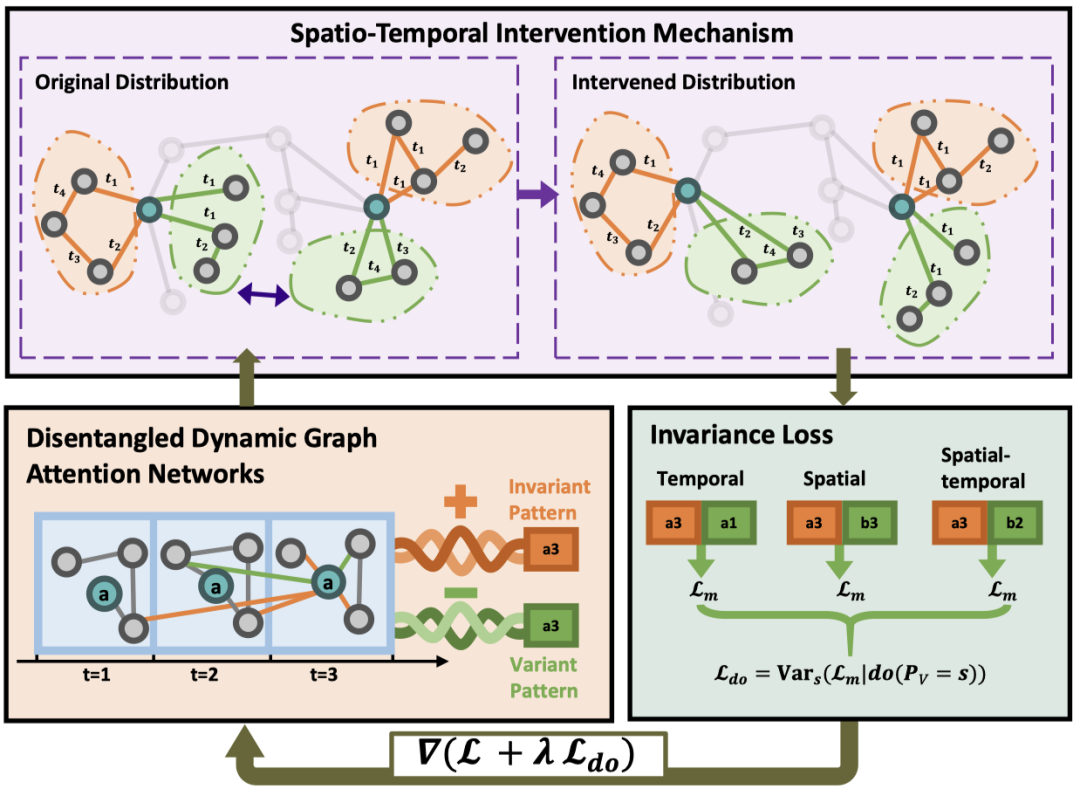
动态图神经网络(DyGNNs)通过利用图的结构和时间动态表现出强大的预测能力。然而,现有的动态图神经网络难以处理动态图中自然存在的分布变化。在本文中,我们提出通过发现和利用不变模式(invariant pattern),即发现预测能力稳定的结构和特征来应对动态图中的时空分布变化,这面临着两个关键的挑战。1)如何区分动态图中变化模式(variant pattern)和不变模式(invariant pattern),这涉及到深入挖掘随时间变化的图结构和节点特征。2)如何用发现的两种模式处理时空分布的转变。
为了解决这些挑战,我们提出了基于Disentangled Intervention的动态图注意网络(DIDA)。我们提出的方法通过发现和充分利用不变的时空模式,可以有效地处理动态图的时空分布转移。

论文链接:https://arxiv.org/pdf/2210.01318.pdf
本论文被VLDB 2023收录。VLDB与SIGMOD、ICDE并称数据库领域三大顶级会议,收录研究机构、科技企业等在数据库领域最前沿的研究成果。
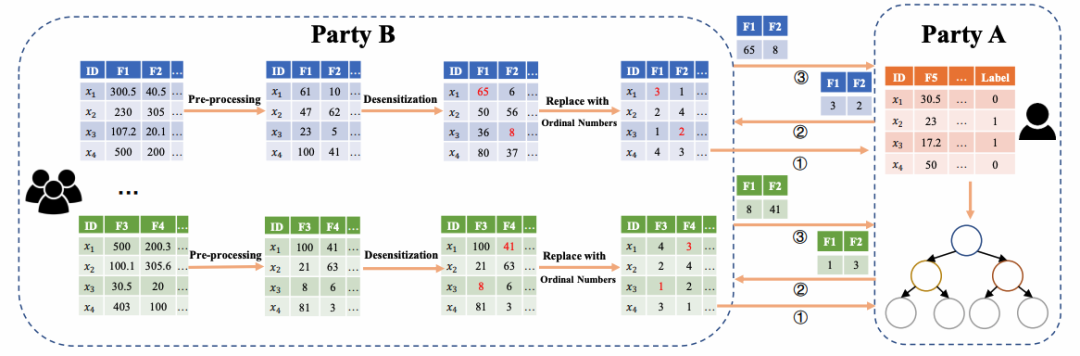
本论文提出了更高效的隐私保护联邦梯度提升决策树训练。已有解决方案大多基于密码学技术,虽可提供极高的安全性,但性能较差,很难在大规模数据上得到应用。本论文引入了苹果和谷歌在采集数据时使用的差分隐私技术,在隐私保护和模型准确性之间取得更好的平衡,在适当隐私保护的条件下有效提高模型训练结果的准确性。对原始数据执行满足距离差分隐私定义的脱敏算法后,便可直接调用已有算法完成训练。实际落地结果表明,千万级别规模数据的训练仅需1小时即可完成。
源代码已开源:https://github.com/alibaba-edu/mpc4j 。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢