今天向大家分享 CVPR 2022 论文『Large-scale Video Panoptic Segmentation in the Wild: A Benchmark』,介绍一个新的视频全景分割(Video Panoptic Segmentation)领域 Benchmark:VIPSeg。
-
论文链接:https://openaccess.thecvf.com/content/CVPR2022/papers/Miao_Large-Scale_Video_Panoptic_Segmentation_in_the_Wild_A_Benchmark_CVPR_2022_paper.pdf
-
项目链接:https://github.com/VIPSeg-Dataset/VIPSeg-Dataset/
前言
作者提出了一个新的视频全景分割(Video Panoptic Segmentation)领域 Benchmark:VIPSeg,与其他视频全景分割数据相比,VIPSeg有着数据量更多(3536个视频),场景更齐全(232个场景,124个类别)的优点。同时,作者也设计了一种基于切分短片(clip)的视频全景分割框架,在VIPSeg上达到了Sota性能。
VIPSeg数据集共包含3536个视频,84750帧。并且均匀分布232个现实复杂野外场景。每个视频长度在3s~10s不等,帧间隔为 5fps。
VIPSeg与其他VPS数据集的对比如下表所示,可以明显看出VIPSeg的数据更多更丰富。
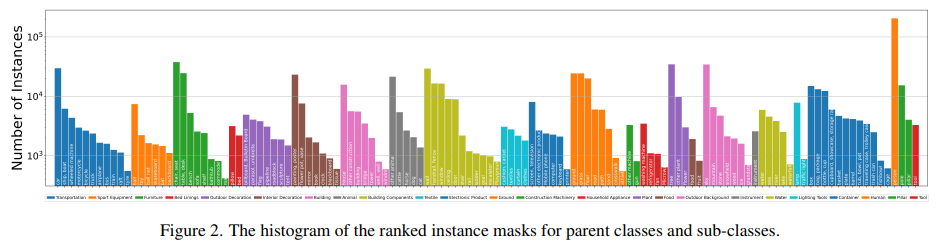
VIPSeg数据集各类别分布如下,可以看出各类别实例数量分布均匀,并没有很严重的长尾现象。
数据集中共包含124个类别,其中58个类为things(易于区分instance的,如:人,狗),66个类为stuff(不易区分instance,如:天空、草地)。
VIPSeg数据集的标注流程分为两个阶段,分别为Sparse Annotation and Tracking Loop 与 Dense Pixel-label Propagation Loop。
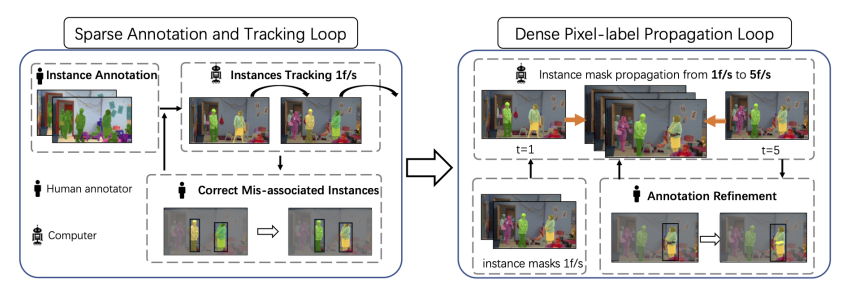
Sparse Annotation and Tracking Loop:稀疏标注阶段
在第一个阶段,作者先通过人工标注第一帧,再通过最先进的目标跟踪算法(AOT)获取 1 fps 的视频稀疏标注结果,再通过人工对此结果进行修正。
Dense Pixel-label Propagation Loop:稠密传播阶段
在第二个阶段,作者在 1 fps 的基础上 通过 AOT 对 Mask 进行传播,从而获取 5 fps 的 视频全景标注结果,再通过人工修正的方式对传播的结果进行修正。内容中包含的图片若涉及版权问题,请及时与我们联系删除





评论
沙发等你来抢