
【论文标题】Supervised Pretraining for Molecular Force Fields and Properties Prediction
【作者团队】Xiang Gao, Weihao Gao, Wenzhi Xiao, Zhirui Wang, Chong Wang, Liang Xiang
【发表时间】2022/11/23
【机 构】字节跳动
【论文链接】https://arxiv.org/pdf/2211.14429v1.pdf
机器学习方法在分子建模任务中已经变得很流行,包括分子力场和性质预测。传统的监督学习方法由于缺乏特定任务的标记数据而受到影响,促使人们将大规模数据集用于其他相关任务。本文在一个8600万个分子组成的数据集上预训练神经网络,以原子电荷和三维几何形状作为输入,以分子能量作为标签。实验表明,与从头开始训练相比,对预训练的模型进行微调可以显著提高七个分子特性预测任务和两个力场任务的性能。本文还证明了从预训练模型中学到的表征包含足够的分子结构信息,表征可以预测许多分子的性质,包括原子类型、原子间距离、分子骨架和分子片段的类别。本文的研究结果表明,监督预训练是分子模型中一个很有前途的研究方向。
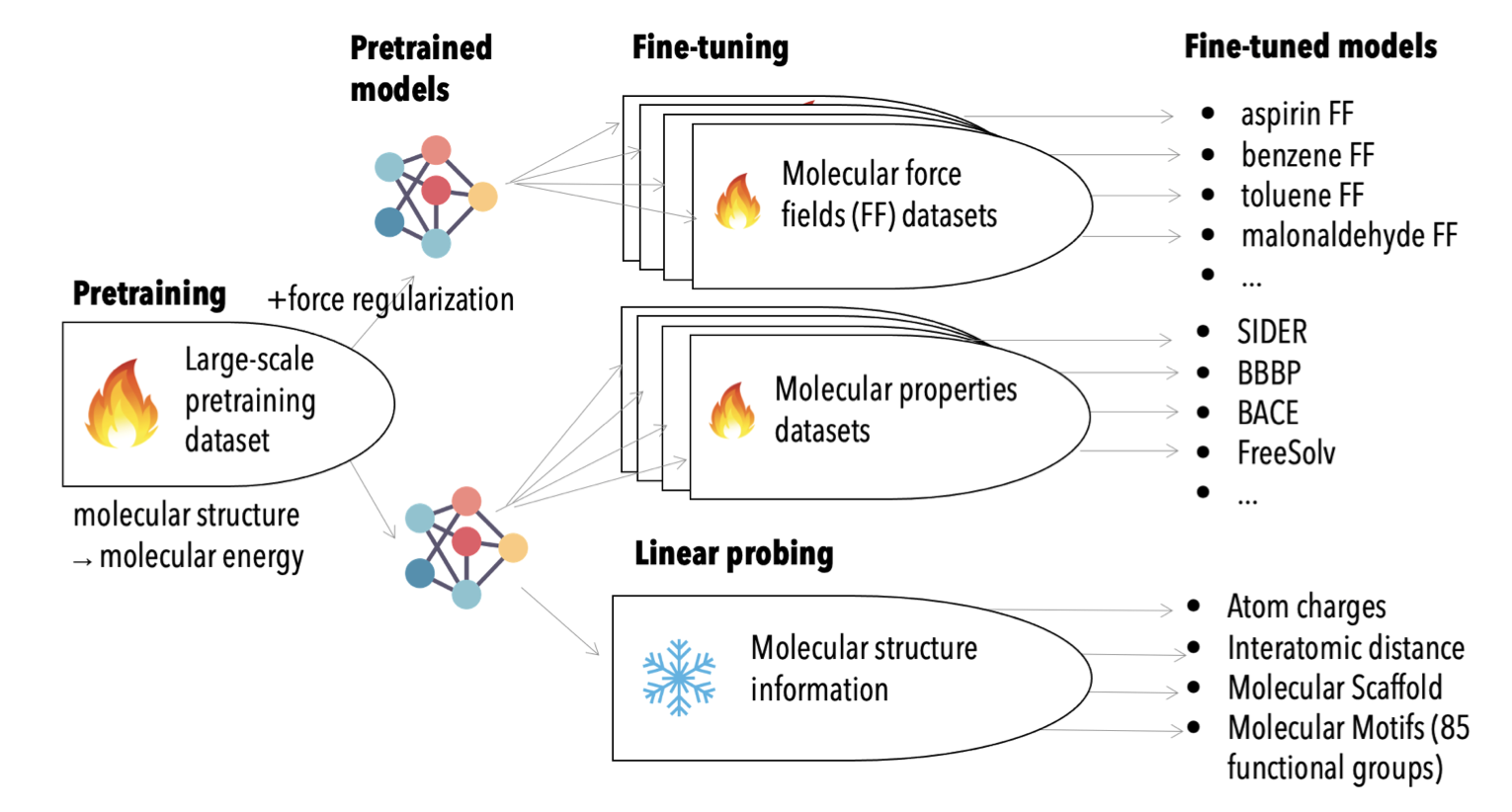
上图展示了本文的预训练框架。本文策略可以提高微调在各种下游任务中的性能,包括分子力场和分子属性预测,如毒性和分子水溶性。力场任务输入原子坐标和电荷、输出作用于每个原子的力的矢量。属性预测任务输出标量。
线性probing任务表示,学习到的表征可以预测输入的原子类型、原子间距离、分子支架和85个官能团的存在。
本文是基于如下考虑的:
-
监督的预训练数据应该很丰富。基本物理性质的数据,如分子能量,通常比较丰富。本文在这项工作中使用的数据集,PubChem PM6数据集包含2.21亿个分子的能量计算。
-
监督下的预训练标签应该是准确的,而不是嘈杂的。分子能量可以用既定的基于第一原理的方法计算,因此,所有样品的标签都可以通过相同的机制获得。相比之下,以前的工作中使用的实验测量的生化检测方法由于不同数据源的实验条件或方法不同,可能会有噪音。
-
监督的预训练任务应与各种下游任务相关。许多分子属性是描述分子与环境之间相互作用的量,这些过程是由作用在原子上的力所决定的,因为这是相对于原子坐标的分子势能的梯度。分子能量和分子结构之间的这种密切关系鼓励预训练模型理解和表现分子结构,这对于在各种下游任务中表现良好是很重要的。
-
力场计算加入了正则化,使相对于原子坐标的能量梯度的最小化。这使得预训练的模型更适用于力场预测任务。相比之下,以前的大多数预训练任务不使用准确的原子坐标,而只成使用拓扑结构。
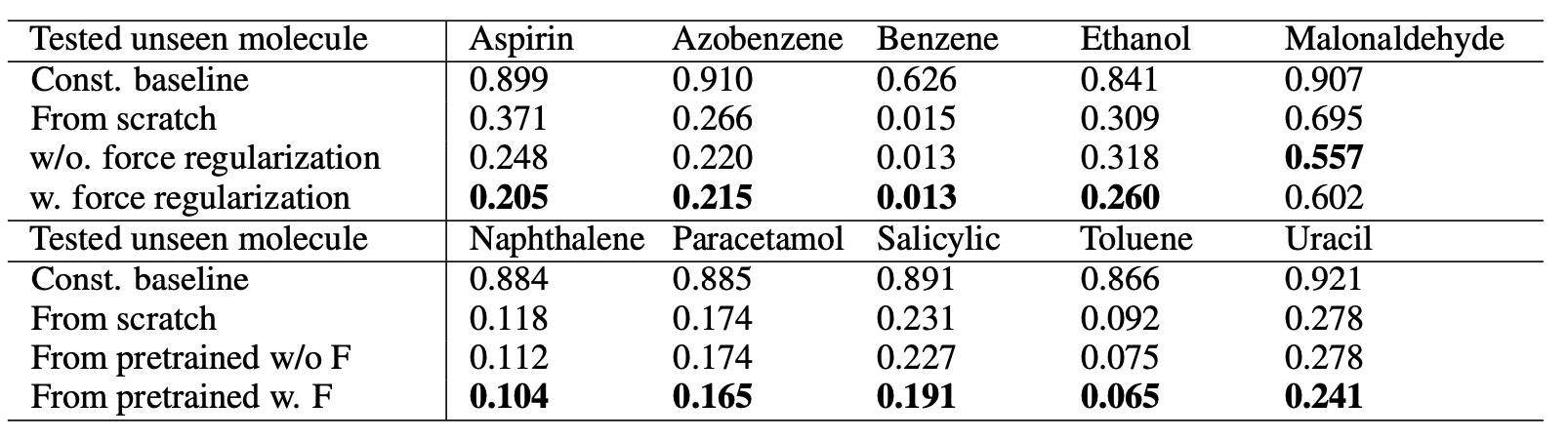
本文骨架模型使用使用GemNet-T模型,上图展示了在力场上域外实验的结果,评价指标MAE,使用MD17 DFT数据集,对10个分子留一测试,其中基线为0力,从结果来看测试误差当然比域内测试要高。其中苯和甲苯的损失相对较小,可能是因为它们的主要结构成分苯环已经出现在训练集中的几个分子中(阿司匹林、偶氮苯、水杨酸和萘),这意味着训练数据中存在类似的子结构对测试性能有很大帮助。
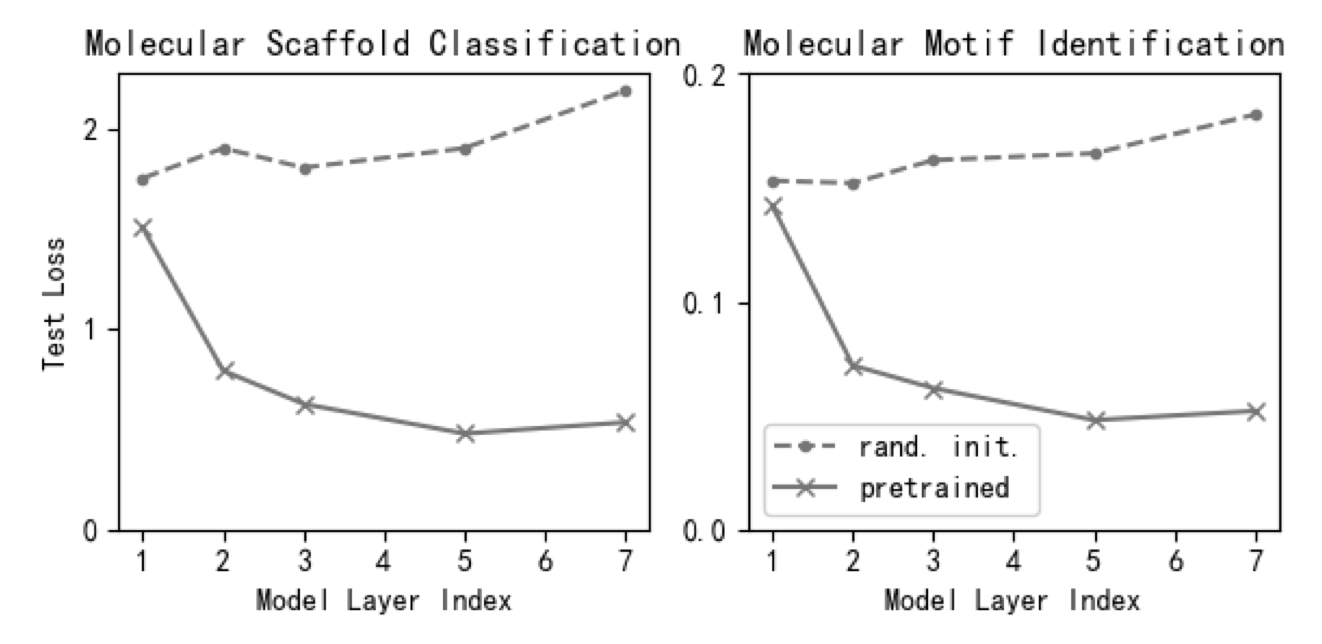
上图展示了子结构预测的结果。本文也使用linear probing方法进行结构相关任务,具体包括:
-
原子电荷分类:节点表示是否包含原子电荷的信息,预测原子电荷的概率分布
-
原子间距离预测:坐标预测
-
分子骨架分类:选择频率最高的100个骨架,做多分类预测任务
-
motif识别:预先指定85个官能团作为分子motif,比如aliphatic carboxylic acids和H-pyrrole nitrogens,任务为多个二分类任务判断motif是否出现在分子中
结论为:预训练模型的性能明显优于随机参数模型,预训练的模型在后面几层逐渐获得分子的全局表示,随着信息传递到更深的层次,该表征嵌入了更多的全局信息,更容易预测分子子结构任务。
创新点
-
本文提出了一种有监督的预训练策略,可以提高分子建模的性能。预训练的任务是预测分子能量,这是一个与各种下游任务相关的基本物理量,存在大规模的数据集。
-
本文表明,在没有人工设计或约束的情况下,预训练模型可以学会嵌入分子结构信息。这对于广泛的下游分子特性预测任务是必要的。
-
本文表明,与从头开始训练相比,所提出的预训练方法有助于力场模型对未见过的分子有更好的泛化。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢