
关系抽取(RE)是 NLP 的核心任务之一,是构建知识库、事件抽取等下游应用的关键技术。多年来受到研究者的持续关注。
本小节工作来自 EMNLP 2022 主会论文:Revisiting DocRED - Addressing the False Negative Problem in Relation Extraction

数据代码:
1.1 背景介绍

▲ 图1.1 Re-DocRED 文章样本
具体的任务定义为:给定一个文档 D,其中的实体数目为 N,模型需要预测所有实体对之间的关系,总共需要做 N(N-1)个实体对的关系分类。DocRED 数据集是文档级关系抽取任务中最被广泛应用的数据集,自 2019 年发布以来已经有相当多的工作基于该数据集提出了许多文档级关系抽取的模型,然而文档级关系抽取这一任务的 SOTA 却一直在 60 - 65F1 左右。
在我们的初步研究中发现,DocRED 数据集中存在大量漏标的实体关系,并且同时存在于训练和测试集中,这些漏标的实体对被称为假负类样本(False Negative Example)。假如一个实体对存在特定关系,但在测试集中未被标注,即便模型预测出了该关系也会被判为错误。如图 1 所示,从高亮的句子中可以推测出 Max Martin 与 Shellback 都是流行歌曲 I knew you were trouble 的制作人, 但是 DocRED 数据集中仅标注了 Max Martin。
这些假负类样本不仅影响模型的训练过程,测试集中的假负类样本更是直接影响数据集本身的合理性。我们在初步的实验中发现,尽管 DocRED 数据集包含 96 种关系,但是区分这 96 种关系本身对于目前的 SOTA 模型(KD-DocRE [2])并不困难,其表现可以达到 90F1 以上,而由于假负类样本的存在,在包含 ‘no_relation’ 的关系分类任务中仅能取得 64 左右的 F1。
这说明目前文档集关系抽取的瓶颈并不在于区分多种关系,而在于判断关系是否存在,这部分的实验请在原文中的第二章节,由于篇幅所限,本文中不对其展开赘述。由于假负类问题同时存在于 DocRED 的训练集以及测试集中,我们认为有必要对 DocRED 进行重新标注,以对文档级别关系抽取提供更高质量的评估。
HyperRED: 用于超关系抽取的数据集与一种立方体关系抽取方法
本小节工作来自 EMNLP 2022 主会论文:A Dataset for Hyper-Relational Extraction and a Cube-Filling Approach

数据代码:
2.1 问题提出
关系抽取(Relation Extraction)能帮助构建大规模知识图谱 [7],但目前的方法没有考虑每个关系三元组的限定信息 (Qualifier),例如时间、数量或地点。限定信息形成了超关系事实 [8](Hyper-Relational Fact),可以更好地代表丰富而复杂的知识图谱结构。例如,关系三元组(Leonard Parker,Educated At,Harvard University)可以通过限定信息(End Time,1967)变成更完整。
因此,我们提出了超关系抽取(Hyper-Relational Extraction)的任务,以从文本中抽取更具体和完整的事实。为了支持这项任务,我们标注了 HyperRED,一个大规模的数据集。现有模型无法执行超关系抽取,因为它需要一个模型来考虑三个实体之间的交互。
因此,我们提出了立方体关系抽取(CubeRE)模型,这是表格填空 [9](Table-Filling)方法启发的模型,并明确考虑了关系三元组和限定信息之间的交互。为了提高模型效率并减少负类的不平衡,我们进一步提出了一种立方体剪枝(Cube-Pruning)方法。我们的实验表明,CubeRE 优于其他基线模型,并指出未来研究的可能方向。
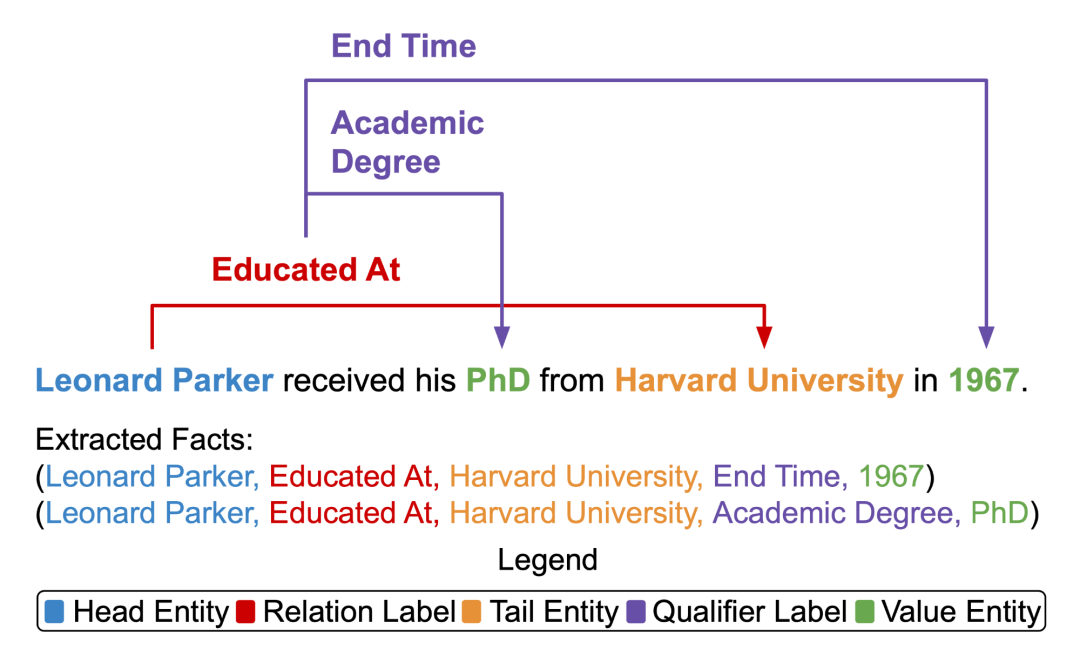
▲ 图2.1 超关系抽取任务。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢