
近些年来,通过各种内容平台浏览视频或者是阅读文章的用户越来越多,而现有的推荐算法有时难以很好地建模用户的偏好,因此需要更准确的推荐系统模型。但已知的推荐系统(RS)的基准数据集要么是小规模的,要么是用户反馈形式非常有限。在这些数据集上评估的推荐系统模型往往缺乏实用性,难以为大规模真实场景应用提供足够的价值。
在本文中,来自腾讯、西湖大学的研究者发布了 Tenrec 数据集,一套超大规模的推荐系统公开数据集和评测基准,它记录了来自四种不同推荐场景的各种用户反馈。

具体来说,Tenrec 有 以下五个特点:(1)规模大,包含约 500 万用户和 1.4 亿次互动;(2)不仅有正向的用户反馈,也有真实的负反馈;(3)它包含四种不同场景中重叠的用户和重叠 items;(4)它包含各种类型的用户正反馈,以点击、点赞、分享形式等;(5)它包含了除了用户 id 和 item id 之外的附加特征,如用户年龄、性别和 items 类别等。
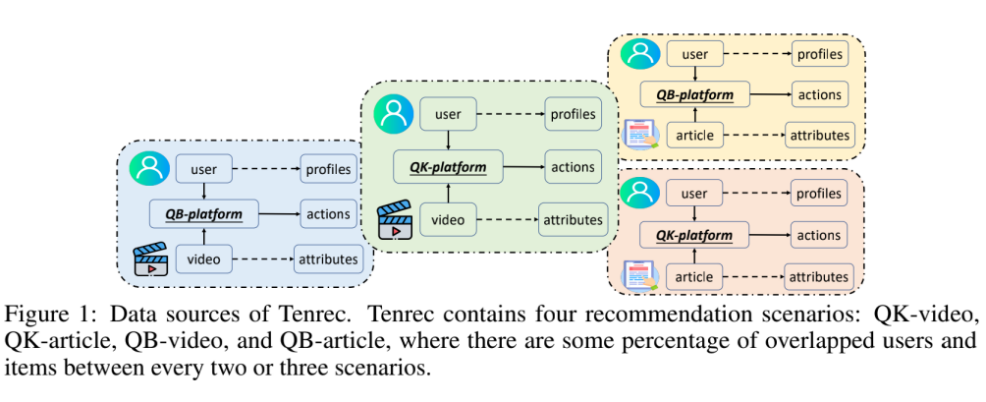
研究者通过对每个任务运行几个经典的 Baseline 模型来验证 11 个不同的推荐任务上的 Tenrec 表现。Tenrec 有很大的潜力成为一个对多数流行推荐系统任务有用的基准数据集。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢