
CLIP已经被证明是一种高效的文本-图像对预训练方法,CLIP模型不仅能够实现可迁移的图像特征,而且也可以广泛应用在一些多模态任务中,比如最近比较火的AIGC模型如DALLE2和Stable Diffusion均使用了CLIP模型来引导文本到图像的生成。
近日,Meta AI团队(Kaiming He组)在论文Scaling Language-Image Pre-trainingvia Masking中提出了一种简单高效的CLIP加速训练方法FLIP:只需要mask掉部分图像,就可以将CLIP的训练过程加速2~3倍,而且可以实现更好的性能。这篇文章将简单介绍FLIP的主要方法以及一些重要的实验结论。
主要方法
CLIP包括两个模型:文本encoder和图像encoder,训练采用文本-图像对数据,并通过对比学习将文本encoder提取的文本特征和图像encoder提取的图像特征进行对齐,具体过程如下所示(详细版见之前的文章神器CLIP:连接文本和图像,打造可迁移的视觉模型):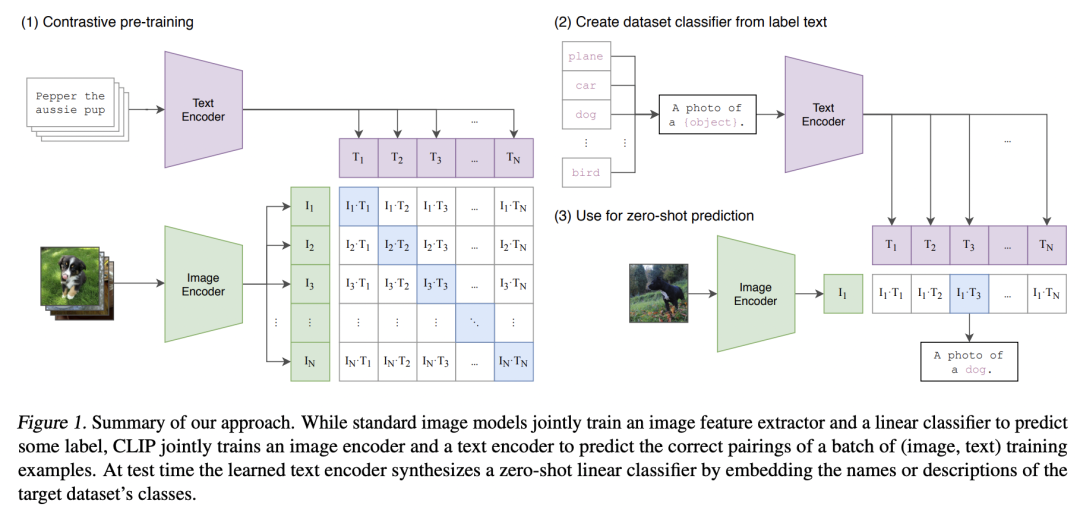 FLIP的核心改进就是在训练过程对图像进行随机mask,image encoder只处理未mask的patches(和之前的MAE方法一致),如下图所示:对图像进行mask,主要有两个好处:一是由于image encoder只处理部分patches,降低了计算用时,这样同样的训练时间内可以学习更多的图像-文本对;二是image encoder的显存使用也下降(mask掉50%,显存消耗就下降50%),这样在一定的硬件资源下就可以实现更大的batch size,而对比学习往往需要较大的batch size。当然对图像mask,也会造成部分信息丢失,但是这也可能是一种正则化方法。FLIP和CLIP采用同样的对比学习损失来进行预训练,虽然基于图像mask的image encoder也可以直接应用在正常的图像,但是为了减少分布上gap,FLIP在最后增加了少量的unmasking训练,即像正常的CLIP那样不对图像进行mask,这可以进一步提升预训练模型的性能。
FLIP的核心改进就是在训练过程对图像进行随机mask,image encoder只处理未mask的patches(和之前的MAE方法一致),如下图所示:对图像进行mask,主要有两个好处:一是由于image encoder只处理部分patches,降低了计算用时,这样同样的训练时间内可以学习更多的图像-文本对;二是image encoder的显存使用也下降(mask掉50%,显存消耗就下降50%),这样在一定的硬件资源下就可以实现更大的batch size,而对比学习往往需要较大的batch size。当然对图像mask,也会造成部分信息丢失,但是这也可能是一种正则化方法。FLIP和CLIP采用同样的对比学习损失来进行预训练,虽然基于图像mask的image encoder也可以直接应用在正常的图像,但是为了减少分布上gap,FLIP在最后增加了少量的unmasking训练,即像正常的CLIP那样不对图像进行mask,这可以进一步提升预训练模型的性能。
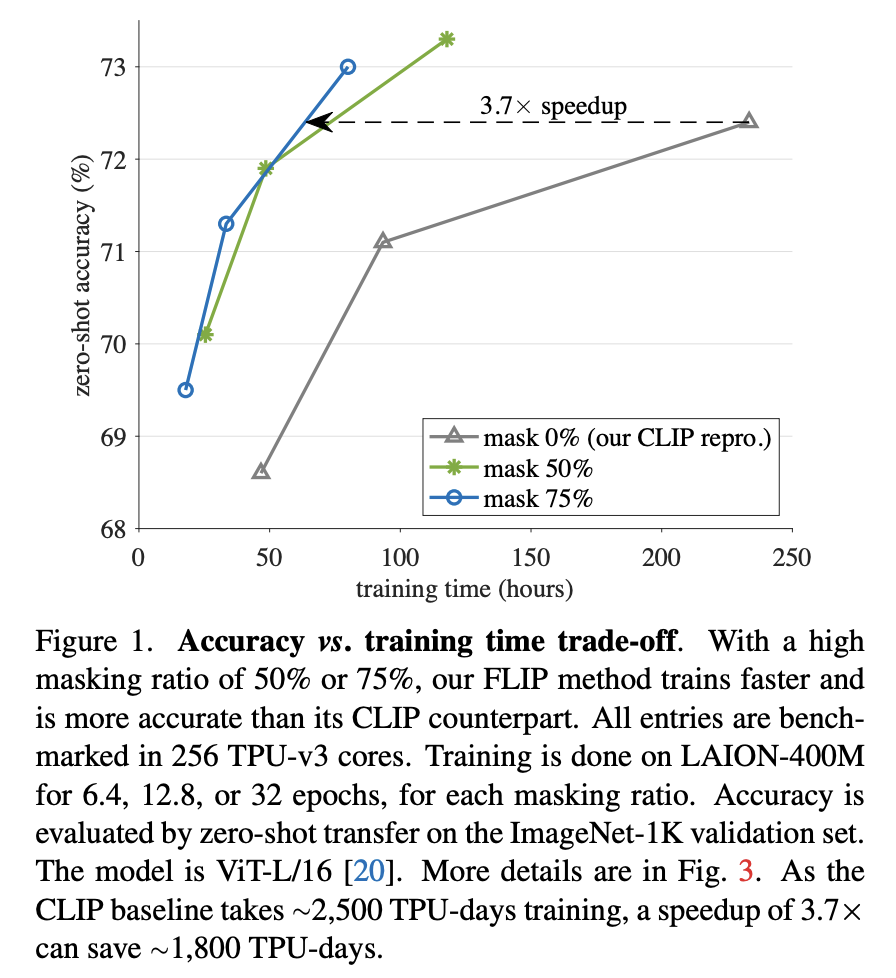
由于CLIP的训练数据WIT-400M并没有开源,所以论文采用开源的LAION-400M进行实验,并将FLIP和基于LAION-400M训练的CLIP进行直接对比。下图展示了基于ViT-L/16模型(image encoder)的FLIP和OpenCLIP的对比结果,可以看到训练同样的epochs时(32 epochs),**mask 50%的FLIP可以提升训练速度2倍,而且在ImageNet1K上zero-shot准确度可以提升0.9%,而mask 75%的FLIP可以提升训练速度2.9倍,而且准确度可以提升0.6%**。值得注意的是,如果不进行unmasking tuning,FLIP的性能略有下降,特别是mask 75%的FLIP,其性能略差于CLIP,这说明测试和训练过程中的较大分布gap还是会一定程度影响性能的。在具体的实现上,FLIP和原始的CLIP在image encoder和text encoder上和OpenAI的CLIP有如下不同:
-
FLIP的image encoder和原始的ViT一样,在patch embedding后没有采用额外的LayerNorm,而且用global average pooling来提取最后的全局特征(CLIP 采用class token的特征); -
FLIP的text encoder是一个非自回归的transformer,而CLIP采用了自回归的transformer(加上causal attention mask),另外采用长度为32的WordPiece tokenizer,CLIP采用长度为77的BytePairEncoding tokenizer。
论文里面也指出,这些设计上的不同并不会导致较大的性能差异。另外模型训练时基于谷歌的JAX框架在TPUv3上训练的。除了ViT-L/16,论文还基于ViT-B/16,ViT-L/14以及ViT-H/14进行了实验,在ImageNet1K上的结果如下表所示,可以看到FLIP(mask 50%)在zero-shot性能上可以超过同样基于LAION-400M复现的CLIP(除了B/16)以及开源的OpenCLIP,而略差于OpenAI的CLIP,在linear probe和fine-tune实验上可以得到同样的结论。
- 本文转载于"机器学习算法工程师" https://mp.weixin.qq.com/s/aum75-d4bxM5sveJQRbsEQ
- 更多内容可见 FLIP | 恺明团队新作,MAE助力CLIP更快更高精度
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢