
【标题】Good, Better, Best: Textual Distractors Generation for Multiple-Choice Visual Question Answering via Reinforcement Learning
【作者团队】Jiaying Lu, Xin Ye , Yi Ren , Yezhou Yang
【发表日期】2022.4.18
【论文链接】https://arxiv.org/pdf/1910.09134.pdf
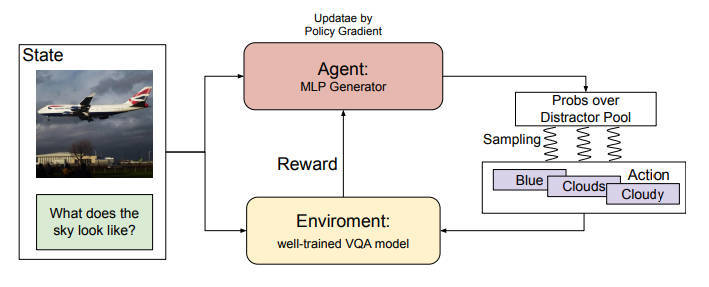
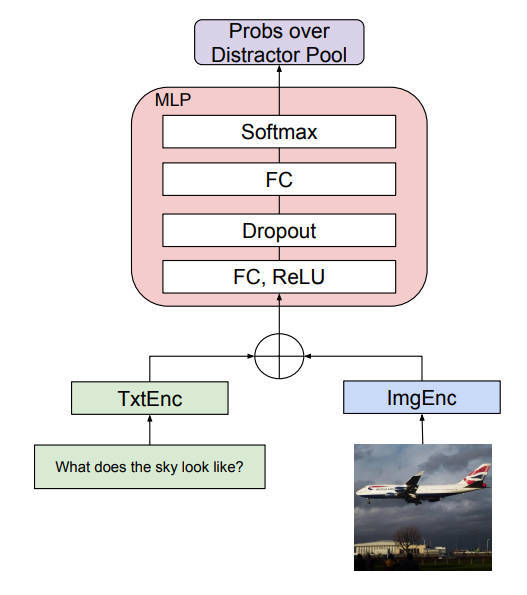
【推荐理由】随着自动构建大规模多选题VQA数据的需求的增长,本文引入了一个新的任务,称为VQA的文本干扰因素生成(DG-VQA),DG-VQA任务的目的是在没有地面真实训练样本的情况下生成干扰因素,因为这种资源很少。为了在无监督的情况下处理DG-VQA,本文提出了GOBBET,这是一个基于强化学习(RL)的框架,利用预先训练好的VQA模型作为替代知识库来指导干扰源的生成过程。在GOBBET中,预训练的VQA模型作为RL环境,为输入的多模态查询提供反馈,而神经分心器生成器则作为智能体,采取相应行动。本文建议使用现有的VQA模型的性能下降作为生成的分心物的质量指标。另一方面,文中通过数据增强实验展示了生成的分心器的效用,因为当人工智能模型应用于不可预测的开放领域场景或安全敏感的应用时,鲁棒性越来越重要。

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢