
作者: nghuyong
知乎: https://zhuanlan.zhihu.com/p/580468546
「论文」: Scaling Instruction-Finetuned Language Models
「地址」: https://arxiv.org/abs/2210.11416
「模型」: https://huggingface.co/google/flan-t5-xxl
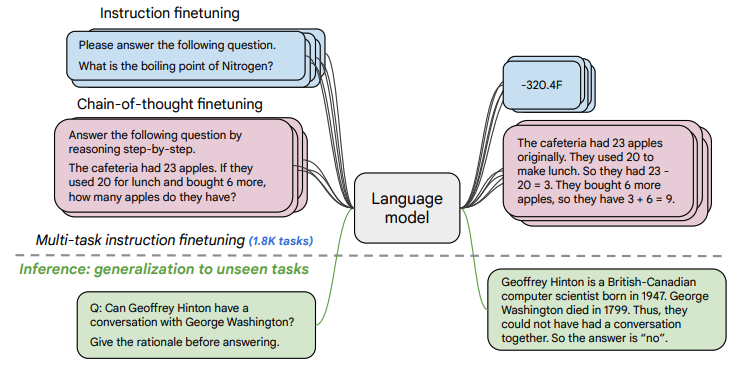
「Flan-T5」是Google最新的一篇工作,通过在超大规模的任务上进行微调,让语言模型具备了极强的泛化性能,做到单个模型就可以在1800多个NLP任务上都能有很好的表现。这意味着模型一旦训练完毕,可以直接在几乎全部的NLP任务上直接使用,实现「One model for ALL tasks」,这就非常有诱惑力!
这里的Flan指的是(Instruction finetuning),即"基于指令的微调";T5是2019年Google发布的一个语言模型了。注意这里的语言模型可以进行任意的替换(需要有Decoder部分,所以「不包括BERT这类纯Encoder语言模型」),论文的核心贡献是提出一套多任务的微调方案(Flan),来极大提升语言模型的泛化性。
Flat
例如下面文章中的例子,模型训练好之后,可直接让模型做问答:
「模型输入」是:"Geoffrey Hinton和George Washington这两个人有没有交谈过?在回答之前想一想原因。“
「模型返回」是:Geoffrey Hinton是一个计算机科学家,出生在1947年;而George Washington在1799年去世。所以这两个不可能有过交谈。所以答案时“没有”。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢