
本文旨在简要总结近期在 graph 领域新提出的数据增广方法,带领读者了解图数据增广的基本定义和最新进展。
近年来,以数据为驱动的推理在数据增广技术的引进后,泛化能力和模型性能方面得到了显着提升。数据增广技术通过创建现有数据的合理变体而无需额外的真实标签来增加训练数据量,并且已在计算机视觉 (CV) 和自然语言处理 (NLP)得到广泛应用。
而随着图神经网络等图机器学习方法的快速发展,人们对图数据增广技术(GDA)的兴趣和需求不断增加。但由于图数据的不规则和非欧结构,很难将 CV 和 NLP 中使用的数据增广技术(DA)直接应用到 graph 领域。此外,图机器学习面临着独特的挑战,例如特征数据的不完整性,幂律分布带来的结构数据稀疏性,由于人工标注的昂贵成本所导致的标记数据的缺乏,以及 GNN 中消息传递会导致的过度平滑。为了应对这些挑战,关于图数据增广的工作越来越多。
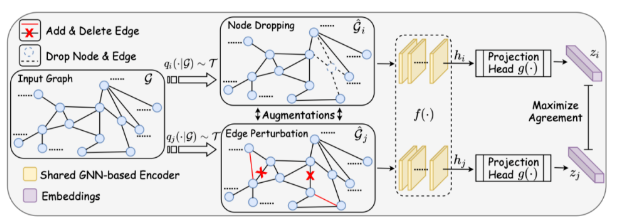
类似于 CV 和 NLP 的数据增广技术,图数据增广技术通过修改或生成来创建数据对象。然而,由于图是连接数据,与图像和文本不同,图机器学习中的数据对象通常是非独立同分布的。因此,无论是节点级和边级,抑或是图级别的任务,图数据增广技术往往会对整个图数据集做出改动。基于此,GraphCL(NIPS2020)提供了最常用的四种增广策略,分别是节点丢弃(Node Dropping),边扰动(Edge Puturbation),属性掩膜(Attribute masking)和子图采样(Subgraph Sampling)。虽然上述尝试将数据增广应用到了 Graph 中,但它们通常无法生成关于原始图语义的视图或使增广策略来适应特定的图学习任务。

下面将分别介绍近期提出的三篇工作:一种新的增广策略,一种自动选择已有增广策略的自动图对比学习方法,以及一种将元学习应用到图数据增广的可学习增广方法。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢