
作者:Zhengzhuo Xu, Ruikang Liu, Shuo Yang,等
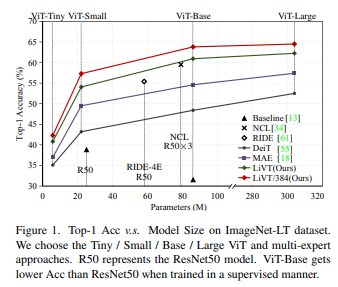
简介:本文研究基于遮罩生成预训练与平衡的二元交叉熵的视觉Transformer、实现了新SOTA的长尾识别技术。现实世界的数据往往严重不平衡、并严重扭曲数据驱动的深度神经网络,使得长尾识别 (LTR) 成为一项具有挑战性的任务。现有的 LTR 方法很少使用长尾 (LT) 数据训练 Vision Transformers (ViT),而现成的 ViT 预训练权重总是导致比较不公平。在本文中,作者系统地研究了 ViT 在 LTR 中的性能,并提出 LiVT :仅使用 LT 数据从头开始训练 ViT。通过观察 ViTs 遭受更严重的 LTR 问题,作者进行了遮罩生成预训练 (MGP) 来学习广义特征。凭借充足而确凿的证据,作者表明 MGP 比有监督的举止更稳健。此外,二元交叉熵(BCE)损失在 ViTs 中表现突出,但在 LTR 中遇到了困境。作者进一步提出Bal-BCE,以通过强大的理论基础来改善它。特别地,作者推导出 Sigmoid 的无偏扩展并补偿额外的对数余量来部署它。作者的 Bal-BCE 有助于在短短几个时期内快速收敛 ViT。广泛的实验表明:当基于MGP 和 Bal-BCE的使用 ,LiVT 在没有任何额外数据的情况下成功地训练了 ViTs、并且显着优于可比的最先进的方法。
论文下载:https://arxiv.org/pdf/2212.02015.pdf
源码下载:https://github.com/XuZhengzhuo/LiVT
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢