
作者:Qihuang Zhong,Liang Ding2,Yibing Zhan等
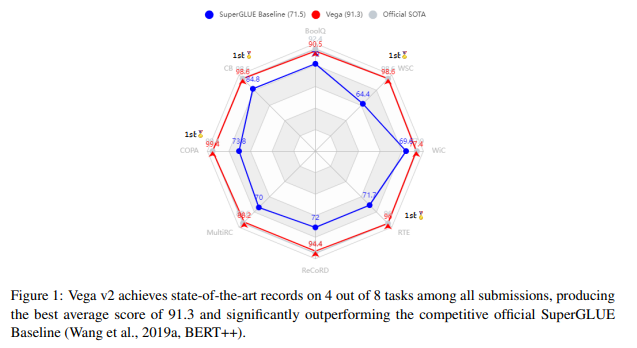
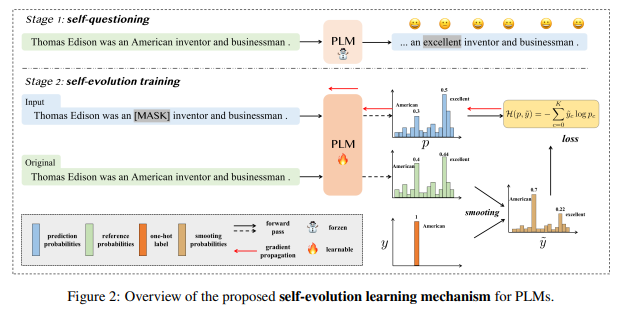
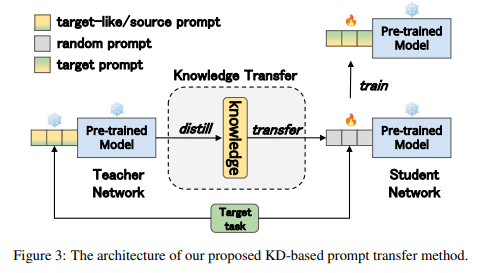
简介:本文介绍了京东探索研究院在 SuperGLUE 排行榜上提交的Vega大模型。SuperGLUE 比广泛使用的通用语言理解评估 (GLUE) 基准更具挑战性,包含八项困难的语言理解任务、比如:问答、自然语言推理、词义消歧、共指消解和推理。作者不任意增加预训练语言模型 (PLM) 的大小,而是想为达成如下两个目标:(1) 在给定特定参数预算的情况下,从输入的预训练数据中充分提取知识;(2) 有效地将这些知识转移到下游任务。为了实现目标 1,作者建议 PLM 进行自我进化学习,以明智地预测应该屏蔽的信息标记,并使用修正后的平滑标签、来监督掩码语言建模 (MLM) 过程。对于目标 2,作者利用Prompt提示迁移技术:通过将知识从基础模型和相关下游任务,迁移到目标任务、以改进低资源任务。实验表明:通过作者优化的预训练和微调策略,作者具有60亿参数的Vega模型(V2版)在四大任务上取得了新的SOTA性能,在 SuperGLUE 排行榜上名列前茅、平均分 91.3。
论文下载:https://arxiv.org/pdf/2212.01853.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢