
作者:Fangxun Shu,Biaolong Chen,Yue Liao等
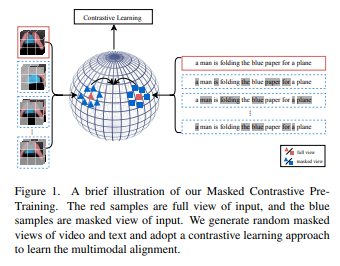
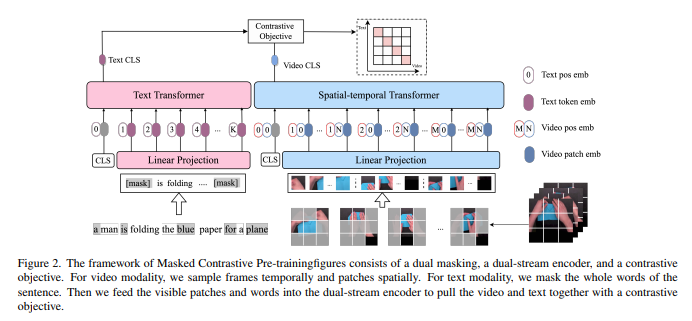
简介:本文研究端到端高效的视频文本对齐的预训练框架(VidLP) 、以用于视频文本检索任务。作者的掩码对比学习视频语言预训练模型(MAC) ,旨在通过掩码采样机制减少 VidLP 模型中视频表示的空间和时间冗余,进而实现预训练效率的提高。与传统的时间稀疏采样相比,作者建议采用随机屏蔽高比例的空间区域策略,并且仅将可见区域作为稀疏空间采样提供给编码器。同样地,作者对文本输入采用掩码采样技术以保持一致性。作者没有盲目地应用来自Masked autoencoders论文(MAE) 中的 mask-then-prediction 范式,而是提出了一种用于高效视频文本对齐的 masked-then-alignment 范式。动机是视频文本检索任务依赖于高级对齐、而不是低级重建,并且带有掩码建模的多模态对齐、鼓励模型从不完整和不稳定的输入中学习鲁棒和通用的多模态表示。综合上述设计的端到端预训练,高效地达成:减少 FLOP(减少 60%)、加速预训练(3 倍)并提高性能。作者的 MAC 在多个视频文本检索数据集上取得了SOTA结果,包括 MSR-VTT、DiDeMo 和 ActivityNet。作者的方法是兼容性的输入方式,通过最尽量少的修改、作者在图像文本检索任务上取得了有竞争力的结果。
论文下载:https://arxiv.org/pdf/2212.00986.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢