

01
研究动机
在本文中,我们研究了一种能够高效推理的机器翻译模型NAT (Non-Autoregressive Transformer)[1]。相较于传统的Transformer,NAT能够在解码阶段并行预测,从而大幅提升模型的推理速度。此外,NAT可以使得模型在训练和测试阶段从相同的分布进行预测,从而有效避免了顺序解码模型中经常出现的exposure bias问题。在WMT21 news translation shared task for German→English translation中,已经有NAT模型在翻译质量上超过了许多顺序解码的模型。
尽管NAT在拥有许多潜在的优势,目前的工作中这类模型仍然在很大程度上依赖于句子级别的知识蒸馏(sequence-level knowledge distillation, KD)[2]。由于需要并行预测所有token,NAT对单词间依赖关系的建模能力较弱。这个特点使得在真实数据集上,NAT很容易受到multi-modality问题的影响:训练数据中一个输入可能对应多个不同的输出。在这样的背景下,Gu提出训练一个AT (Autoregressive Transformer)[3]模型作为老师,将它的输出作为NAT的学习对象。这种KD方式可以帮助NAT绕过multi-modality问题,从而大幅提升NAT的翻译表现。
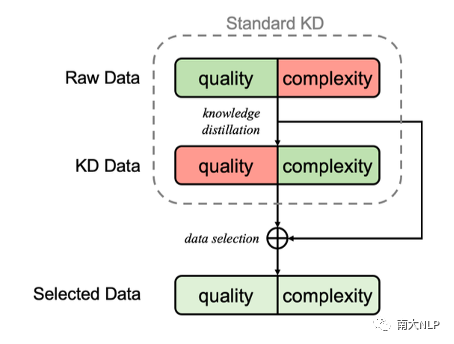
图1:Selective KD的流程示意图
KD在帮助NAT提升表现的同时,也会带来一些负面影响,例如模型在低频词上的准确率较低[4]、AT teacher的错误会传播到NAT上等。此外,如果NAT仅能在AT teacher的输出上学习,这类模型的翻译质量将很难有更进一步的突破。我们的研究希望能够在避免multi-modality的情况下,让NAT能够从真实的数据分布中学到知识蒸馏的过程中缺失的信息,从而提升NAT的表现。
为达到这样的目的,我们提出了selective KD:在KD数据上训练一个NAT作为评估模型,并通过它来选择需要蒸馏的句子。通过这种方式,我们可以让模型接触到翻译质量更高的真实数据,同时避免了严重的multi-modality情况。受课程学习的影响,我们也在训练过程中动态调整蒸馏数据的比例。“用评估模型有选择地蒸馏数据”和“动态调节蒸馏数据的比例”共同构成了我们的Selective KD训练框架。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢