
作为一种视觉预训练方法,掩码图像建模(Masked Image Modeling,简称 MIM)近期得到了蓬勃发展,自从 BEiT 开始,一系列新方法诸如 SimMIM、MAE、MVP 等被陆续设计出,这个领域也受到了很大关注。然而,在十亿参数量级别的视觉预训练模型中,最具竞争力的模型例如 ViT-g、SwinV2、CoCa 等仍然严重依赖有监督或弱监督训练,以及不可公开访问的数亿级有标签数据。
理想的视觉预训练应当只需简单的操作:譬如抓好语义学习和几何结构学习这两个关键点,基本可以搞定绝大部分的视觉任务。
智源曹越团队最新开源的视觉预训练模型 EVA,将最强语义学习(CLIP)与最强几何结构学习(MIM)结合,仅需使用标准的 ViT 模型,并将其规模扩大到十亿参数(1-Billion)进行训练,即可得到当前最强大的十亿级视觉基础模型 EVA。

具体而言,EVA 的训练方法与 MVP、MILLAN 类似,即通过重构 CLIP 特征来进行掩码图像建模(masked image modeling)。如下图所示,CLIP 模型输入为完整的图像,而 EVA 模型的输入为有遮盖的图像,训练过程是让 EVA 模型遮盖部分的输出去重构 CLIP 模型对应位置的输出,从而以简单高效的方式让 EVA 模型同时拥有了最强语义学习 CLIP 的能力和最强几何结构学习 MIM 的能力。不同于之前的方法,EVA 证明了这种训练方式可以帮助模型将参数扩展到十亿量级,并且在这个参数量级下在广泛下游任务中取得出色的性能。
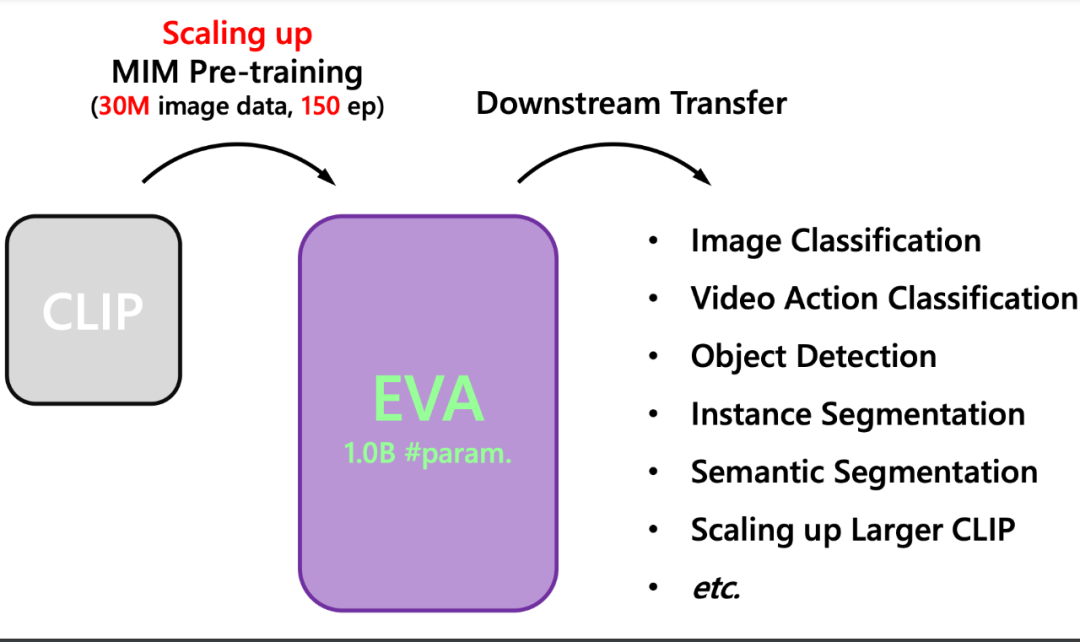
总结而言,EVA 具有以下特点:
1. 高效
EVA 仅使用开源的纯图像数据即可进行掩码预测任务,不需要预训练阶段重新学习语义以及不需要巨量的成对有标注数据。相比而言,主流标杆性模型(ViT-g、SwinV2、CoCa 等)仍依赖于冗长的有监督或弱监督训练,以及不可公开访问的数亿级有标签数据。
2. 简单
EVA 无需特殊设计网络结构。使用简单的网络结构—标准的 ViT-g,而无需额外特殊设计的算子,使得其非常容易的迁移到广泛的下游任务,并且可以和其他模态共享。
实验
目前,EVA 在主流任务评测中的表现都可圈可点:
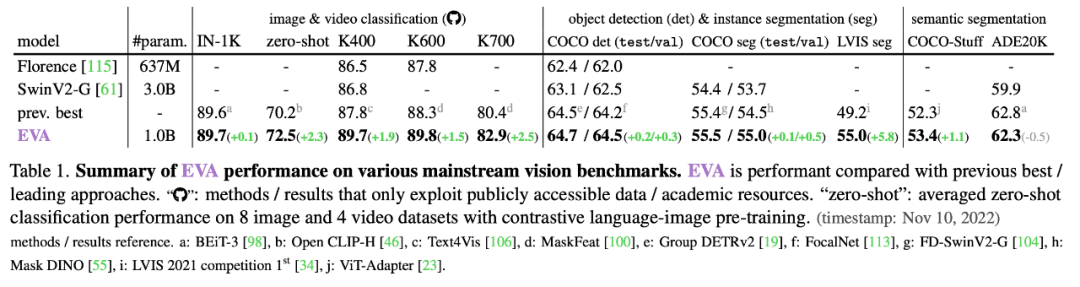
1. 多项重要视觉感知任务取得 state-of-the-art 性能
ImageNet 图像分类中取得 89.7% 的 top-1 准确率;Kinetics-700 视频动作识别取得 82.9% 的 top-1 准确率;COCO 目标检测取得 64.7 mAP、实例分割取得 55.5 mAP;LVIS 的实例分割取得 55.0 mAP;语义分割的 COCO-stuff 取得 53.4 mIoU、ADE-20K 取得 62.3 mIoU。
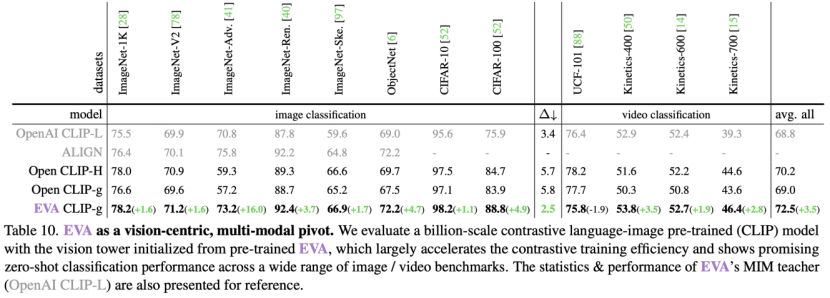
2. 参数量变引发性能质变:在 LVIS 上性能极强;可以稳定并加速 CLIP 训练,产生当前最强的开源 CLIP 模型。
首先,在 LVIS(超过一千类)实例分割任务上表现和 COCO(80 类)相仿,比之前的 SOTA 方法 MAE 高出 5.8 个点;第二,使用 EVA 作为 CLIP 训练的初始化,其性能远超随机初始化的 CLIP 训练,如下图所示,在十亿参数量级下,和 Open CLIP 官方使用完全一样的训练方式下,在几乎所有的零样本基准下均有显著的性能提升,除此之外,EVA 可以极大地稳定巨型 CLIP 的训练和优化过程,训练过程仅需使用 FP16 混合精度,综合来看,EVA 帮助训练得到当前最强且最大的开源 CLIP 模型,已经有团队在尝试使用其帮助 AIGC 模型的生成质量。
圈重点:EVA 全家桶开源!
十亿参数的预训练模型,下游 ImageNet 图像分类、Kinetics 视频动作识别、COCO 和 LVIS 目标检测和分割、ADE20K 语义分割、以及最强 CLIP 模型,全部开源!

欢迎感兴趣的小伙伴前去使用!
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢