
文档智能是知识图谱构建以及自然语言处理的一个上游任务,其目的是将文档进行标准化以及基本的富文本解析,然后送到下游进行信息抽取、检索等应用中。
在上一篇文章《PDF文档智能关键模块开源实操:PDF区域bouding box坐标识别与图片提取方法与实践》一文中,围绕PDF图片提取这一任务,从PDF区域bouding box坐标识别、PDF文件向图片转换以及PDF文件图片提取三个方面进行论述。
这是该系列的第二篇,本文将聚焦如何将PDF转换为doc文件格式这一问题,这一过程也可以称为版式复原,转换为doc格式后,可以更为方便的进行文档批注与修改等。具体的,本文将从PyMuPDF读取PDF结构、python-docx操作doc以及pdf2docx一站式pdf转doc三个部分进行介绍,供大家一起思考。
一、PyMuPDF读取PDF结构
PyMuPDF是一个用来操作PDF文档的Python包,功能比较强大,不依赖其他的Python包,除了提供方便易用的功能外,还提供了一些底层的操作方法,对于熟悉PDF文档结构的人员来说,可以使用这些底层操作函数实现大多数对PDF文档的操作。
1、实现的原理
PyMuPDF,实际上是对MuPDF工具的一个python组件封装,MuPDF是一个轻量级的PDF、XPS和电子书查看器、渲染器和工具包,由Artifex Software, Inc维护和开发,MuPDF可以访问PDF、XPS、OpenXPS、CBZ、EPUB、MOBI和FB2(电子书)格式的文件,并以其顶级性能和高渲染质量而闻名。
一页pdf由若干个带有bouding box的block构成,按照位置关系进行排列,在解析过程中,PyMuPDF通过生成Textpage对象,提供extractDICT()和extractRAWDICT()用以获取页面中的所有文本和图片(内容、位置、属性),如下图所示。
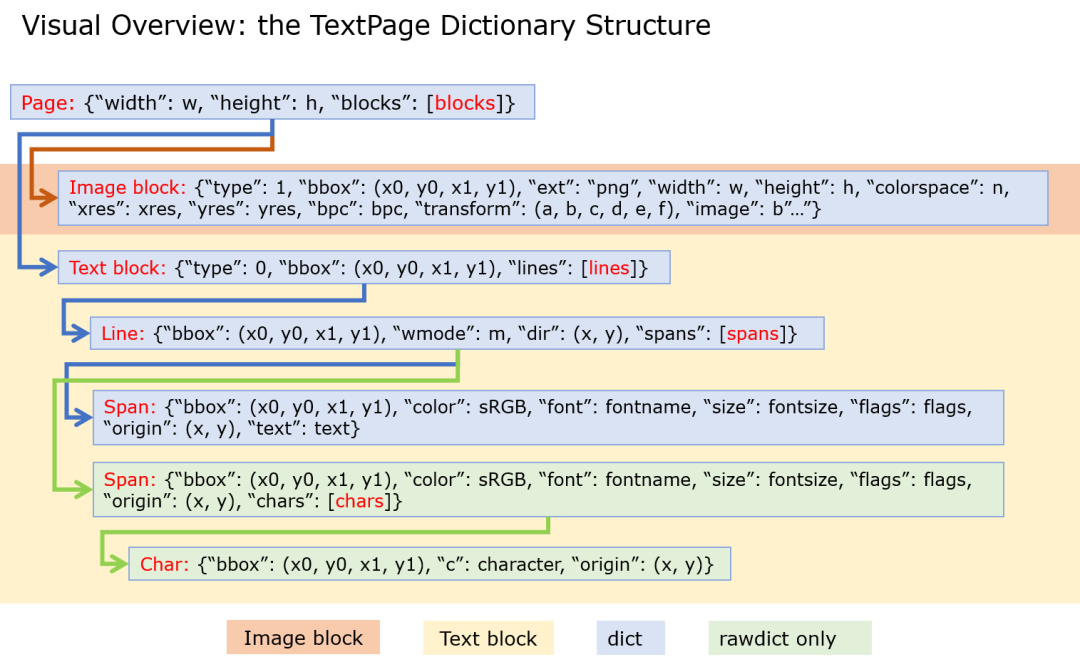
此外,pymupdf还内置了多个工具,例如,Pillow 用于图片读取与处理,fontTools用于获取字体,并使用Tesseract-OCR用于文字识别。
2、操作案例
1)读取text文本
import fitz
pdf_document = "example.pdf"
doc = fitz.open(pdf_document)
print ("number of pages: %i" % doc.pageCount)
print(doc.metadata)
page1 = doc.loadPage(0)
page1text = page1.getText("text")
print(page1text)PyMuPDF可以保持原始文档结构完整-带有换行符的整个段落都保留在PDF文档中 。
1)抽取图片
import fitz
pdf_document = fitz.open("sample.pdf")
for current_page in range(len(pdf_document)):
for image in pdf_document.getPageImageList(current_page):
xref = image[0]
pix = fitz.Pixmap(pdf_document, xref)
if pix.n < 5: # this is GRAY or RGB
pix.writePNG("page%s-%s.png" % (current_page, xref))
else: # CMYK: convert to RGB first
pix1 = fitz.Pixmap(fitz.csRGB, pix)
pix1.writePNG("page%s-%s.png" % (current_page, xref))
pix1 = None
pix = None在测试过程中,38页的pdf文件,图片分离只需要1.5s;
二、python-docx操作doc
python-docx是用于创建可修改Word的一个python库,提供全套的Word操作。
1、Doc文档的构成
一个标准的doc文档,其构成单位涉及到Document、Paragraph以及Run等多个概念。
Document,是一个Word文档对象,不同于VBA中Worksheet的概念,Document是独立的,打开不同的Word文档,就会有不同的Document对象,相互之间没有影响,如下图所示。

Paragraph表示段落,一个Word文档由多个段落组成,当在文档中输入一个回车键,就会成为新的段落,输入shift+回车,不会分段;
Run表示一个节段,每个段落由多个节段组成,一个段落中具有相同样式的连续文本,组成一个节段,所以一个段落对象有个Run列表;
而通过对各个Run列表进行属性设置,就可以得到丰富多样的doc文件。
2、实现原理
python-docx创建一篇文档,先创建一个Document()对象,分别针对Paragraph和Run进行设置。
例如,分成不同的节,也就是由sections对象控制,然后每节中又分成不同的段落paragraphs对象,每段又由不同的块run对象组成;
针对不同的节(section)可以设置页面的一些属性,针对不同的段落(paragraph),可以设置间距和缩进、换行和分页等,针对不同块(run)可以设置字体的字型、颜色、大小等。
可以先设置好整篇文章的大致段落、字体等格式,然后针对不同段落和块可以单独再进行设置。
1)创建文档
from docx import Document
from docx.shared import Inches
## 创建文档
document = Document()2)增加标题与段落
## 增加标题
document.add_heading('Document Title', 0)
## 增加段落
p = document.add_paragraph('A plain paragraph having some ')
p.add_run('bold').bold = True
p.add_run(' and some ')
p.add_run('italic.').italic = True
document.add_heading('Heading, level 1', level=1)
document.add_paragraph('Intense quote', style='Intense Quote')
document.add_paragraph(
'first item in unordered list', style='List Bullet'
)
document.add_paragraph(
'first item in ordered list', style='List Number'
)3)增加图片
document.add_picture('monty-truth.png', width=Inches(1.25))
4)增加表格
records = (
(3, '101', 'Spam'),
(7, '422', 'Eggs'),
(4, '631', 'Spam, spam, eggs, and spam')
)
table = document.add_table(rows=1, cols=3)
hdr_cells = table.rows[0].cells
hdr_cells[0].text = 'Qty'
hdr_cells[1].text = 'Id'
hdr_cells[2].text = 'Desc'
for qty, id, desc in records:
row_cells = table.add_row().cells
row_cells[0].text = str(qty)
row_cells[1].text = id
row_cells[2].text = desc5) 增加换行符并保存
document.add_page_break()
document.save('demo.docx')同样的,python-docx还支持表格提取的接口,如:
import os
from docx import Document
path = "test.docx"
doc = Document(path)
for t in doc.tables:
for row in t.rows:
row_str = []
for cell in row.cells:
row_str.append(cell.text)3、实现效果

三、pdf2docx一站式pdf转doc
知乎文章《pdf2docx简介:Python实现PDF转Word》一文中对其进行了介绍:
“PDF文档实际并不存在段落、表格的概念,PDF转Word要做的就是将PDF文档中“横、竖线条围绕着文本”解析为Word的“表格”,将“文本及下方的一条横线”解析为“文本下划线”,等等,具体实现离不开对PDF文档的版式分析,或者基于传统的文档元素位置和内容分析,或者机器学习/计算机视觉方法训练模型(尤其是针对扫描的PDF文档)。
pdf2docx是pdf转docx的一个具有代表性的开源工具。
1、实现思路
从技术实现上来说,PDF转Word是一个古老的话题,其难点在于建立从PDF基于元素位置的格式到Word基于内容的格式的映射。
pdf2docx借助PyMuPDF从PDF提取文本、图片和形状数据,它们构成了pdf2docx的两类基础数据,pdf2docx首先利用PyMuPDF获取页面元素,例如文本和形状及其位置;其次,利用元素间的相对位置关系解析页面;然后使用python-docx将上一步解析的内容元素重建为docx格式的Word文档。
2、具体实践:
import os
from pdf2docx import Converter
def pdf_to_doc(pdf_file):
docx_file = ".".join(pdf_file.split(".")[:-1]) + ".docx"
cv = Converter(pdf_file)
cv.convert(docx_file) # 默认参数start=0, end=None
cv.close()
if __name__ == "__main__":
filepath = "test".pdf" #存在图表识别错误的情况,
pdf_to_doc(filepath)此外,pdf2docx还提供了表格信息提取方法。
from pdf2docx import Converter
pdf_file = 'test.pdf'
cv = Converter(pdf_file)
tables = cv.extract_tables(start=0, end=1)
cv.close()
for table in tables:
print(table)3、实现效果:
我们以一个38页的研报进行测试,研报中所包含的样式和色彩较为丰富多彩。
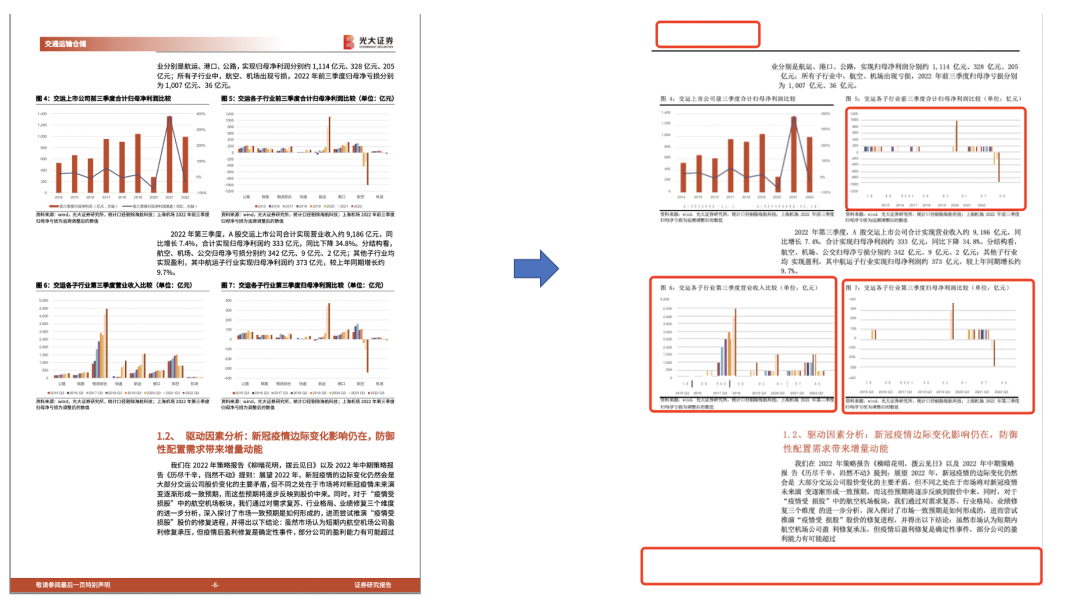
从中,我们可以看到,pdf中的图表转化的结果中会出现一些数据丢失和不配的情况,如图中圈红的部分,下图则展示了表格的转换效果,看起来还可以。
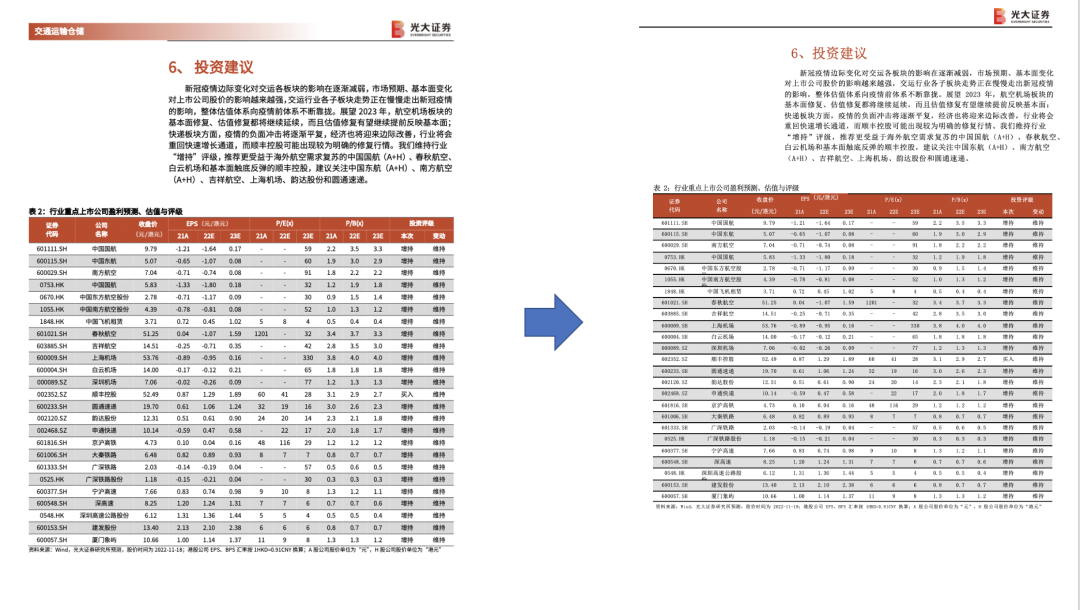
此外,pdf2docx在处理速度上并不是很快,38页转换完后,花费192.65s,平均5.06s/页,而且,pdf2docx通过PyMuPDF获取页面元素进行重构,而PyMuPDF无法处理PDF扫描件,根据有限的、确定的规则建立PDF与docx元素之间的映射并非完全可靠,也就是说仅能处理常见的、规范的格式,而非百分百还原。
总结
本文主要聚焦如何将PDF转换为doc文件格式这一问题,从PyMuPDF读取PDF结构、python-docx操作doc以及pdf2docx一站式pdf转doc三个部分进行介绍,供大家一起思考。
当然,对于PDF进行最根本的认识,可能这个系列最为基础的工作,感兴趣的朋友可以多加思考。
参考文献
1、https://zhuanlan.zhihu.com/p/352197656
2、https://www.jianshu.com/p/8fbb662bd6f7
3、https://www.yht7.com/news/188378
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢