
大家好,今天给大家带来的外文精品博客是关于模型量化技术。在神经网络中,量化可以理解为用低精度的数据格式来表示原来用高精度的数据格式表示的模型,从而降低内存使用以及提高计算速度。该博客不仅介绍了常用的量化策略,还分享了作者提出的基于混合精度分解的量化方法,并通过对比实验验证了混合精度分解量化可以有效地保持模型性能。此外,该博客还分享了Transformer模型中Emergent Features(离群值)会在很大程度上影响量化性能的有趣现象,并分析了Emergent Features的分布规律和Emergent Features如何在模型中去除无用特征,以及使得模型的各个层相互配合的个人理解和看法。
02
作者介绍

Tim Dettmers 华盛顿大学博士。研究方向为表示学习、神经科学启发的深度学习和深度学习的硬件优化。
03
译者说
由于量化用更少的比特数来表示模型,因此可以降低内存占用。另外由于低精度的指令运算的时钟周期要短于高精度的指令,因此量化通常可以提升推理速度。这在繁重的机器翻译模型的部署中能够起到重要作用。但是低精度运算的一大弊端就是会带来误差,这也成为了我们使用量化技术的一个障碍。随着机器翻译模型参数量的增大,误差累积会越来越大,使用量化技术进行模型部署也变得愈发困难。如何减少量化带来的模型性能损失是目前研究的热点。
该博客分享了Transformer模型中对量化影响很大的离群值的一些分布规律,并提出了混合精度分解的量化策略,避免了在大模型上使用量化技术导致的性能下降。然而,该量化策略的推理速度比较慢,这成为了使用量化技术新的瓶颈。
除了量化之外,该博客也帮助我们从另一个角度来理解Transformer:通过对Emergent Features的分析,解释了Transformer是如何通过这些离群值来去除无用特征,以及Transformer的每一层是如何进行协作的。基于博客对Emergent Features的分析,我们可以得到这样一些启发:由于Emergent Features的phase shift发生在模型参数达到6.7B时,这启示我们模型在参数量6.7B前后的表现非常不一致。在小模型上有效的方法,在参数量达到6.7B的模型上不一定能有相同的效果。然而,我们可以通过在几个参数量不同的小模型上进行实验分析Emergent Features与我们关心的属性的关系,从而得知Emergent Features的phase shift是否会影响方法在大模型上的效果。本博客是作者对于其论文 《LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale》的补充,这里是原论文链接 (opens new window)。
04
原博客精华内容概括
4.1.1 什么是量化
举例来说,假设我们有分别有数据类型I5和数据类型I3,I5可以表示的数值为[0, 1, 2, 3, 4, 5],I3可以表示的数值为[0, 2, 4]。通过以下两个步骤将数据类型从I5转换为I3:
1)将数据范围从I5标准化为I3;
2)用I3中最接近的数值表示原始数据 。
例如,我们将使用数据类型I5表示的向量[3, 1, 2, 3]量化到数据类型I3的过程如下:
1)找到向量[3, 1, 2, 3]的最大的绝对值->3;
2)向量[3, 1, 2, 3]除以最大值3:[3, 1, 2, 3]->[1, 0.33, 0.66, 1.0];
3)将向量[1, 0.33, 0.66, 1.0]与I3的数据范围4相乘:[1, 0.33, 0.66, 1.0]->[4.0, 1.33, 2.66, 4.0];
4)将向量[4.0, 1.33, 2.66, 4.0]中的每个值用I3中最接近的数值表示:[4.0, 1.33, 2.66, 4.0] -> [4, 0, 2, 4]。
这样,我们就将I5类型表示的[3, 1, 2, 4]量化到了I3类型表示的[4, 0, 2, 4]。
反量化的步骤如下:
1)[4, 0, 2, 4]除以4->[1.0, 0.0, 0.5, 1.0];
2)乘以量化过程中找到的最大的绝对值:[1.0, 0.0, 0.5, 1.0] -> [3.0, 0.0, 1.5, 3.0];
3)近似表示:[3.0, 0.0, 1.5, 3.0] -> [3, 0, 2, 3]。
经过量化、反量化,原来的[3, 1, 2, 3]变成了[3, 0, 2, 3],产生了量化误差。这样的误差在模型中传播、积累,最终会影响模型性能。
4.1.2 如何使量化更精确
原博客认为,提高量化精度的最佳方法是使用更多的量化参数。例如,我们有一个二维的张量:[[3, 1, 2, 3], [0, 1, 1, 0]]。如果分别为[3, 1, 2, 3]和[0, 1, 1, 0]设置独立的量化参数为各自的最大的绝对值3和1,量化的精度会比为整个[[3, 1, 2, 3], [0, 2, 2, 0]]只设置一个量化参数3更高。
4.1.3 Vector-wise量化
矩阵乘法A*B可以看成矩阵A的每一行和矩阵B的每一列独立地做内积。为这些独立的行、列向量设置各自的scaling constant就是vector-wise量化。这种量化方式引入了更多的量化参数,量化的结果也更加精确。
4.1.4 混合精度分解
Transformer的hidden state中存在一些绝对值很大的离群值,原博客将这些值称为Emergent Features。我们可以通过一个例子来说明这样的特征会对量化造成什么影响。
假设hidden state中有一个向量A=[-0.10, -0.23, 0.08, -0.38, -0.28, -0.29, -2.11, 0.34, -0.53, -67.0]。向量A有一个emergent feature -67.0。如果我们去掉emergent feature -67.0对向量A做量化和反量化,处理后的结果是:[-0.10, -0.23, 0.08, -0.38, -0.28, -0.28, -2.11, 0.33, -0.53]。出现的误差只有-0.29 -> -0.28。但是如果我们在保留emergent feature -67.0的情况下对该向量做量化和反量化,处理后的结果是:[ -0.00, -0.00, 0.00, -0.53, -0.53, -0.53, -2.11, 0.53, -0.53, -67.00]。大部分信息在处理后都丢失了。
原博客中提到,平均来说,没有Emergent Features的向量在处理后平均误差为0.015,而例子中的向量在保留Emergent Features的情况下,处理后误差为0.12。保留Emergent Features对模型中的多个层进行处理,最终的结果是模型中所有有用的信息都变成了噪声。更严重的问题是,对于参数量达到6.7亿的模型来说,75%的句子都会受此影响。
幸运的是,Emergent Features的分布是有规律的。原博客中提到,对于一个参数量为6.7亿的transformer模型来说,每个句子的表示中会有150000个Emergent Features,但这些Emergent Features只分布在6个维度中。
基于此,原博客提出了混合精度分解的量化方法:将包含了Emergent Features的几个维度从矩阵中分离出来,对其做高精度的矩阵乘法;其余部分进行量化。如图所示。

4.1.5实验结果
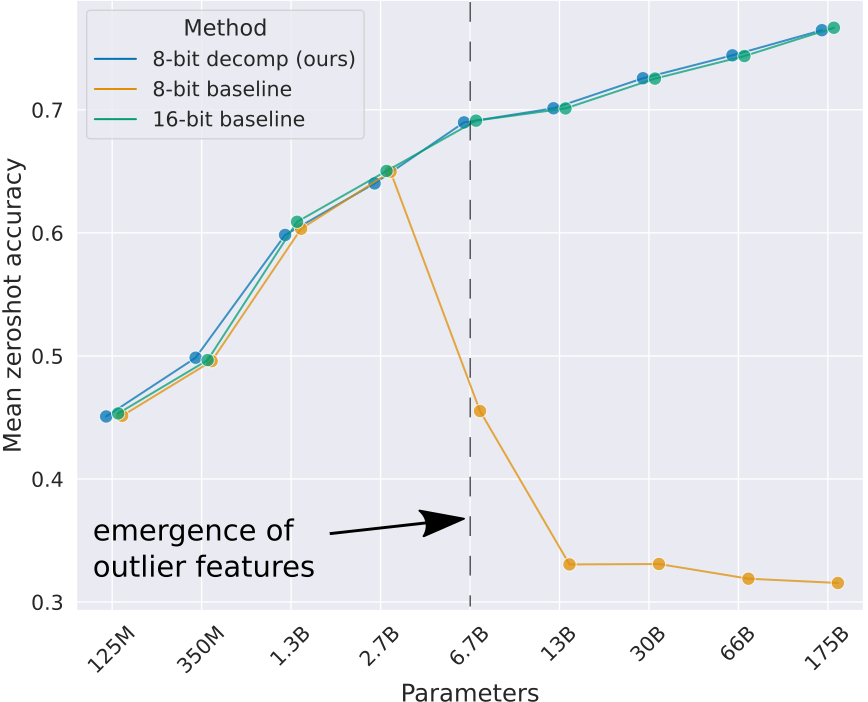
原博客将vector-wise量化与混合精度分解结合,实现了一种称为LLM.int8()的量化方法。如图所示,为原博客的对比实验。可以看到,在模型参数量达到6.7亿时,使用vector-wise方法进行量化会使模型性能有非常大的下降,而使用LLM.int8()方法进行量化则不会造成模型性能的下降。
原博客中提到了Emergent Features这个概念,Emergent Features可以理解为模型中的离群值,“Emergent”描述的是这些离群值逐渐增长,并在经历phase shift之后,对模型性能产生严重影响的现象。phase shift是指,离群值会突然迅速增长的现象。此处的增长是指:离群值的数值变大,数量变多,受该离群值影响的token数和模型层数变多。原博客总结了原论文中报告的关于Emergent Features的几个现象:
1)Emergent Features是随着ppl指数增长的,与模型大小无关;
2)在发生phase shift之后,离群值开始迅速增长;
3)Emergent Features的数量与ppl正相关。
除此之外,原博客还分享了一些没有在论文中描述的现象:
4.2.1 Emergent Features的作用
原博客认为,Emergent Features的作用是使模型的各个层互相协作地去除无关紧要的特征。
举例来说,我们有一个这样的hidden,第2列为Emergent Features:
[0, 1, -60, 4]
[3, 0, -50, -2]
[-1, 0, -55, 1]
[3, 2, -60, 1]
如果我们想要去除第0列和第3列的特征,那么只要将hidden与一个这样的矩阵做矩阵乘法:
[-1, -1, -1, -1]
[-1, -1, -1, -1]
[ 1, -1, -1, 1]
[-1, -1, -1, -1]
在对矩阵乘结果进行softmax之后,我们得到:
[0, 0.5, 0.5, 0]
[0, 0.5, 0.5, 0]
[0, 0.5, 0.5, 0]
[0, 0.5, 0.5, 0]
从而将第0列和第3列的特征去除了。
原博客分享了一个比较有意思的现象:在模型参数达到6.7亿之后,模型每一层的Emergent Features都在同一个维度出现,原博客认为这种一致性在一定程度上代表了模型各个层的协作。
4.2.2 Emergent Features的增长过程
原博客在本节中介绍了Emergent Features随着模型参数量的增加而增长的过程。
即使在参数量为125M的比较小的Transformer模型中,Emergent Features也是存在的。但此时Emergent Features只存在与attention projection的输出中。
当Transformer模型的参数量提高到350M至1.3亿,Emergent Features开始出现在attention和FFN的输出中,同时,Emergent Features分布开始呈现一些规律,Emergent outlier features开始在出现在同一个维度上,但在不同的mini-batch或者不同层中出现的位置是不一样的。
当模型的参数量达到2.7B至6B时,在60%的层中,Emergent Features出现在同样的维度上。
而当参数量达到6.7B,Emergent Features出现phase shift。在模型的所有层中,Emergent Features都出现在同样的维度上。原博客还描述了在这种情况下,模型内出现的一些变化:
1)Emergent Features快速地变得非常大。在参数量为6B的模型中,离群值的大小约为15;而当模型的参数量达到13B时,离群值的大小快速地增长到约为60。当模型参数量达到66B时,离群值的大小约为95——这说明离群值大小的快速增长是一种暂时性的现象;
2)注意力层变得非常稀疏;
3)FFN层变得更密集;
4)Transformer变得更稳定。如果将离群值从模型中分离出来,剩下的部分可以用8-bit甚至更低的精度进行运算。
4.3.1 两种transformer
由于Emergent Features的phase shift出现在模型参数量达到6.7B时,这说明参数量在6.7B之前和在6.7B之后的模型表现非常不一样。因此,将参数量在6.7B之下的transformer模型上适用的方法泛化到参数量在6.7B以上的模型时要十分谨慎。
但是,我们可以通过下面的方式来避免从头训练一个参数量达到6.7B的模型:训练多个参数量不同的模型,在这些模型中收集Emergent Features的变化和我们关心的属性的变化。当我们将这些数据聚集到一起时,我们就可以观察到Emergent Features的变化如何影响我们关心的属性,从而决定是否可以将在小模型上有效的方法泛化到参数量在6.7B之上的模型中。
4.3.2 发现新的Emergent属性
由于Emergent Features在小模型中也能够观测到。那么,这可能意味着,在现有的预训练模型中,可能可以观测到参数量达到175B的模型的一些除了离群值之外的emergent属性。并尝试找到这些emergent属性与模型性能的关系。
详细精彩内容请参见原文。
原文链接:
https://timdettmers.com/2022/08/17/llm-int8-and-emergent-features/
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢