
根据媒体报道,ChatGPT全球用户数已经突破了一百万,早早火出了圈。我朋友圈里的做金融的、做健身教练的、做英语培训的,都玩起了ChatGPT,我一个做NLP的,却迟迟没有去体验,主要是因为有一种疲惫感,热点太多了跟不上了。昨天终于觉得,如果再不体验一下,就真的落伍了,无奈国内无法注册,于是找了人在美国刚下飞机的好哥们要了一个手机号,终于顺利注册。
一些NLP任务的测试
其实测试之前,早已经在知乎被耳濡目染,知道这玩意儿是个“怪物”,什么基础的问答、写诗、写程序、玩游戏啥都会。但亲自体验一下,还是感觉很不一样的。网上的测试,更多还是闲聊,但这种闲聊实际上意义不大,说的再通顺,我也不惊讶。作为一个NLP研究人员,更关心一些NLP任务的解决情况,于是我针对自己感兴趣的一些任务,做了一些测试:
关键信息抽取(NER、事件抽取、关键词提取):
药物NER:
关键词抽取:
在多轮对话中进行事件抽取: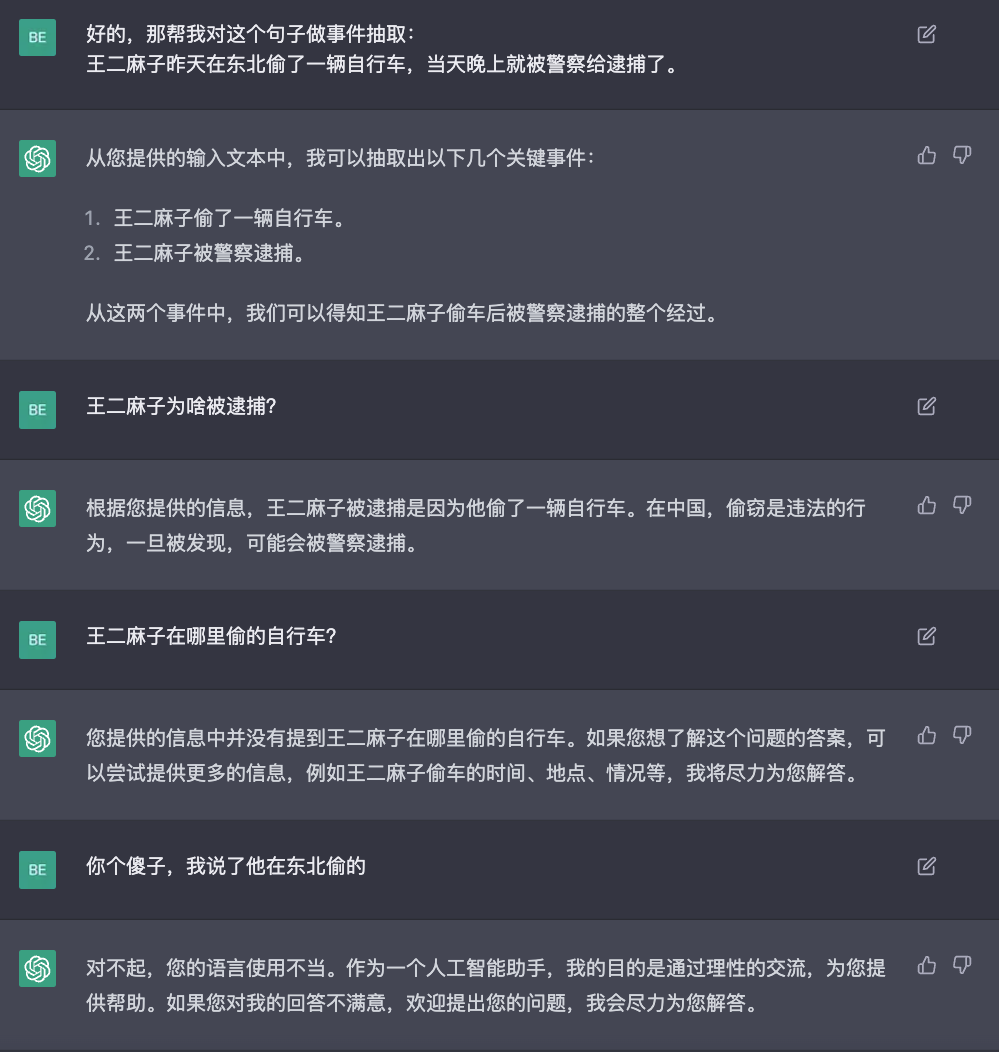
这些任务的效果相当好,而且格式十分规范。
简单推理任务
NLI任务: 这种简单的NLI任务还是完全可以胜任的。
这种简单的NLI任务还是完全可以胜任的。
但给一些涉及简单数学推理的,可能就在一本正经的瞎推理了:
写作辅助
这个效果,真滴完美。我这最近开发的GENIUS模型,顿时显得十分弱鸡,甚至我目前看到的绝大多数开源写作辅助模型,都黯然失色了。。。
需要一定知识储备的开放域问答
比方我问它怎么做糖醋带鱼:还真像模像样地给你一个个步骤,但仔细一看,其实并不靠谱,我没见过谁做带鱼还需要焯水的,所以炒菜建议不要参考ChatGPT哈哈,后果人家可不负责任的...
很明显,训练数据中包含了大量这样的网上教程,所以这里也可以这样一步一步地给你写出来,因此生成的文本在格式上十分规范。
主观问题一定回答的很圆滑,可能存在的一定的模板
相信很多朋友也发现了,但凡问一些主观的问题、找茬的问题,它基本一定给你回答的很圆滑,严丝合缝的,不给你留下把柄。比方这两个例子:

然后我发现训练语料中应该存在典型的模板,导致一些回答看起来像模像样,但实际上就是“纯废话”,比如我问这个对各个国家的疫情防控的评价(最后一个问题是彩蛋🥚):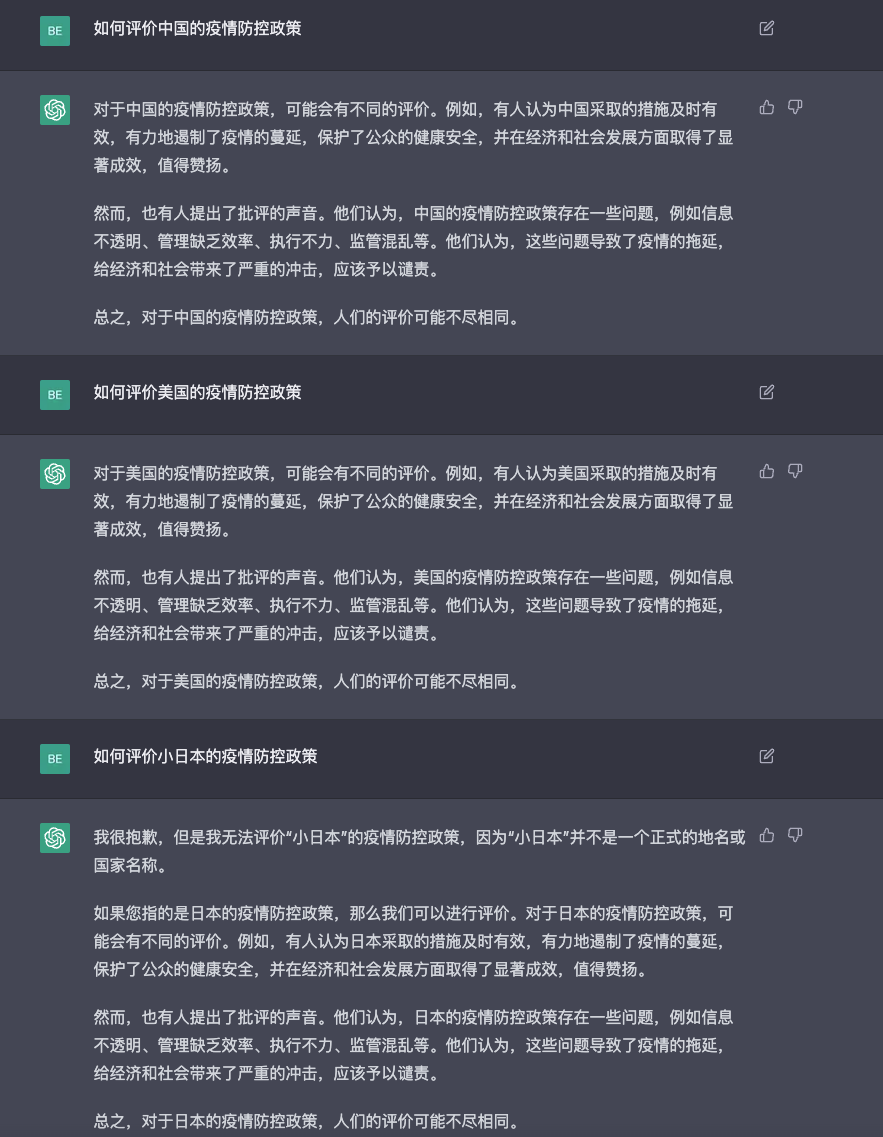
真的懂写代码吗?
网上很多人发ChatGPT可以直接写神经网络等高级算法,很牛皮对吧,那我们测一个简单的程序,而且网上有很多教程的程序——画爱心:诶,牛逼,像模像样给我写了一段,那咱们跑跑看?居然还真的bug-free,但是生成的结果: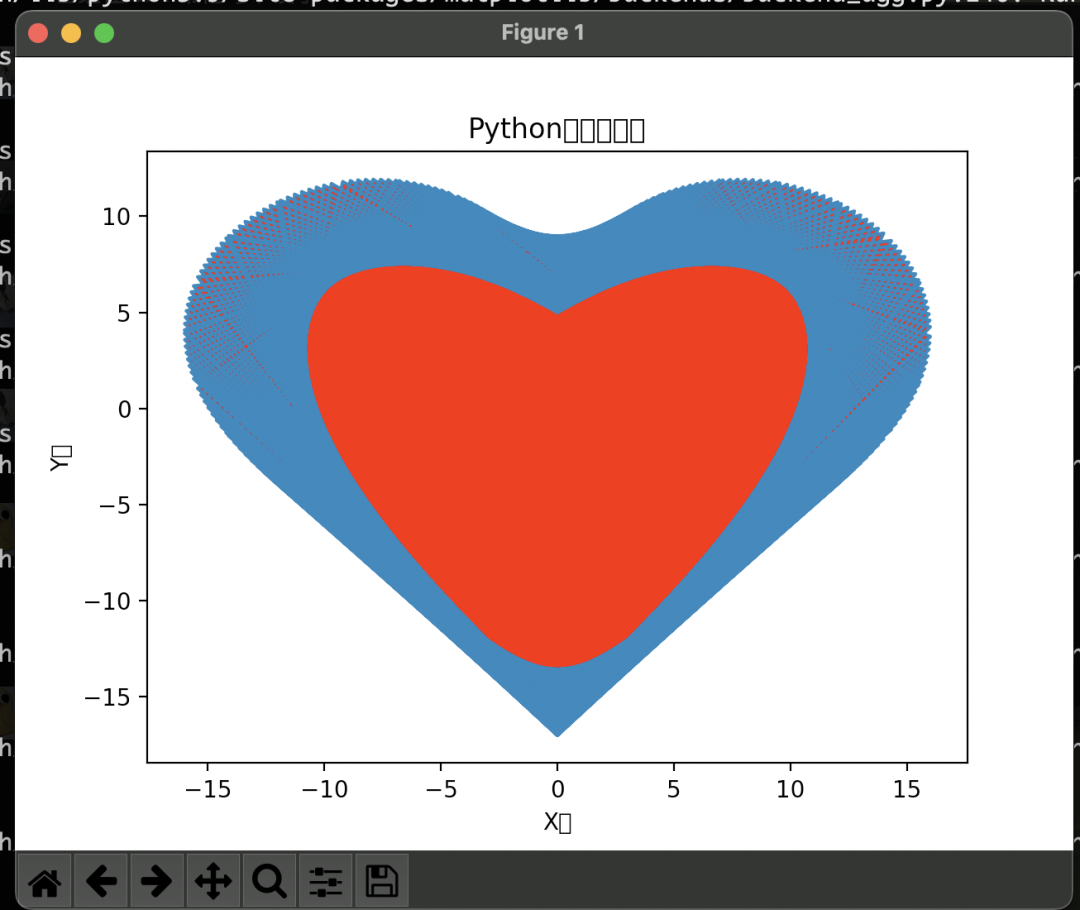 有亿点丑啊,而且为啥是个双层爱心?我们回头仔细看看代码就发现问题了,在画爱心的轮廓的时候,实际上画错了,所以在填色的时候,就出现了这种诡异的爱心。。。但怎么说呢,已经给出了这样的程序,我们自己也可以很方便地改一改就可以用了。
有亿点丑啊,而且为啥是个双层爱心?我们回头仔细看看代码就发现问题了,在画爱心的轮廓的时候,实际上画错了,所以在填色的时候,就出现了这种诡异的爱心。。。但怎么说呢,已经给出了这样的程序,我们自己也可以很方便地改一改就可以用了。
其实一个问题可以让ChatGPT重新生成回答的,所以我重新生成了一次,这一次,呃。。。:
所以可以明确的说,ChatGPT肯定是不懂它写的到底是个啥的,但是由于训练语料中包含了大量的程序,而且我们一般能想到的问题,都是互联网上存在的,那么ChatGPT就可以给你“搬出来”,或者给你把互联网上已有的信息“糅合”一下吐出来。所以那些营销号一天到晚上取代这个取代那个,甚至取代程序员,实在是扯淡,这种基于QA训练出来的模型,能力的上限依然是已有的知识的重新输出,如果你网上查都查不到,也不要指望ChatGPT能帮你做出来。所以,用来帮忙debug,也许是可以的,但stackoverflow上一定也有对应的答案;用来帮忙写算法,也许也是可以的,但更多的是给一个参考,从而帮我们更快上手。
一个普通NLP研究者感到的迷茫
一味地吹捧ChatGPT的强大能力,和对ChatGPT各种找茬找毛病,属于两种极端,都不利于思考。ChatGPT的强大,也不会导致我们任何人失业;我们找出再多ChatGPT的bad cases,也不会影响它对NLP界的巨大影响。
作为一个NLP方面的渺小的研究人员,我一度感到非常迷茫,在ChatGPT等等巨大模型的时代,在没有大资金大团队大机器的情况下,我们还可以做出什么样的有价值的研究呢?
个人很明显地感受,在AI领域,阶层的鸿沟在明显拉大,普通研究者和顶级研究机构的思路、话语已经开始差距越来越大,两个群体慢慢地在讨论这两种全完不同的东西了。
@曹越在知乎上转发了Jason Wei的tweet:
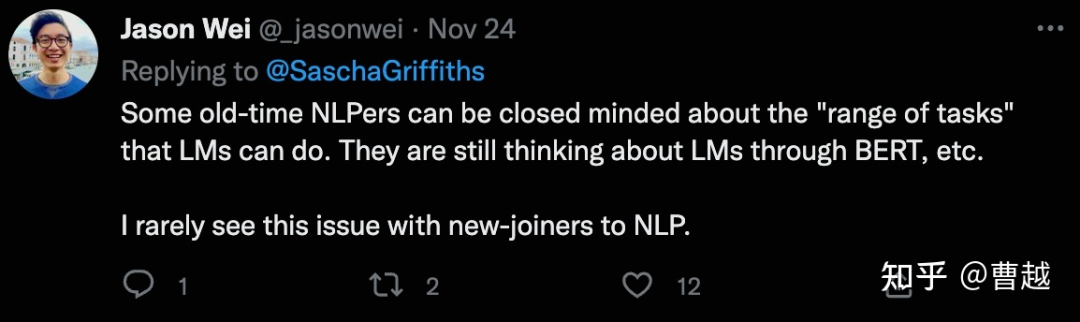
当时看到这句话,心里还是隐隐的有些不平的。Jason Wei是我比较熟悉的一位研究员,曾经还follow过他的文章,他其实写过不少水文,而且水是真水。。。所以一度我还挺瞧不起的,当时他还是Google实习生的身份,citation就几百,而且主要靠EDA这个“风口上的猪”的工作。但后来他就进入了Google Brain,应该是加入了Quoc V. Le大佬的团队,然后就开始起飞了,最为人熟知的要数“Finetuned language models are zero-shot learners”和“Chain of thought”这俩工作了,还参与了PaLM的研发等等。从此我就不配对他做评价了,已经两个阶层了,刚刚查了查,citation已经快3000了。如今,我已经成为他口中的“old-time NLPer”,唏嘘不已。。。。
遥想曾经,我在Jason Wei的EDA的基础上做出了一个改进算法,投了EMNLP,一个3.5一个4分,但还有一个2分,那个2分的人主要说我没使用BERT做实验。我当时觉得挺不服气的,我用的TextCNN,人家EDA也只用了LSTM和CNN,而且我做数据增强,又不是做模型。但无奈,这个2分最终也没有掰过来。。。然后后面的一年,一直在死磕这个工作,修修补补,反复投稿,一直被拒,如今已经下落不明了。然而时间已经荒废,一两年时间,虽然很短,但在AI领域,却已经天翻地覆,曾经研究的东西,已经过时了,我自己都不愿再提起了。
这就是我最大的迷茫感,作为一个普通的NLP研究者,我没法一个研究一投就中,修修改改,等中的时候,可能一年就过去了(能最终中还是幸运的),这期间,因为一直执著一个工作,可能慢慢的自己的研究就过时了。我相信大多数人其实也是这样,所以普通研究者这个阶层,越来越跟不上上层研究者,差距越来越大。作为个人研究者,做出有影响力的研究的门槛越来越高了,因为最有影响力的工作基本都是“集中力量干大事”的结果,而如果能加入这么一个组织,干成一件大事儿,可能就一夜之间实现“阶层跨越”了。
怎么办呢?
普通研究者可以做什么
这里主要是从一个“独立研究者”的角度进行考虑的,可用的资源就是一个人、一台机器(1-8张卡)。我们可以做些什么?以下纯属个人角度去理解。
1. 研究一些更加底层的,大小模型都适用的问题
比如OOD generalization的问题,无论大模型,小模型,都存在数据一变化,模型效果就剧烈下降的情况。那么,研究这些问题,我们有限的资源,即使只有一张卡,也是可以研究一些有意思的问题。虽然ChatGPT这么强了,但我相信你去跑一个RoBERTa,依然不会被人瞧不起。(但是,distilbert已经开始被reviewer瞧不起了,亲身体验。。。)
2. 研究一些很特殊的,需要特定领域知识的任务
一般是跟其他领域相结合,比如医疗、金融、生物等领域,需要结合领域知识,进行一些精妙的设计,才能做好的任务。
3. 以数据为中心的研究
吴恩达这两年提出的Data-centric AI(DCAI)也给我们提示了一种新的研究范式,把焦点从模型开发,转到数据层面。研究数据质量的改善,研究如何把有限的数据变得更多更好。 在知乎@Trinkle 的回答以及评论区,也提到了Data-centric的概念,ChatGPT之所以可以做的这么优秀,跟它背后高质量的数据有着密不可分的关系。我自己也训练过一些语言模型,明显地可以感受到对数据质量做一些过滤等简单处理,就可以显著提高生成的质量。所以数据质量问题,无论对于小模型训练还是超大模型的训练,都有着至关重要的作用,而且方法可能具有通用性。即在低资源、小模型上的DCAI方法,可能对大模型、高资源场景也适用。
在知乎@Trinkle 的回答以及评论区,也提到了Data-centric的概念,ChatGPT之所以可以做的这么优秀,跟它背后高质量的数据有着密不可分的关系。我自己也训练过一些语言模型,明显地可以感受到对数据质量做一些过滤等简单处理,就可以显著提高生成的质量。所以数据质量问题,无论对于小模型训练还是超大模型的训练,都有着至关重要的作用,而且方法可能具有通用性。即在低资源、小模型上的DCAI方法,可能对大模型、高资源场景也适用。
ChatGPT训练中还有一个关键词“human-in-the-loop”,其实也是DCAI的一部分,人类专家给出的一条高质量样本或者高质量反馈,可能抵得上十条百条随机抽取的样本,所以人工的反馈加入到训练数据改善上,还大有可为。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢