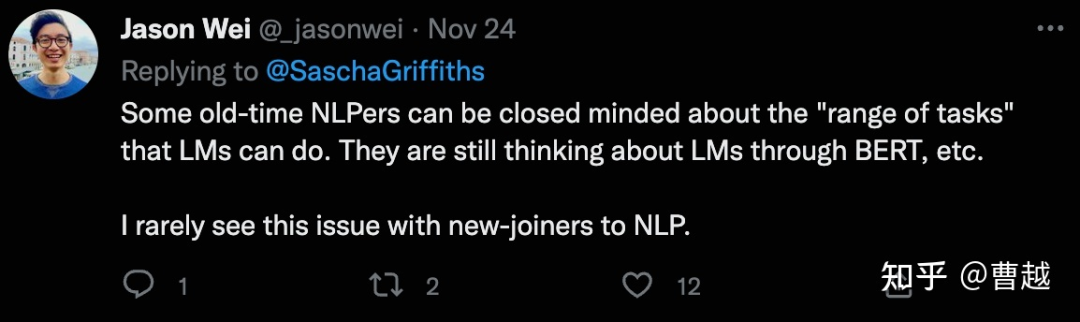
一味地吹捧ChatGPT的强大能力,和对ChatGPT各种找茬找毛病,属于两种极端,都不利于思考。ChatGPT的强大,也不会导致我们任何人失业;我们找出再多ChatGPT的bad cases,也不会影响它对NLP界的巨大影响。作为一个NLP方面的渺小的研究人员,我一度感到非常迷茫,在ChatGPT等等巨大模型的时代,在没有大资金大团队大机器的情况下,我们还可以做出什么样的有价值的研究呢?个人很明显地感受,在AI领域,阶层的鸿沟在明显拉大,普通研究者和顶级研究机构的思路、话语已经开始差距越来越大,两个群体慢慢地在讨论这两种全完不同的东西了。@曹越在知乎上转发了Jason Wei的tweet:当时看到这句话,心里还是隐隐的有些不平的。Jason Wei是我比较熟悉的一位研究员,曾经还follow过他的文章,他其实写过不少水文,而且水是真水。。。所以一度我还挺瞧不起的,当时他还是Google实习生的身份,citation就几百,而且主要靠EDA这个“风口上的猪”的工作。但后来他就进入了Google Brain,应该是加入了Quoc V. Le大佬的团队,然后就开始起飞了,最为人熟知的要数“Finetuned language models are zero-shot learners”和“Chain of thought”这俩工作了,还参与了PaLM的研发等等。从此我就不配对他做评价了,已经两个阶层了,刚刚查了查,citation已经快3000了。如今,我已经成为他口中的“old-time NLPer”,唏嘘不已。。。。遥想曾经,我在Jason Wei的EDA的基础上做出了一个改进算法,投了EMNLP,一个3.5一个4分,但还有一个2分,那个2分的人主要说我没使用BERT做实验。我当时觉得挺不服气的,我用的TextCNN,人家EDA也只用了LSTM和CNN,而且我做数据增强,又不是做模型。但无奈,这个2分最终也没有掰过来。。。然后后面的一年,一直在死磕这个工作,修修补补,反复投稿,一直被拒,如今已经下落不明了。然而时间已经荒废,一两年时间,虽然很短,但在AI领域,却已经天翻地覆,曾经研究的东西,已经过时了,我自己都不愿再提起了。这就是我最大的迷茫感,作为一个普通的NLP研究者,我没法一个研究一投就中,修修改改,等中的时候,可能一年就过去了(能最终中还是幸运的),这期间,因为一直执著一个工作,可能慢慢的自己的研究就过时了。我相信大多数人其实也是这样,所以普通研究者这个阶层,越来越跟不上上层研究者,差距越来越大。作为个人研究者,做出有影响力的研究的门槛越来越高了,因为最有影响力的工作基本都是“集中力量干大事”的结果,而如果能加入这么一个组织,干成一件大事儿,可能就一夜之间实现“阶层跨越”了。怎么办呢?











评论
沙发等你来抢