本文简要介绍ECCV 2022录用论文“OCR-free Document Understanding Transformer”。以往文档理解算法大多依赖于已有的OCR结果,而OCR引擎额外开销大、泛化性能不佳、错误累积等问题往往会对文档理解模块的性能造成影响。本文针对这些问题,提出了一个无需依赖OCR的大规模预训练文档理解模型Donut,该模型在常用数据集上有着不错的表现,且具有较快的推理速度。本文还提供了一种多语言、多版式的文档数据合成器,用于辅助模型的预训练过程。代码开源地址为https://github.com/clovaai/donut。
视觉文档理解(VDU)技术旨在从文档图像中提归纳、整理、取出有用的信息,该技术在日常生活中有着非常广泛的应用,同时也是一个具有挑战性的课题。其具体任务包括文档分类、信息提取和视觉问题回答等。现有的大部分VDU模型[1][2][3][4][5]一般使用两阶段方案来解决这一问题:1)从文档图像中读取文本;2)对文档文本进行全面的理解。它们通常依赖于光学字符识别(OCR)引擎进行第一步的文本读取,自身则着重于第二步文本理解部分的建模。然而,这些依赖于OCR的方法存在一些问题:一是OCR会带来额外的开销。虽然我们可以利用现成的OCR引擎,但其推理所需的额外时间是不可忽略的;此外,现有的OCR引擎缺乏处理不同语言或版式的灵活性,泛化能力差;再有,训练一个性能优异的OCR模型也需要耗费大量的资源。第二个问题是OCR的误差累积会影响后续流程,对于一些字符集较为复杂的语言,例如韩文或中文,OCR的效果往往较差,相应地这一影响会更加严重,虽然一些方法[6][7][8]设置了后处理流程进行OCR纠错,但这些方案在落地应用中会增加整个系统的开销,实际意义不大。
本文提出的Donut模型摆脱了对OCR结果的依赖,采用端到端的方式直接生成结果字符串,避免了上节中提到的问题。其结构如图1所示。模型结构非常简单,其输入为文档图像,经编码器模块得到特征序列,随后通过基于Transformer的解码器生成结果字符串。
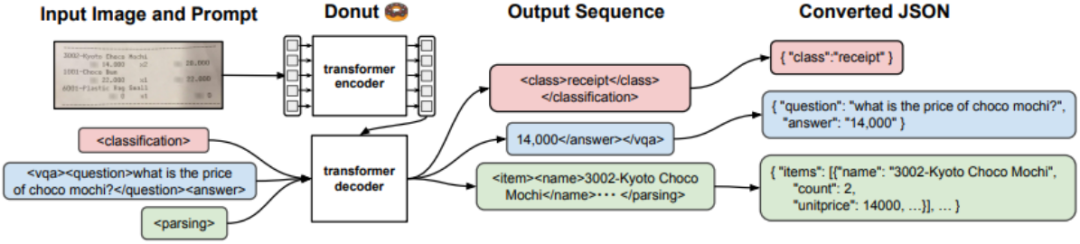 图1 Donut流程图
图1 Donut流程图内容中包含的图片若涉及版权问题,请及时与我们联系删除



评论
沙发等你来抢