
来自今天的爱可可AI前沿推介
[CV] SDFusion: Multimodal 3D Shape Completion, Reconstruction, and Generation
Y Cheng, H Lee, S Tulyakov, A Schwing, L Gui
[University of Illinois Urbana-Champaign & Snap Research]
SDFusion: 多模态3D形状补全、重建和生成
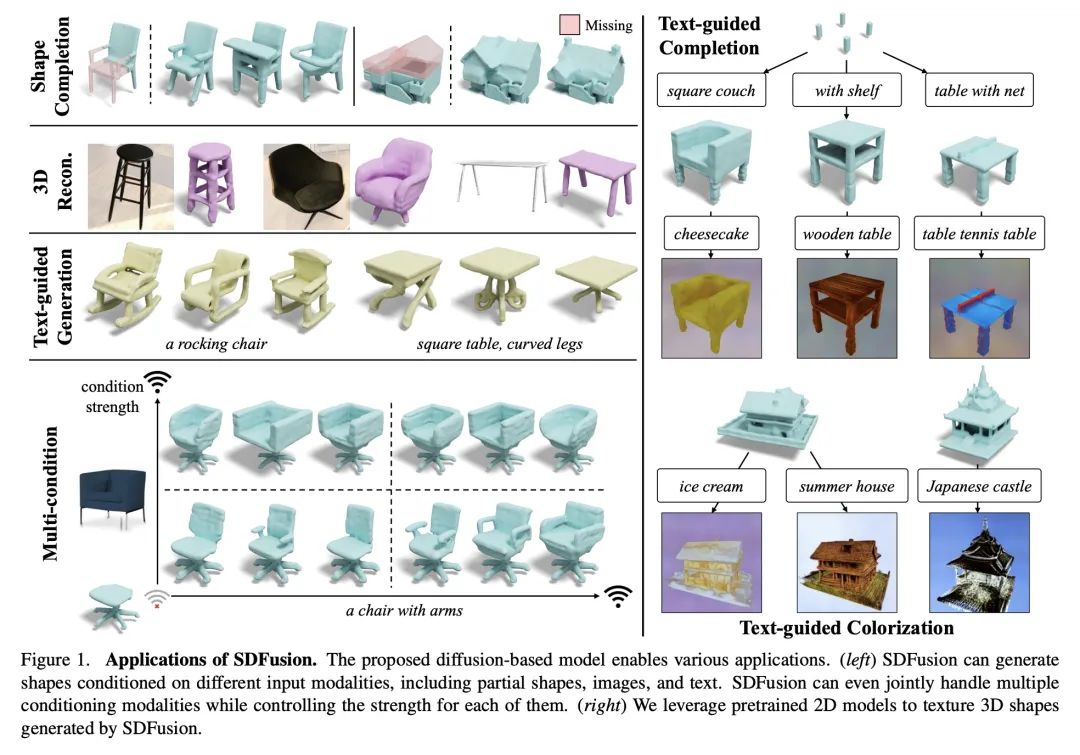
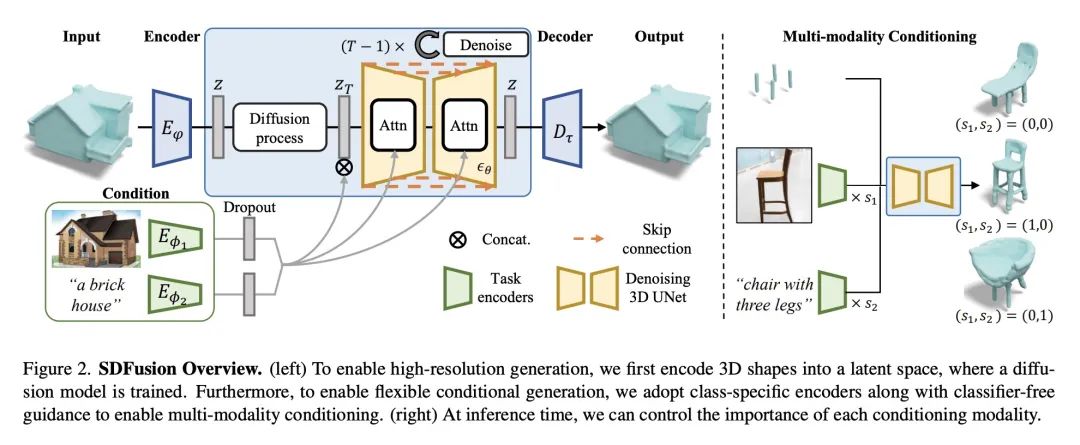
提出SDFusion,一种通过结合图像、文本和观察到形状等多种模态输入,为业余用户生成3D形状的框架,其核心是一个编-解码器,将3D形状压缩成一种潜表示,可用于训练扩散模型。结果显示,SDFusion优于之前的工作,可同时用不完整形状、图像和文本描述来生成形状,生成的形状可以用2D文本-图像模型进行纹理处理。
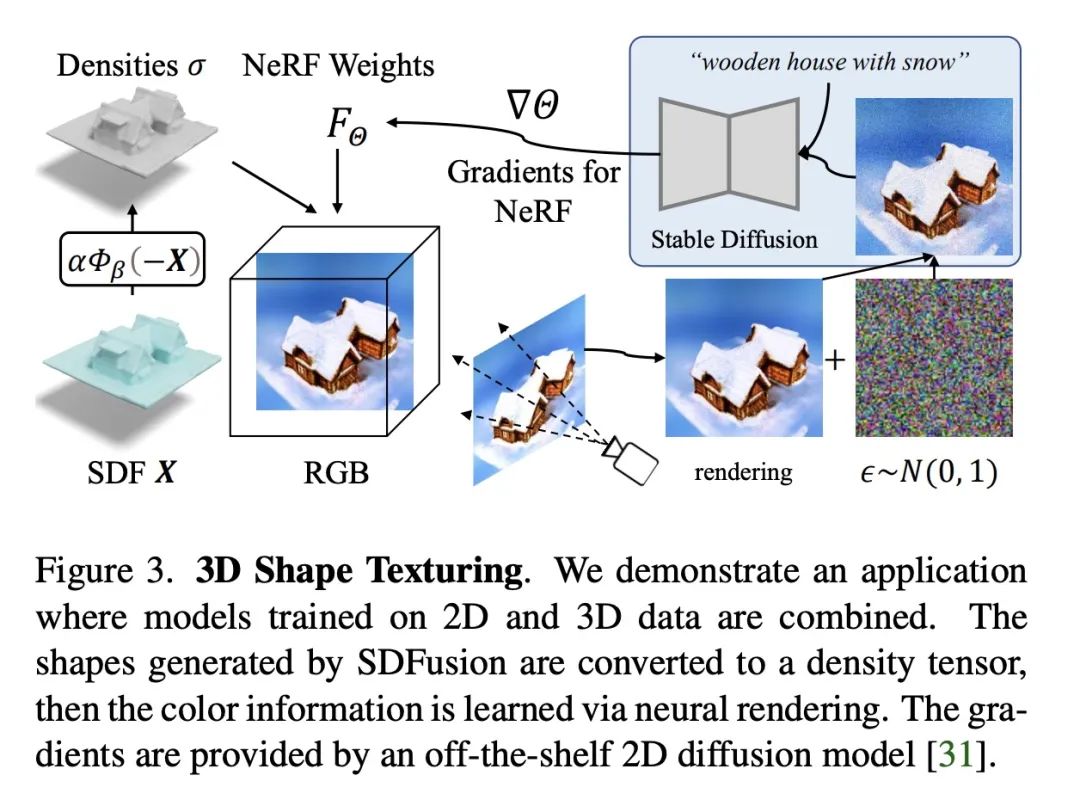
本文提出一种新框架,为业余用户简化了3D资产的生成。为了实现交互式生成,所提出方法支持各种可由人轻松提供的输入模态,包括图像、文本、部分观察到的形状和以上的组合,并进一步允许调整每种输入的强度。该方法的核心是一个编-解码器,将3D形状压缩成一个紧凑的潜表示,在此基础上学习扩散模型。为了使各种多模态输入成为可能,采用了特定任务的编码器,在交叉注意力机制基础上dropout。由于其灵活性,该模型自然地支持各种任务,在形状补全、基于图像的3D重建和文本-3D方面的表现优于之前的工作。该模型可以将所有这些任务结合到一个瑞士军刀工具中,使用户能同时使用不完全形状、图像和文字描述进行形状生成,为每个输入提供相对权重并促进交互。本文进一步展示了一种有效的方法,用大规模的文本-图像模型对生成的形状进行纹理处理。
论文地址 https://arxiv.org/abs/2212.04493
In this work, we present a novel framework built to simplify 3D asset generation for amateur users. To enable interactive generation, our method supports a variety of input modalities that can be easily provided by a human, including images, text, partially observed shapes and combinations of these, further allowing to adjust the strength of each input. At the core of our approach is an encoder-decoder, compressing 3D shapes into a compact latent representation, upon which a diffusion model is learned. To enable a variety of multi-modal inputs, we employ task-specific encoders with dropout followed by a cross-attention mechanism. Due to its flexibility, our model naturally supports a variety of tasks, outperforming prior works on shape completion, image-based 3D reconstruction, and text-to-3D. Most interestingly, our model can combine all these tasks into one swiss-army-knife tool, enabling the user to perform shape generation using incomplete shapes, images, and textual descriptions at the same time, providing the relative weights for each input and facilitating interactivity. Despite our approach being shape-only, we further show an efficient method to texture the generated shape using large-scale text-to-image models.

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢