

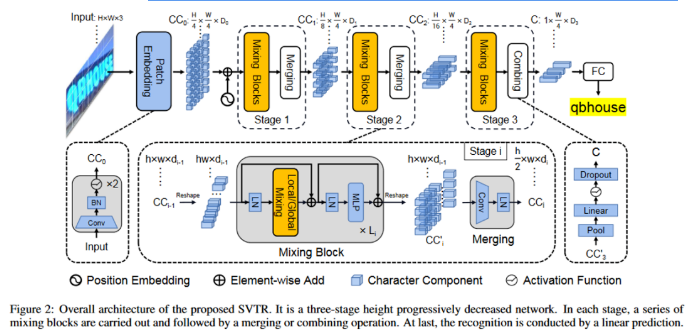
本文简要介绍IJCAI2022论文“SVTR: Scene Text Recognition with a Single Visual Model”的主要工作。主流的场景文字识别算法通常包含两个模块,即用以提取特征的视觉模块(如CNN,MHSA),以及用于输出文本的序列模块(如RNN,Attention)。本文提出了一个只由视觉模块构成的模型SVTR,在中英文场景文字识别上都取得了较好效果,并且推理速度较快。
开源地址: https://github.com/PaddlePaddle/PaddleOCR
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢