
来自今天的爱可可AI前沿推介
[CV] M-VADER: A Model for Diffusion with Multimodal Context
S Weinbach, M Bellagente, C Eichenberg, A Dai, R Baldock, S Nanda, B Deiseroth, K Oostermeijer, H Teufel, A F Cruz-Salinas
[Aleph Alpha GmbH]
M-VADER:多模态上下文扩散模型
简介:提出一种具有多模态上下文的扩散模型M-VADER,一个130亿参数的多模态解码器,结合了自回归视觉语言模型MAGMA的组件和为语义搜索微调的偏差,能用多模态上下文(例如来自图像、文本和图像组合的信号)引导图像生成。
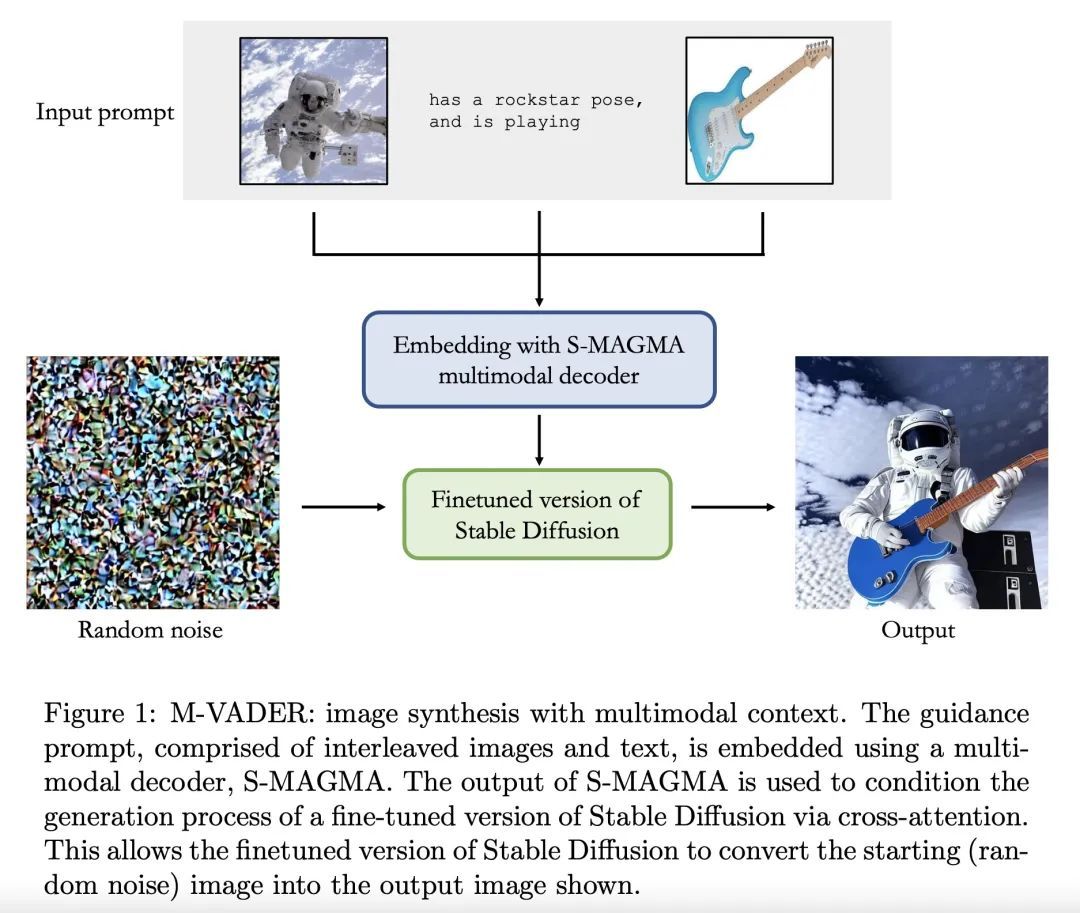
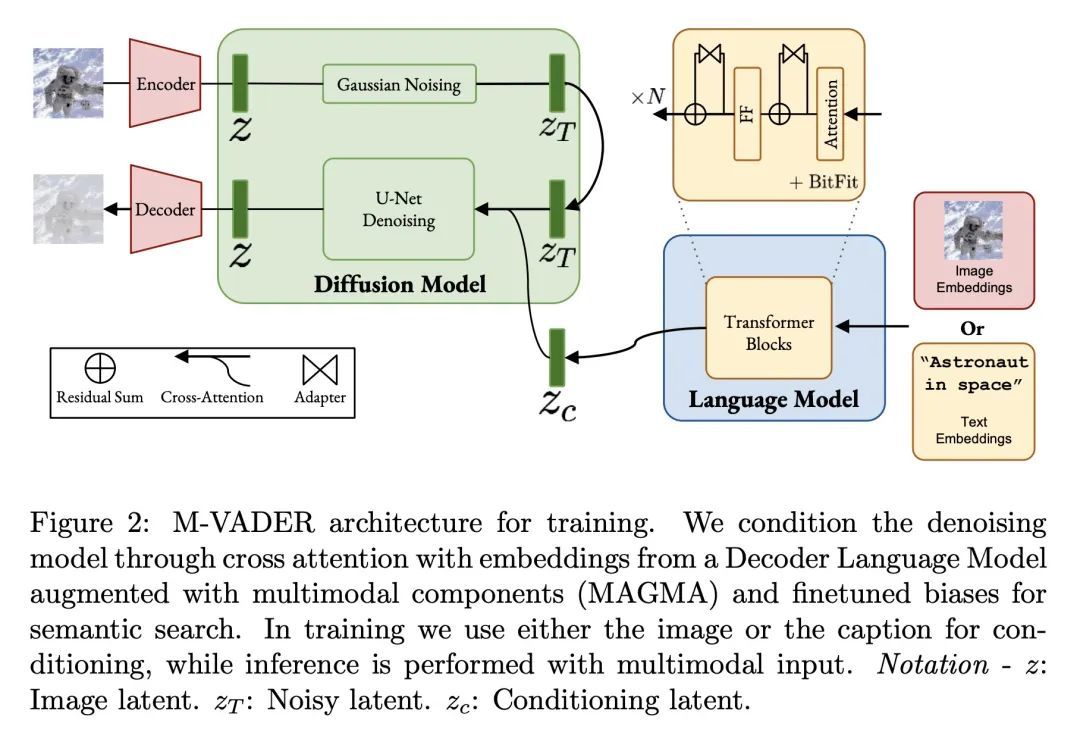
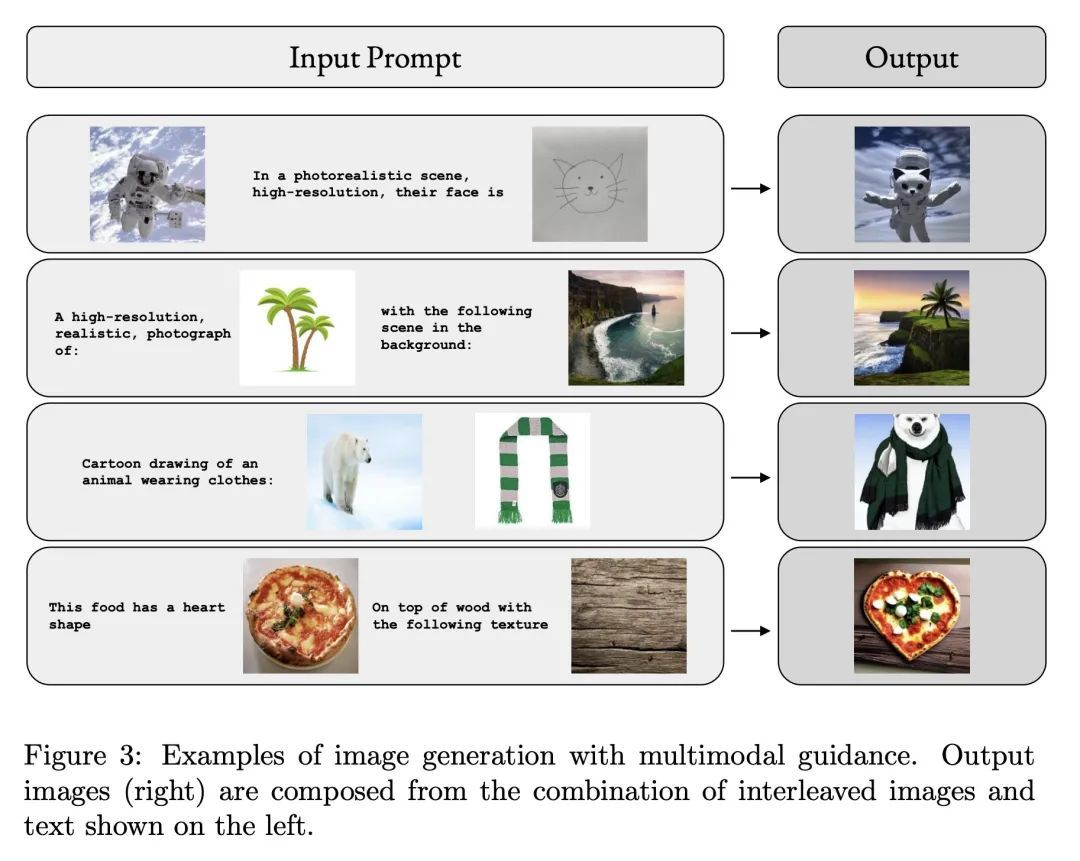
摘要:本文提出M-VADER:一种用于图像生成的扩散模型(DM),可以用图像和文本的任意组合来指定输出。本文展示了M-VADER如何用图像和文本的组合以及多个图像的组合来生成指定的图像。此前,已经有了一些成功的扩散模型图像生成算法,使得用文本提示指定输出图像成为可能。受这些模型成功的启发,并在语言已经被开发用来描述人类认为最重要的视觉上下文元素的概念的引导下,本文提出一个与视觉语言模型密切相关的嵌入模型S-MAGMA:一个 130 亿参数的多模态解码器,结合了自回归视觉语言模型MAGMA的组件和为语义搜索微调的偏差。
We introduce M-VADER: a diffusion model (DM) for image generation where the output can be specified using arbitrary combinations of images and text. We show how M-VADER enables the generation of images specified using combinations of image and text, and combinations of multiple images. Previously, a number of successful DM image generation algorithms have been introduced that make it possible to specify the output image using a text prompt. Inspired by the success of those models, and led by the notion that language was already developed to describe the elements of visual contexts that humans find most important, we introduce an embedding model closely related to a vision-language model. Specifically, we introduce the embedding model S-MAGMA: a 13 billion parameter multimodal decoder combining components from an autoregressive vision-language model MAGMA and biases finetuned for semantic search.
论文链接:https://arxiv.org/abs/2212.02936

内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢