

论文链接:
https://arxiv.org/pdf/2111.10962.pdf
数据代码:
https://github.com/ntunlp/kmlm.git
导读
跨语言预训练模型(如 XLM-R)的出现,使很多低资源语种的 NLP 任务处理从不可能变为可能。具体做法是以跨语言预训练模型作为编码器,用目标任务的源语言(通常是英语)训练集训练模型后,直接在低资源目标语种的测试数据上进行预测,即 Zero-shot Learning。
为了进一步增强预训练模型的跨语言能力,并缓解低资源语种预训练语料较少而导致的知识覆盖不足问题,我们提出了多语言知识增强的预训练模型 KMLM。充分的实验表明,KMLM 在若干跨语言任务上(如实体识别,知识抽取,实体关系分类)取得了稳定的效果提升。
跨语言任务的另外一类主流解法是将训练数据从源语言翻译到目标语言,构成目标语言的训练集并训练模型,即 Translate-train。对于细粒度任务(如NER),标签映射是 Translate-train 需要解决的一个难题。
为了缓解标签映射问题并利用目标语言的无标注数据,我们提出了免映射的训练数据翻译方法以及跨语言 NER 的一致性训练方法 ConNER。ConNER 能够利用目标语言无标注数据的丰富知识,并缓解对源语言数据的过拟合,以达到更好的跨语言表现。
贡献
近年来在大型预训练语言模型上进行微调已经成为自然语言处理任务中最常用的方法之一,该方法在众多任务中都取得了优异的表现。然而预训练模型在知识密集的任务的表现上仍然有进一步提高的空间,所以最近有很多知识增强的语言模型被提出来 [1,2]。
然而现有的知识增强的语言模型大部分是单一语言的,限制了它们在更多语言上的应用。同时,很多现有的知识增强方法会使用额外的 entity/relation embedding [3,4],或者知识图谱编码器 [2] 来辅助语言模型学习,这样会增加模型的参数量并限制其在下游任务应用的灵活性。此外,这些预训练的模型更多地强调知识的记忆,而逻辑推理能力没有得到足够的重视。
针对上面指出的几个问题,我们提出新的方法,通过知识图谱中的数据来生成大量的多语种训练数据,并使用它们直接训练语言模型。我们生成的训练数据包括 Code-Switched/Parallel Synthetic Sentences 和 Reasoning-Based Training Data。
然后,我们设计知识相关的训练任务, 包括基于多语言知识语料的训练任务(Multilingual Knowledge Oriented Pretraining),和基于逻辑推理的训练任务(Logical Reasoning Oriented Pretraining),来增强多语种预训练语言模型。
方法
知识图谱数据库通常使用三元组(h, r, t)来描述实体之间的关系,其中 h 和 t 分别是头实体和尾实体,r 用来描述二者的关系。如表格 1 所示,知识图谱数据库 Wikidata 中有大量多语种标注的信息,很多实体和关系也提供了大量

如图表 2 所示,我们可以通过使用多语种标注和别名来替换三元组里面的实体和关系,并用 [mask] 来连接它们,从而生成大量的知识密集的多语言语言训练数据:Code-Switched/Parallel Synthetic Sentences 。

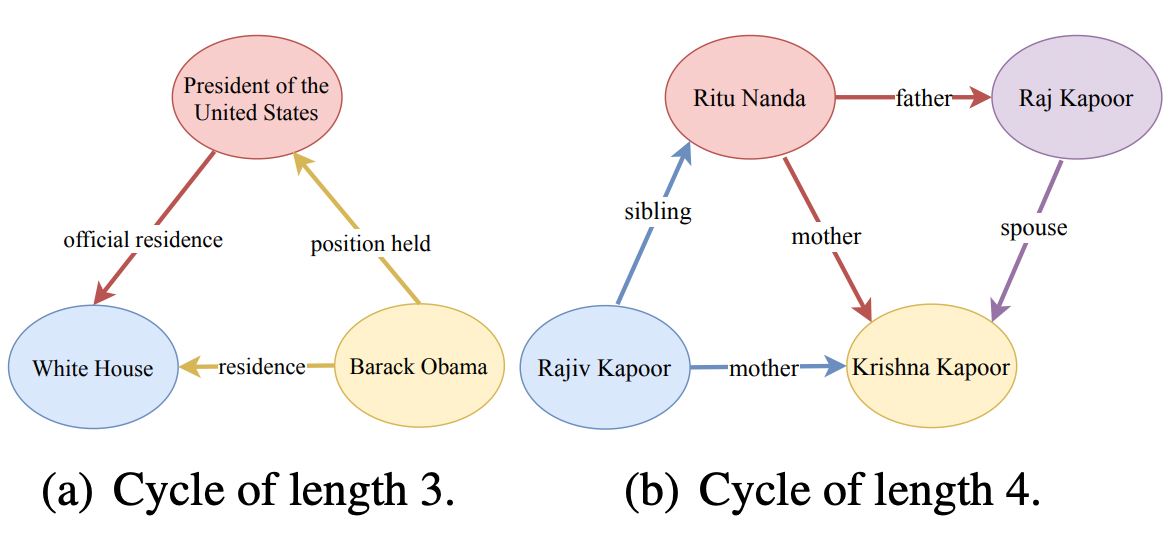
除此之外,我们还在知识图谱中抽取大量长度为三和长度为四的环,并用它们生成逻辑推理训练数据 (Reasoning-Based Training Data)。抽取的环如图表 3 所示。我们发现增加环的长度,会生成一些没有逻辑关系的环,所以我们要求长度为四的环中间有至少一条边连接对角的两个节点。这些环也是由知识三元组构成,所以我们也可以通过插入 [mask] 来生成训练数据,如图表 4 所示。

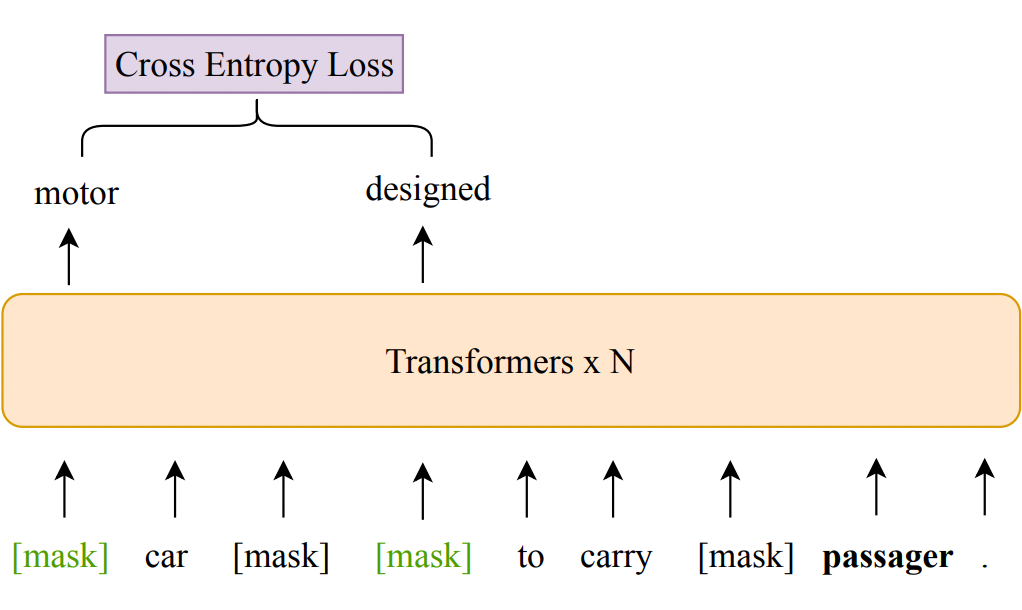
生成好训练数据后,我们设计了两个预训练任务:基于多语言知识语料的训练任务,和基于逻辑推理的训练任务。其中基于多语言知识语料的训练任务与常见的 Masked Language Modeling 任务相近,但是区别是我们的训练语料中用 [mask] 来连接实体和关系,这些 [mask] 对应的连接词我们并不知道。所以在训练模型时,我们只用实体和关系对应的 token 预测计算交叉熵损失,如图表 5 所示。
对于基于逻辑推理的训练任务,我们为长度为 3 和 4 的环分别设计训练任务。如上所述,每个环能够生成对应的一段话,图表 4 给出了两个例子。对于长度为 3 的环,我们随机掩盖掉其中一句话的关系,并训练模型根据句子中的其他关系和实体来预测掩盖掉的词。
对于长度为 4 的环,我们设计了两个子任务:
-
对于 80% 的情况,我们随机选择一句话并掩盖掉里面的关系。同时为了增加难度,我们还会随机掩盖掉这段话中的一到两个实体。然后训练模型预测掩盖掉的实体和关系。
-
对于 20% 的情况,我们随机掩盖掉一句话,让模型学习能否从其他句子里推断出新的知识。我们保留选中那一句话里面的关系作为提示。
除了上面介绍的两个预训练任务,我们还加入了常见 Masked Language Modeling 任务 [5] 来学习自然语句中词的分布。为了使用这三个任务同时来训练模型,我们将它们对应的损失函数加在一起作为最终的损失函数来使用,如下面公式所示。其中等号右面的三个损失函数分别对应 Masked Language Modeling 任务,基于多语言知识语料的训练任务和基于逻辑推理的训练任务。是一个参数来调整后两项知识相关任务的权重。
\( \mathcal{L}=\mathcal{L}_{M L M}+\alpha\left(\mathcal{L}_{K}+\mathcal{L}_{L}\right) \)
实验
我们使用上面提到的训练数据和任务预训练了多个模型实验证明,模型下标 CS, Parallel,Mix 用来区分使用 code-switched, parallel 以及二者结合所训练的模型。跨语言实验中,我们在英文数据训练集上训练模型,然后在其他语言的测试集上测试。我们的模型在多语言命名实体识别,知识抽取,实体关系分类,逻辑推理等任务上都取得了显著的表现提升。
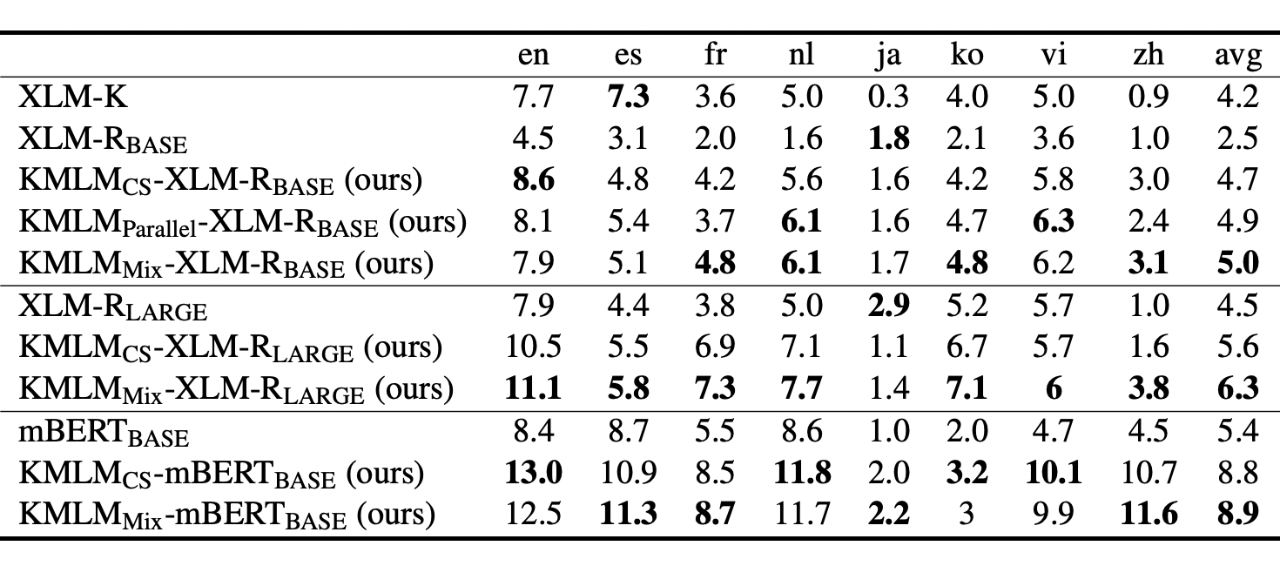
命名实体识别(NER)包括从非结构化文本数据中识别和分类命名实体。避免对实体/关系 embedding 的依赖允许我们的模型直接在大量实体上进行训练,而无需添加额外的参数或增加计算成本。在实体密集型的训练数据上的直接训练也可能有助于更有效地提高实体表示。
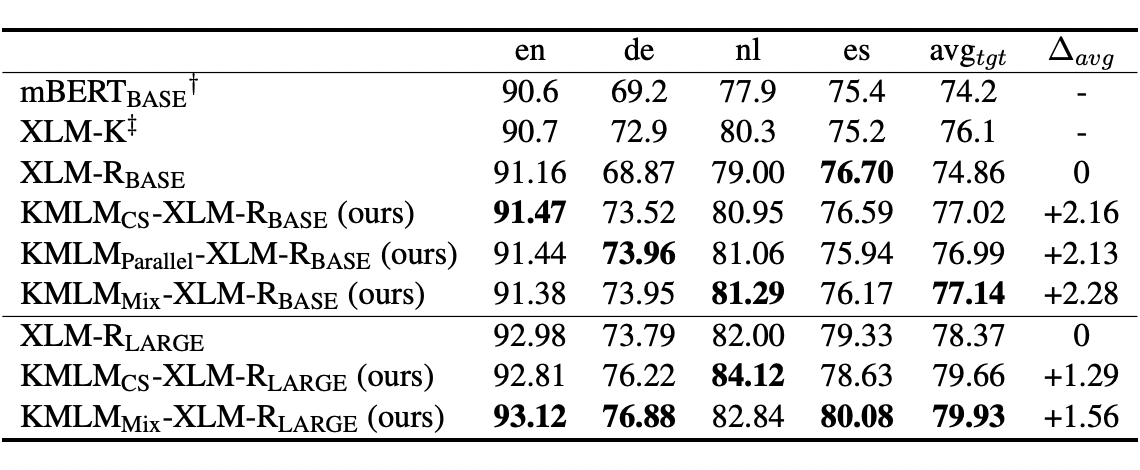
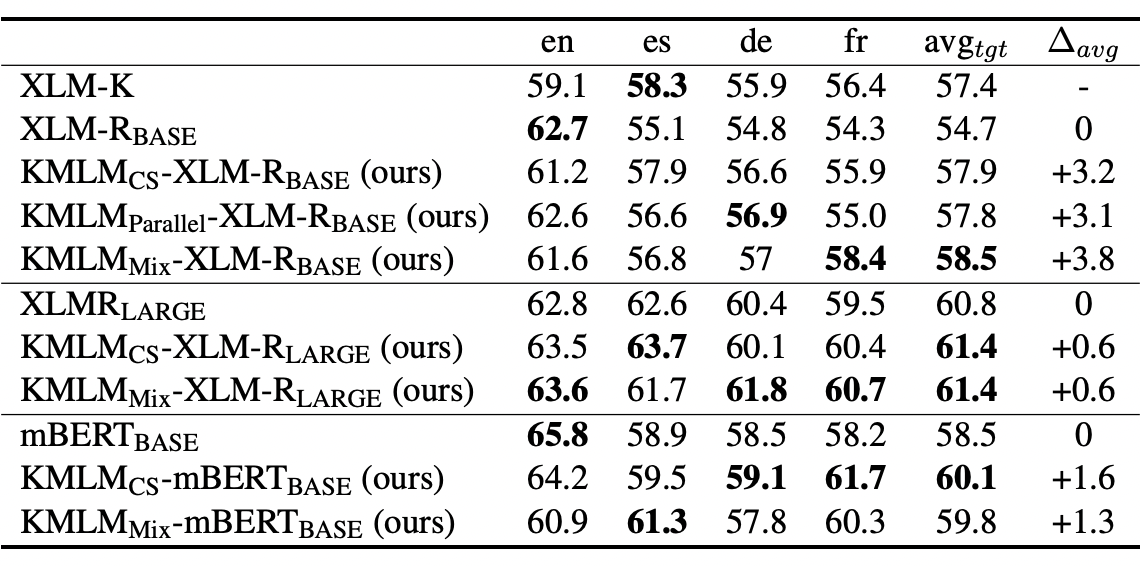
我们使用 CoNLL02/03 和 WikiAnn 命名实体识别数据集对模型来测试我们的方法对于实体表示的学习的影响,结果如图表 6 和图表 7 所示。我们的方法相比于基准方法有稳定的表现提升。其中 base 和 large 版本的 mix 模型(使用 code-switched 与 parallel 数据一起训练的模型)均取得了最优的表现,体现出结合这两种数据集的优势。
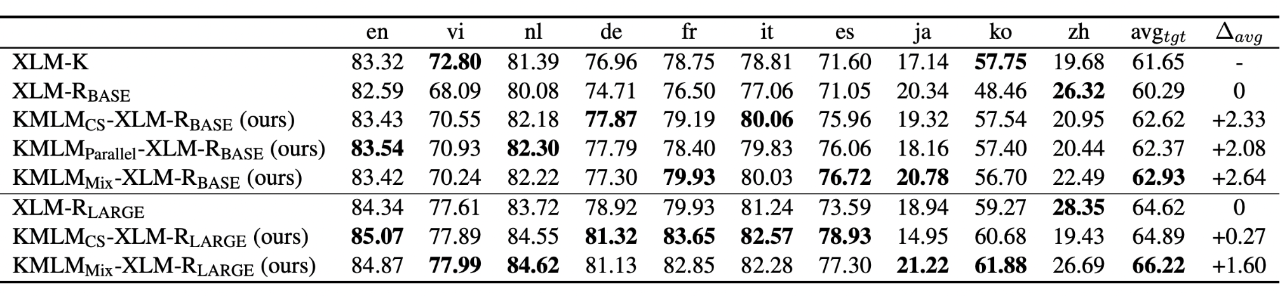
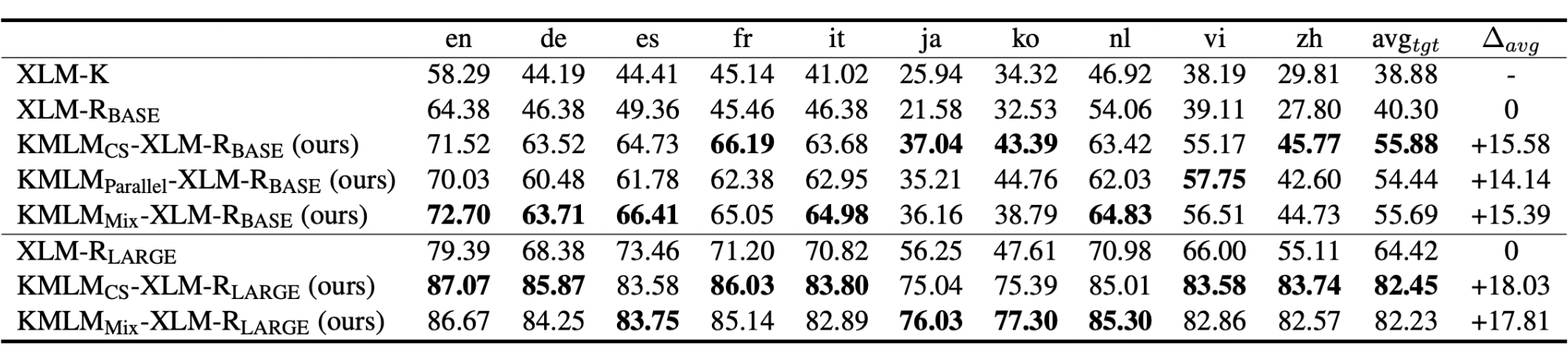
除命名实体识别之外,我们还在一个多语言知识抽取任务和一个跨语言实体关系分类任务上分别测试我们的方法对于事实知识记忆,和实体关系表示学习的影响。如图表 8 和 9 中的结果所示,我们的方法也是体现出了明显的表现提升。通过不同知识相关任务上的测试,可以看出来我们的方法能够帮助知识记忆的效率。
为了验证我们的方法对逻辑推理任务的有效性,我们提出了多选题形式的跨语言逻辑推理(XLR)任务。这种推理任务的一个例子在图 10 中给出。这些模型先在英语训练集上微调,然后在不同目标语言的测试集上测试。结果如表 11 所示。我们所有的模型都显著优于基准模型。由此可见,我们的这种预训练方法可以帮助语言模型更好地学习常见的逻辑推理模式,以提高其在下游任务的表现。

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢