
作者:Mohammad Fahes、Tuan-Hung Vu、Andrei Bursuc、等
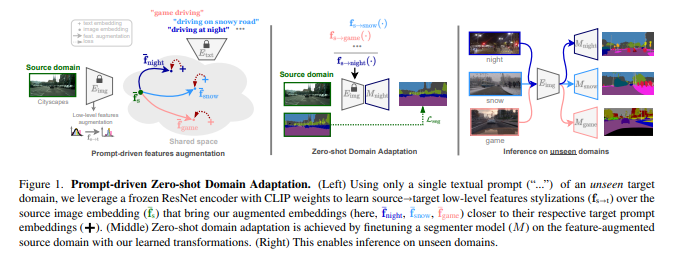
简介:本文研究基于CLIP模型强大的零样本能力、利用Prompt进行领域自适应。域适应已在计算机视觉中得到广泛研究,但仍然需要在训练时访问目标图像,这在某些情况下可能很棘手,尤其是对于长尾样本。在本文中,作者提出了“提示驱动的零样本域适应”任务,作者仅使用目标域的一般文本描述(即提示)来调整在源域上训练的模型。首先,作者利用预训练的对比视觉语言模型 (CLIP) 来优化源特征的仿射变换,使它们更接近目标文本嵌入,同时保留它们的内容和语义。其次,作者表明增强特征可用于执行语义分割的零样本域自适应。实验表明:对于当前的下游任务,作者的方法在多个数据集上明显优于基于 CLIP 的风格迁移基线。作者的提示驱动方法在某些数据集上的表现甚至优于一次性无监督域适应,并在其他数据集上给出了可比的结果。
论文下载:https://arxiv.org/pdf/2212.03241.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢